 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019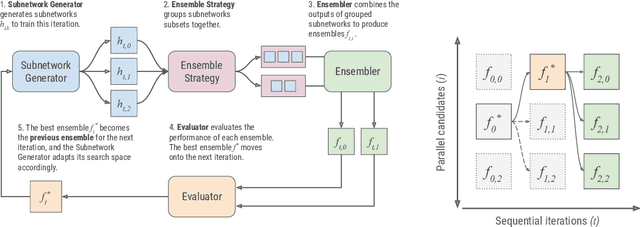
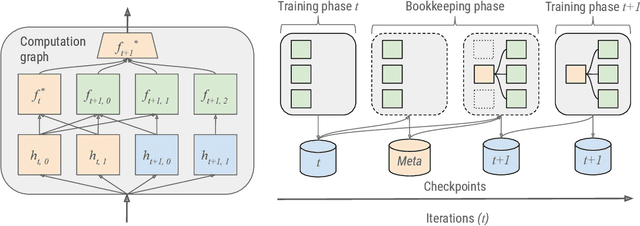
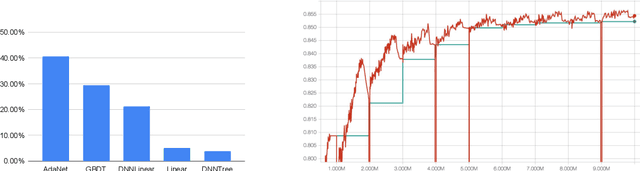
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.
Online Non-Additive Path Learning under Full and Partial Information
Sep 18, 2018
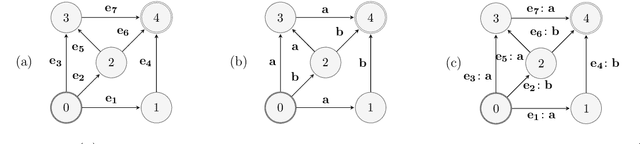
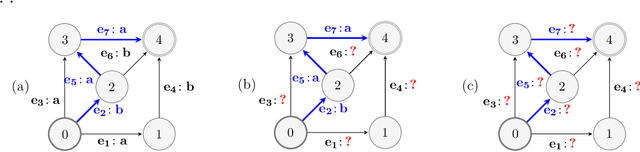

We study the problem of online path learning with non-additive gains, which is a central problem appearing in several applications, including ensemble structured prediction. We present new online algorithms for path learning with non-additive count-based gains for the three settings of full information, semi-bandit and full bandit. These algorithms admit very favorable regret guarantees and their guarantees can be viewed as the non-additive counterparts to the best known guarantees in the additive case. A key component of our algorithms is the definition and computation of an intermediate context-dependent automaton that enables us to use existing algorithms designed for additive gains. We further apply our methods to the important application of ensemble structured prediction. Finally, beyond count-based gains, we give an efficient implementation of the EXP3 algorithm for the full bandit setting with an arbitrary (non-additive) gain.
Foundations of Sequence-to-Sequence Modeling for Time Series
May 09, 2018
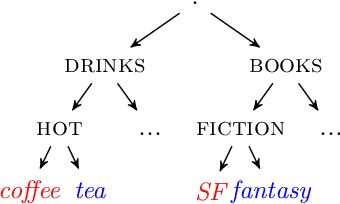
The availability of large amounts of time series data, paired with the performance of deep-learning algorithms on a broad class of problems, has recently led to significant interest in the use of sequence-to-sequence models for time series forecasting. We provide the first theoretical analysis of this time series forecasting framework. We include a comparison of sequence-to-sequence modeling to classical time series models, and as such our theory can serve as a quantitative guide for practitioners choosing between different modeling methodologies.
Theory and Algorithms for Forecasting Time Series
Mar 15, 2018
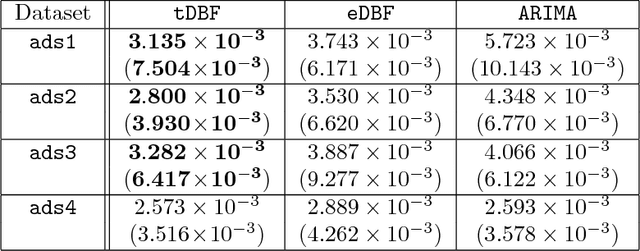
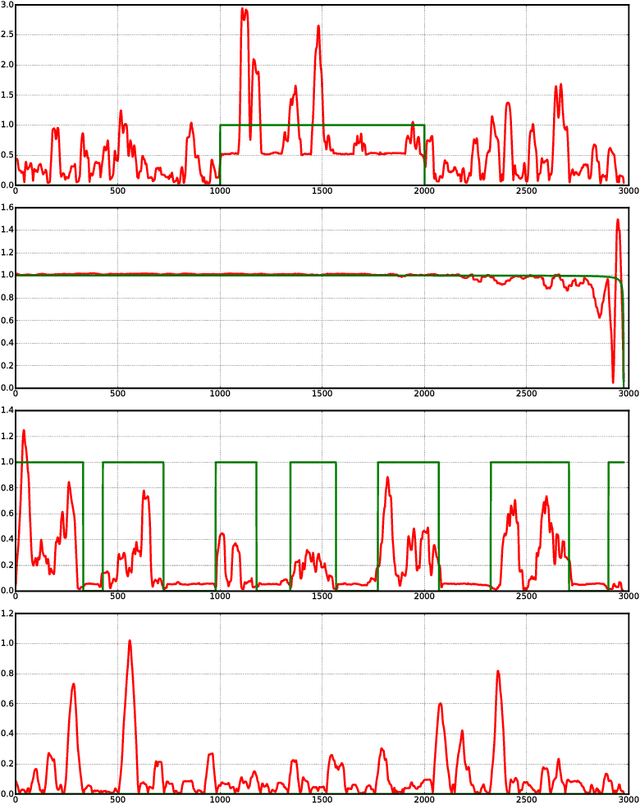

We present data-dependent learning bounds for the general scenario of non-stationary non-mixing stochastic processes. Our learning guarantees are expressed in terms of a data-dependent measure of sequential complexity and a discrepancy measure that can be estimated from data under some mild assumptions. We also also provide novel analysis of stable time series forecasting algorithm using this new notion of discrepancy that we introduce. We use our learning bounds to devise new algorithms for non-stationary time series forecasting for which we report some preliminary experimental results.
Discrepancy-Based Algorithms for Non-Stationary Rested Bandits
Feb 27, 2018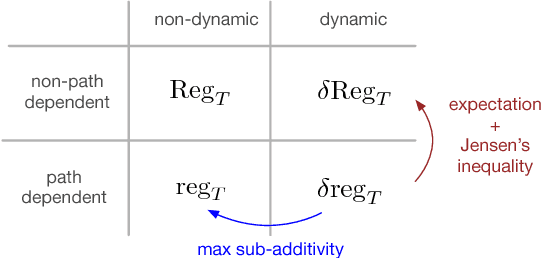
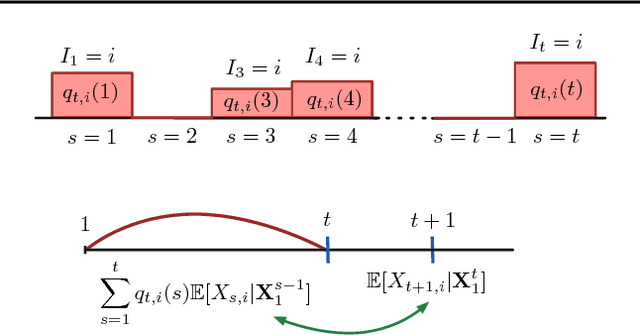
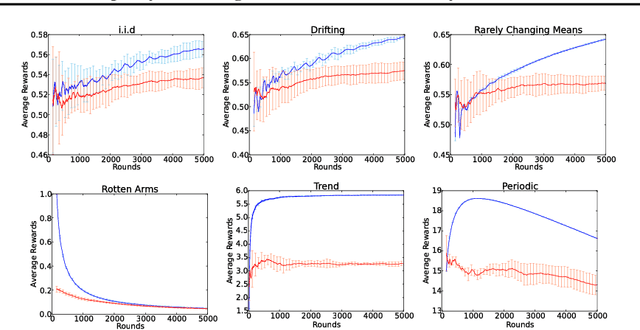
We study the multi-armed bandit problem where the rewards are realizations of general non-stationary stochastic processes, a setting that generalizes many existing lines of work and analyses. In particular, we present a theoretical analysis and derive regret guarantees for rested bandits in which the reward distribution of each arm changes only when we pull that arm. Remarkably, our regret bounds are logarithmic in the number of rounds under several natural conditions. We introduce a new algorithm based on classical UCB ideas combined with the notion of weighted discrepancy, a useful tool for measuring the non-stationarity of a stochastic process. We show that the notion of discrepancy can be used to design very general algorithms and a unified framework for the analysis of multi-armed rested bandit problems with non-stationary rewards. In particular, we show that we can recover the regret guarantees of many specific instances of bandit problems with non-stationary rewards that have been studied in the literature. We also provide experiments demonstrating that our algorithms can enjoy a significant improvement in practice compared to standard benchmarks.
AdaNet: Adaptive Structural Learning of Artificial Neural Networks
Feb 28, 2017
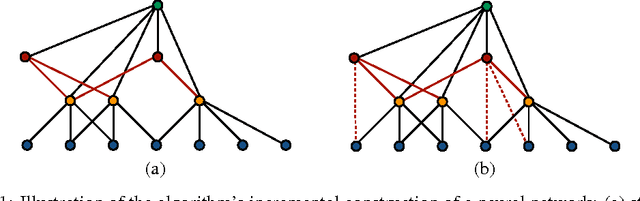

We present new algorithms for adaptively learning artificial neural networks. Our algorithms (AdaNet) adaptively learn both the structure of the network and its weights. They are based on a solid theoretical analysis, including data-dependent generalization guarantees that we prove and discuss in detail. We report the results of large-scale experiments with one of our algorithms on several binary classification tasks extracted from the CIFAR-10 dataset. The results demonstrate that our algorithm can automatically learn network structures with very competitive performance accuracies when compared with those achieved for neural networks found by standard approaches.
Structured Prediction Theory Based on Factor Graph Complexity
Dec 01, 2016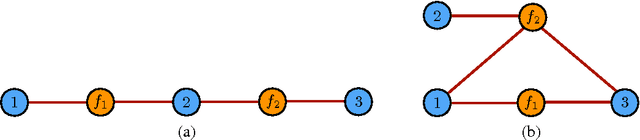
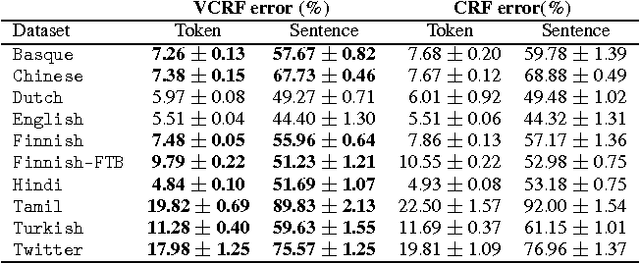
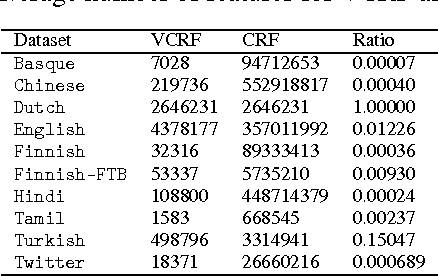
We present a general theoretical analysis of structured prediction with a series of new results. We give new data-dependent margin guarantees for structured prediction for a very wide family of loss functions and a general family of hypotheses, with an arbitrary factor graph decomposition. These are the tightest margin bounds known for both standard multi-class and general structured prediction problems. Our guarantees are expressed in terms of a data-dependent complexity measure, factor graph complexity, which we show can be estimated from data and bounded in terms of familiar quantities. We further extend our theory by leveraging the principle of Voted Risk Minimization (VRM) and show that learning is possible even with complex factor graphs. We present new learning bounds for this advanced setting, which we use to design two new algorithms, Voted Conditional Random Field (VCRF) and Voted Structured Boosting (StructBoost). These algorithms can make use of complex features and factor graphs and yet benefit from favorable learning guarantees. We also report the results of experiments with VCRF on several datasets to validate our theory.
Voted Kernel Regularization
Sep 14, 2015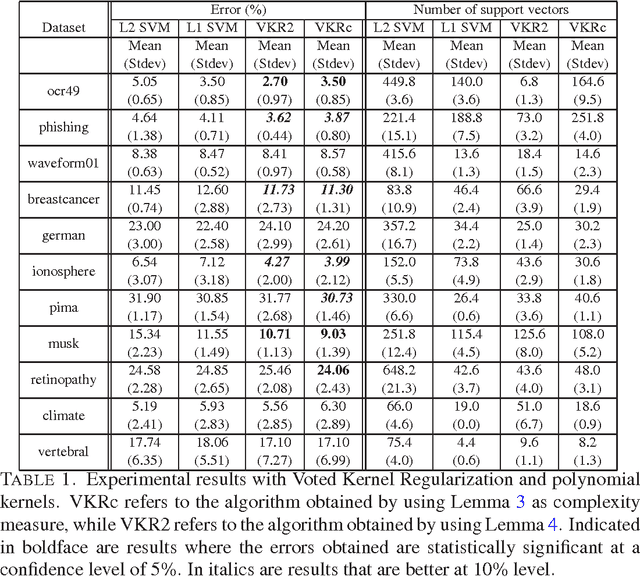
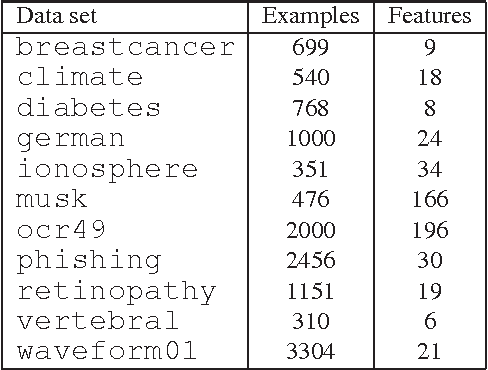
This paper presents an algorithm, Voted Kernel Regularization , that provides the flexibility of using potentially very complex kernel functions such as predictors based on much higher-degree polynomial kernels, while benefitting from strong learning guarantees. The success of our algorithm arises from derived bounds that suggest a new regularization penalty in terms of the Rademacher complexities of the corresponding families of kernel maps. In a series of experiments we demonstrate the improved performance of our algorithm as compared to baselines. Furthermore, the algorithm enjoys several favorable properties. The optimization problem is convex, it allows for learning with non-PDS kernels, and the solutions are highly sparse, resulting in improved classification speed and memory requirements.