 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrow, Don't Overwrite: Fine-tuning Without Forgetting
Mar 09, 2026Adapting pre-trained models to specialized tasks often leads to catastrophic forgetting, where new knowledge overwrites foundational capabilities. Existing methods either compromise performance on the new task or struggle to balance training stability with efficient reuse of pre-trained knowledge. We introduce a novel function-preserving expansion method that resolves this dilemma. Our technique expands model capacity by replicating pre-trained parameters within transformer submodules and applying a scaling correction that guarantees the expanded model is mathematically identical to the original at initialization, enabling stable training while exploiting existing knowledge. Empirically, our method eliminates the trade-off between plasticity and stability, matching the performance of full fine-tuning on downstream tasks without any degradation of the model's original capabilities. Furthermore, we demonstrate the modularity of our approach, showing that by selectively expanding a small subset of layers we can achieve the same performance as full fine-tuning at a fraction of the computational cost.
Learning by solving differential equations
May 19, 2025


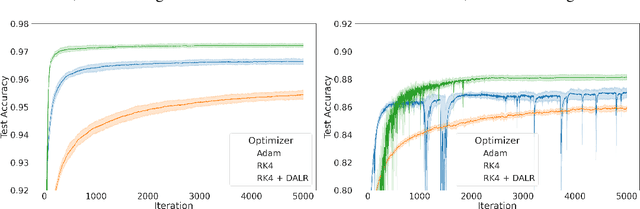
Modern deep learning algorithms use variations of gradient descent as their main learning methods. Gradient descent can be understood as the simplest Ordinary Differential Equation (ODE) solver; namely, the Euler method applied to the gradient flow differential equation. Since Euler, many ODE solvers have been devised that follow the gradient flow equation more precisely and more stably. Runge-Kutta (RK) methods provide a family of very powerful explicit and implicit high-order ODE solvers. However, these higher-order solvers have not found wide application in deep learning so far. In this work, we evaluate the performance of higher-order RK solvers when applied in deep learning, study their limitations, and propose ways to overcome these drawbacks. In particular, we explore how to improve their performance by naturally incorporating key ingredients of modern neural network optimizers such as preconditioning, adaptive learning rates, and momentum.
Training in reverse: How iteration order influences convergence and stability in deep learning
Feb 03, 2025
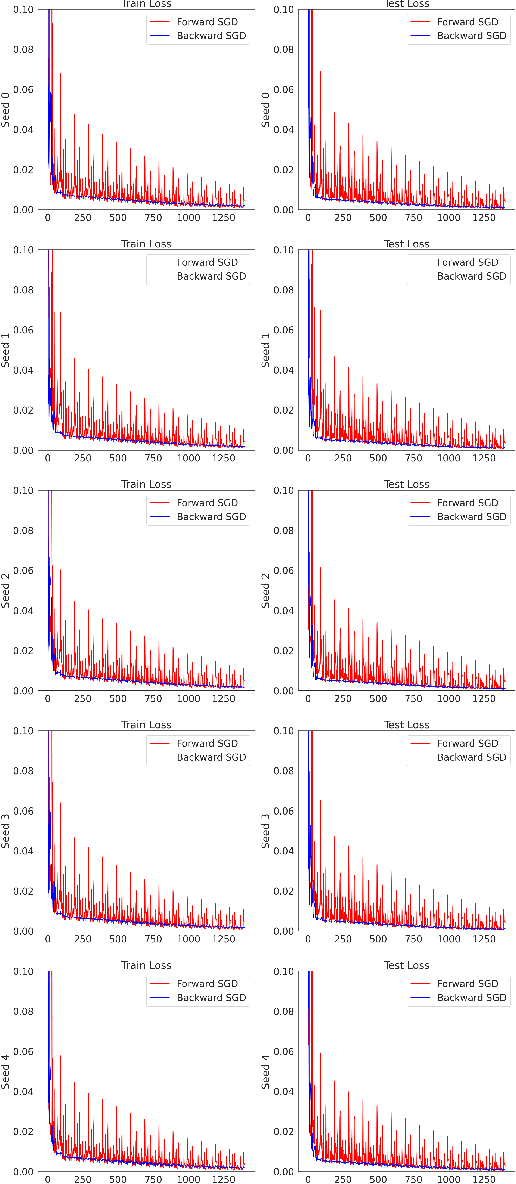


Despite exceptional achievements, training neural networks remains computationally expensive and is often plagued by instabilities that can degrade convergence. While learning rate schedules can help mitigate these issues, finding optimal schedules is time-consuming and resource-intensive. This work explores theoretical issues concerning training stability in the constant-learning-rate (i.e., without schedule) and small-batch-size regime. Surprisingly, we show that the order of gradient updates affects stability and convergence in gradient-based optimizers. We illustrate this new line of thinking using backward-SGD, which processes batch gradient updates like SGD but in reverse order. Our theoretical analysis shows that in contractive regions (e.g., around minima) backward-SGD converges to a point while the standard forward-SGD generally only converges to a distribution. This leads to improved stability and convergence which we demonstrate experimentally. While full backward-SGD is computationally intensive in practice, it highlights opportunities to exploit reverse training dynamics (or more generally alternate iteration orders) to improve training. To our knowledge, this represents a new and unexplored avenue in deep learning optimization.
Simulated Overparameterization
Feb 07, 2024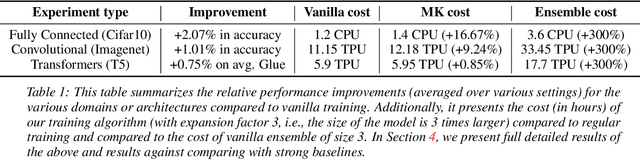
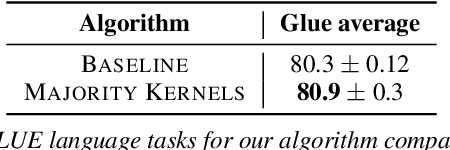

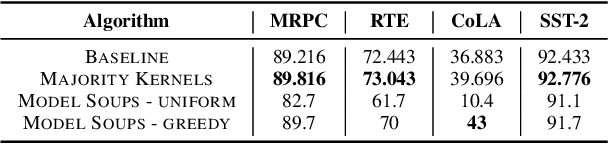
In this work, we introduce a novel paradigm called Simulated Overparametrization (SOP). SOP merges the computational efficiency of compact models with the advanced learning proficiencies of overparameterized models. SOP proposes a unique approach to model training and inference, where a model with a significantly larger number of parameters is trained in such a way that a smaller, efficient subset of these parameters is used for the actual computation during inference. Building upon this framework, we present a novel, architecture agnostic algorithm called "majority kernels", which seamlessly integrates with predominant architectures, including Transformer models. Majority kernels enables the simulated training of overparameterized models, resulting in performance gains across architectures and tasks. Furthermore, our approach adds minimal overhead to the cost incurred (wall clock time) at training time. The proposed approach shows strong performance on a wide variety of datasets and models, even outperforming strong baselines such as combinatorial optimization methods based on submodular optimization.
Deep Fusion: Efficient Network Training via Pre-trained Initializations
Jun 20, 2023



In recent years, deep learning has made remarkable progress in a wide range of domains, with a particularly notable impact on natural language processing tasks. One of the challenges associated with training deep neural networks is the need for large amounts of computational resources and time. In this paper, we present Deep Fusion, an efficient approach to network training that leverages pre-trained initializations of smaller networks. % We show that Deep Fusion accelerates the training process, reduces computational requirements, and leads to improved generalization performance on a variety of NLP tasks and T5 model sizes. % Our experiments demonstrate that Deep Fusion is a practical and effective approach to reduce the training time and resource consumption while maintaining, or even surpassing, the performance of traditional training methods.
Towards Task and Architecture-Independent Generalization Gap Predictors
Jun 04, 2019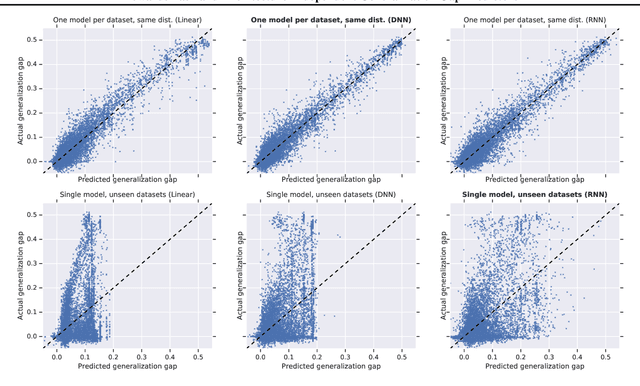

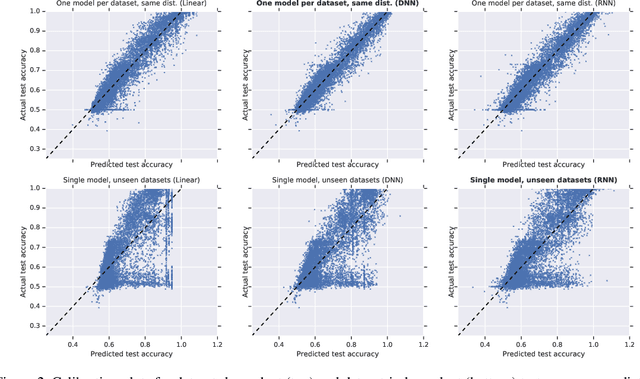

Can we use deep learning to predict when deep learning works? Our results suggest the affirmative. We created a dataset by training 13,500 neural networks with different architectures, on different variations of spiral datasets, and using different optimization parameters. We used this dataset to train task-independent and architecture-independent generalization gap predictors for those neural networks. We extend Jiang et al. (2018) to also use DNNs and RNNs and show that they outperform the linear model, obtaining $R^2=0.965$. We also show results for architecture-independent, task-independent, and out-of-distribution generalization gap prediction tasks. Both DNNs and RNNs consistently and significantly outperform linear models, with RNNs obtaining $R^2=0.584$.
AdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019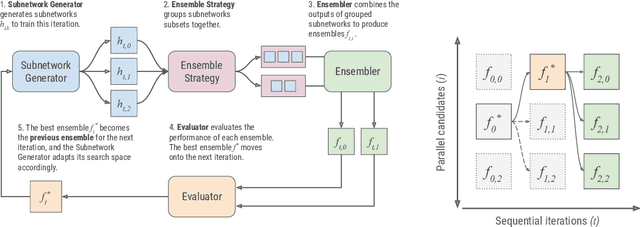
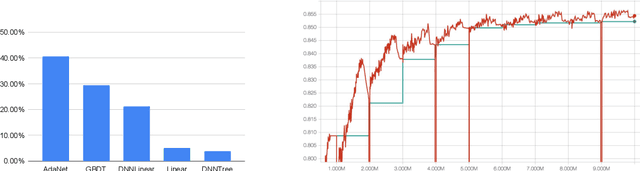
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.
Improving Neural Architecture Search Image Classifiers via Ensemble Learning
Mar 14, 2019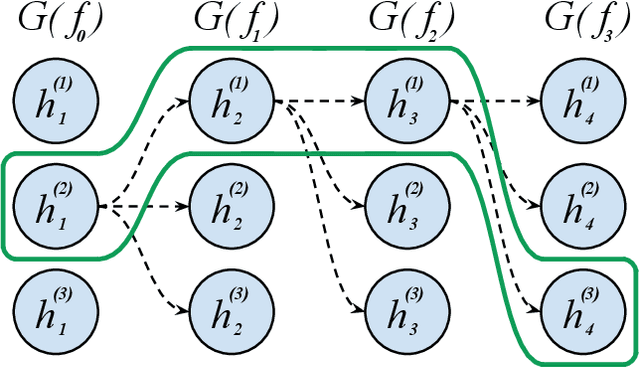
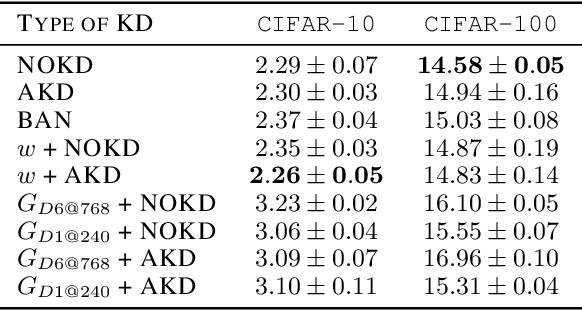
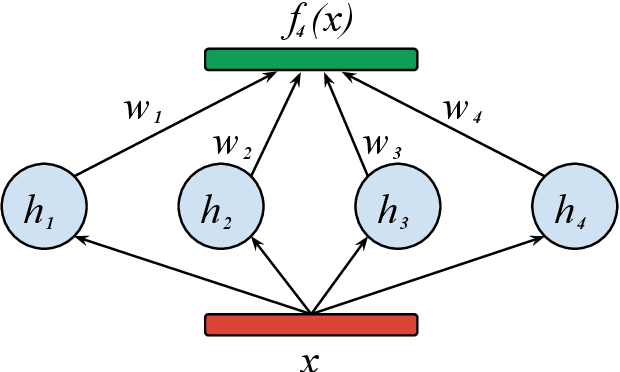
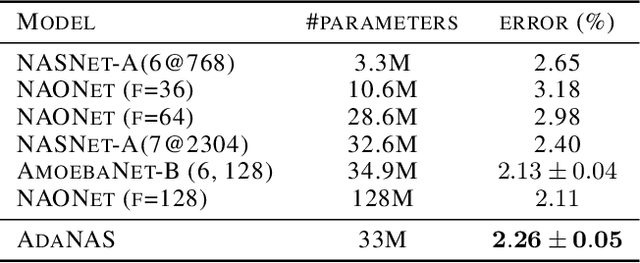
Finding the best neural network architecture requires significant time, resources, and human expertise. These challenges are partially addressed by neural architecture search (NAS) which is able to find the best convolutional layer or cell that is then used as a building block for the network. However, once a good building block is found, manual design is still required to assemble the final architecture as a combination of multiple blocks under a predefined parameter budget constraint. A common solution is to stack these blocks into a single tower and adjust the width and depth to fill the parameter budget. However, these single tower architectures may not be optimal. Instead, in this paper we present the AdaNAS algorithm, that uses ensemble techniques to compose a neural network as an ensemble of smaller networks automatically. Additionally, we introduce a novel technique based on knowledge distillation to iteratively train the smaller networks using the previous ensemble as a teacher. Our experiments demonstrate that ensembles of networks improve accuracy upon a single neural network while keeping the same number of parameters. Our models achieve comparable results with the state-of-the-art on CIFAR-10 and sets a new state-of-the-art on CIFAR-100.
Non-Adaptive Learning a Hidden Hipergraph
Feb 13, 2015

We give a new deterministic algorithm that non-adaptively learns a hidden hypergraph from edge-detecting queries. All previous non-adaptive algorithms either run in exponential time or have non-optimal query complexity. We give the first polynomial time non-adaptive learning algorithm for learning hypergraph that asks almost optimal number of queries.
On Exact Learning Monotone DNF from Membership Queries
May 05, 2014
In this paper, we study the problem of learning a monotone DNF with at most $s$ terms of size (number of variables in each term) at most $r$ ($s$ term $r$-MDNF) from membership queries. This problem is equivalent to the problem of learning a general hypergraph using hyperedge-detecting queries, a problem motivated by applications arising in chemical reactions and genome sequencing. We first present new lower bounds for this problem and then present deterministic and randomized adaptive algorithms with query complexities that are almost optimal. All the algorithms we present in this paper run in time linear in the query complexity and the number of variables $n$. In addition, all of the algorithms we present in this paper are asymptotically tight for fixed $r$ and/or $s$.