 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrowing the Focus: Learned Optimizers for Pretrained Models
Aug 21, 2024



In modern deep learning, the models are learned by applying gradient updates using an optimizer, which transforms the updates based on various statistics. Optimizers are often hand-designed and tuning their hyperparameters is a big part of the training process. Learned optimizers have shown some initial promise, but are generally unsuccessful as a general optimization mechanism applicable to every problem. In this work we explore a different direction: instead of learning general optimizers, we instead specialize them to a specific training environment. We propose a novel optimizer technique that learns a layer-specific linear combination of update directions provided by a set of base optimizers, effectively adapting its strategy to the specific model and dataset. When evaluated on image classification tasks, this specialized optimizer significantly outperforms both traditional off-the-shelf methods such as Adam, as well as existing general learned optimizers. Moreover, it demonstrates robust generalization with respect to model initialization, evaluating on unseen datasets, and training durations beyond its meta-training horizon.
Decentralized Learning with Multi-Headed Distillation
Nov 28, 2022



Decentralized learning with private data is a central problem in machine learning. We propose a novel distillation-based decentralized learning technique that allows multiple agents with private non-iid data to learn from each other, without having to share their data, weights or weight updates. Our approach is communication efficient, utilizes an unlabeled public dataset and uses multiple auxiliary heads for each client, greatly improving training efficiency in the case of heterogeneous data. This approach allows individual models to preserve and enhance performance on their private tasks while also dramatically improving their performance on the global aggregated data distribution. We study the effects of data and model architecture heterogeneity and the impact of the underlying communication graph topology on learning efficiency and show that our agents can significantly improve their performance compared to learning in isolation.
EnergyNet: Energy-based Adaptive Structural Learning of Artificial Neural Network Architectures
Nov 08, 2017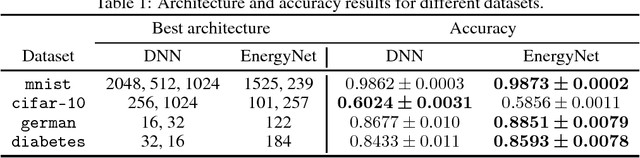
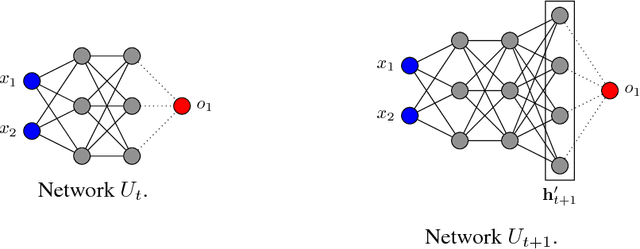
We present E NERGY N ET , a new framework for analyzing and building artificial neural network architectures. Our approach adaptively learns the structure of the networks in an unsupervised manner. The methodology is based upon the theoretical guarantees of the energy function of restricted Boltzmann machines (RBM) of infinite number of nodes. We present experimental results to show that the final network adapts to the complexity of a given problem.