 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulated Overparameterization
Feb 07, 2024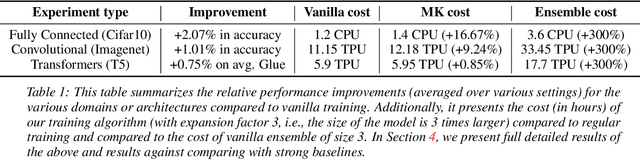
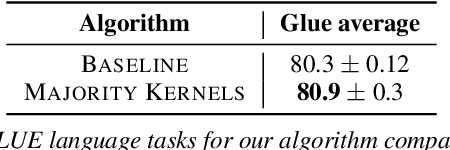

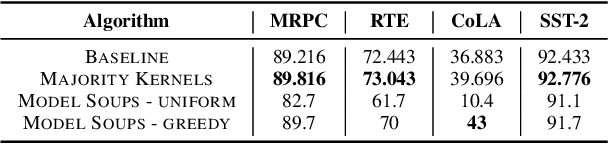
In this work, we introduce a novel paradigm called Simulated Overparametrization (SOP). SOP merges the computational efficiency of compact models with the advanced learning proficiencies of overparameterized models. SOP proposes a unique approach to model training and inference, where a model with a significantly larger number of parameters is trained in such a way that a smaller, efficient subset of these parameters is used for the actual computation during inference. Building upon this framework, we present a novel, architecture agnostic algorithm called "majority kernels", which seamlessly integrates with predominant architectures, including Transformer models. Majority kernels enables the simulated training of overparameterized models, resulting in performance gains across architectures and tasks. Furthermore, our approach adds minimal overhead to the cost incurred (wall clock time) at training time. The proposed approach shows strong performance on a wide variety of datasets and models, even outperforming strong baselines such as combinatorial optimization methods based on submodular optimization.
Deep Fusion: Efficient Network Training via Pre-trained Initializations
Jun 20, 2023



In recent years, deep learning has made remarkable progress in a wide range of domains, with a particularly notable impact on natural language processing tasks. One of the challenges associated with training deep neural networks is the need for large amounts of computational resources and time. In this paper, we present Deep Fusion, an efficient approach to network training that leverages pre-trained initializations of smaller networks. % We show that Deep Fusion accelerates the training process, reduces computational requirements, and leads to improved generalization performance on a variety of NLP tasks and T5 model sizes. % Our experiments demonstrate that Deep Fusion is a practical and effective approach to reduce the training time and resource consumption while maintaining, or even surpassing, the performance of traditional training methods.
EnergyNet: Energy-based Adaptive Structural Learning of Artificial Neural Network Architectures
Nov 08, 2017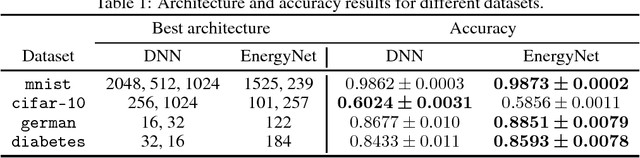
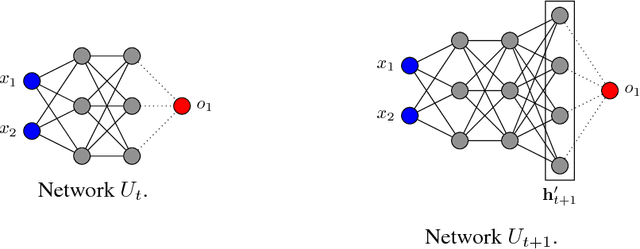
We present E NERGY N ET , a new framework for analyzing and building artificial neural network architectures. Our approach adaptively learns the structure of the networks in an unsupervised manner. The methodology is based upon the theoretical guarantees of the energy function of restricted Boltzmann machines (RBM) of infinite number of nodes. We present experimental results to show that the final network adapts to the complexity of a given problem.
AdaNet: Adaptive Structural Learning of Artificial Neural Networks
Feb 28, 2017
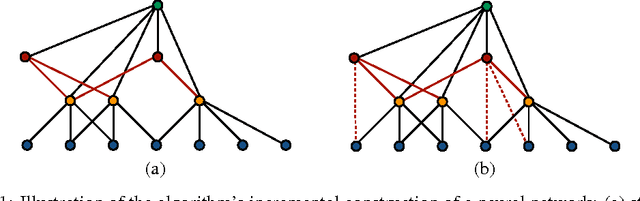

We present new algorithms for adaptively learning artificial neural networks. Our algorithms (AdaNet) adaptively learn both the structure of the network and its weights. They are based on a solid theoretical analysis, including data-dependent generalization guarantees that we prove and discuss in detail. We report the results of large-scale experiments with one of our algorithms on several binary classification tasks extracted from the CIFAR-10 dataset. The results demonstrate that our algorithm can automatically learn network structures with very competitive performance accuracies when compared with those achieved for neural networks found by standard approaches.