 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong Context In-Context Compression by Getting to the Gist of Gisting
Apr 11, 2025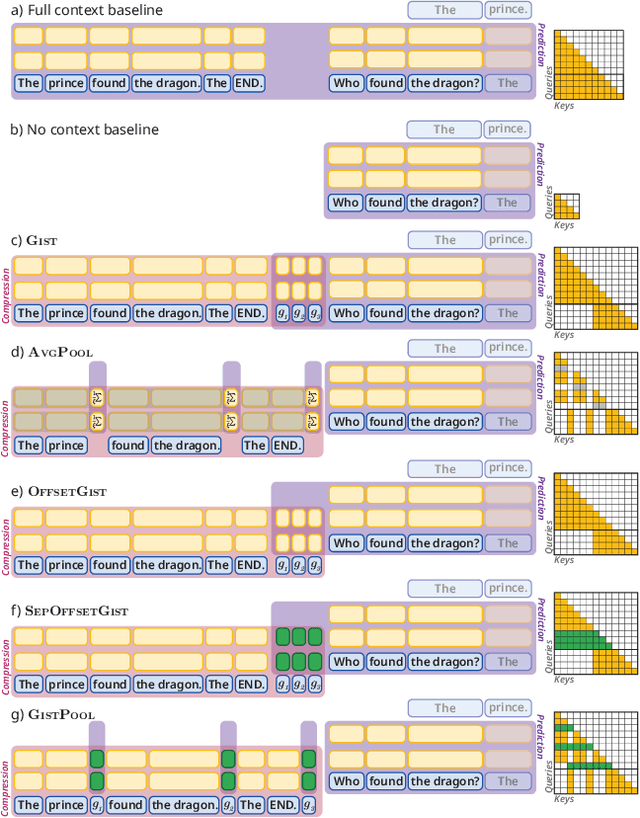
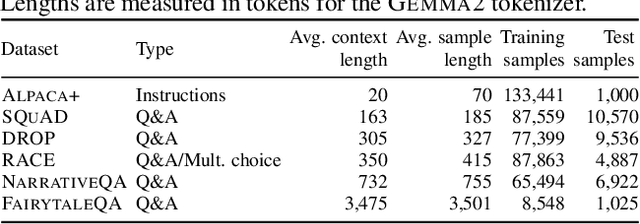
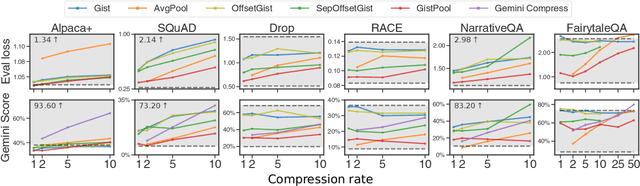
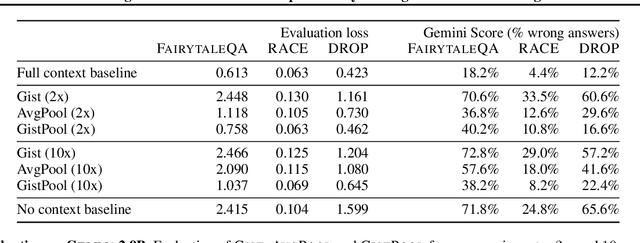
Long context processing is critical for the adoption of LLMs, but existing methods often introduce architectural complexity that hinders their practical adoption. Gisting, an in-context compression method with no architectural modification to the decoder transformer, is a promising approach due to its simplicity and compatibility with existing frameworks. While effective for short instructions, we demonstrate that gisting struggles with longer contexts, with significant performance drops even at minimal compression rates. Surprisingly, a simple average pooling baseline consistently outperforms gisting. We analyze the limitations of gisting, including information flow interruptions, capacity limitations and the inability to restrict its attention to subsets of the context. Motivated by theoretical insights into the performance gap between gisting and average pooling, and supported by extensive experimentation, we propose GistPool, a new in-context compression method. GistPool preserves the simplicity of gisting, while significantly boosting its performance on long context compression tasks.
Narrowing the Focus: Learned Optimizers for Pretrained Models
Aug 21, 2024



In modern deep learning, the models are learned by applying gradient updates using an optimizer, which transforms the updates based on various statistics. Optimizers are often hand-designed and tuning their hyperparameters is a big part of the training process. Learned optimizers have shown some initial promise, but are generally unsuccessful as a general optimization mechanism applicable to every problem. In this work we explore a different direction: instead of learning general optimizers, we instead specialize them to a specific training environment. We propose a novel optimizer technique that learns a layer-specific linear combination of update directions provided by a set of base optimizers, effectively adapting its strategy to the specific model and dataset. When evaluated on image classification tasks, this specialized optimizer significantly outperforms both traditional off-the-shelf methods such as Adam, as well as existing general learned optimizers. Moreover, it demonstrates robust generalization with respect to model initialization, evaluating on unseen datasets, and training durations beyond its meta-training horizon.
Uncovering mesa-optimization algorithms in Transformers
Sep 11, 2023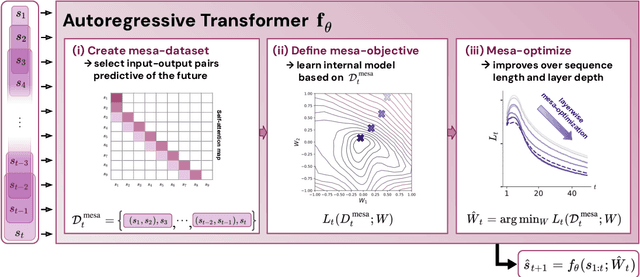
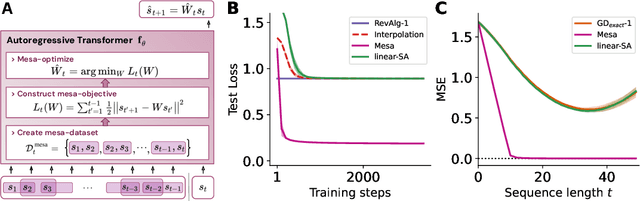
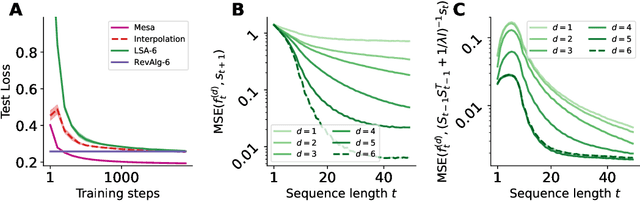
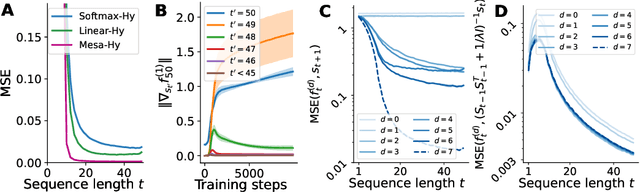
Transformers have become the dominant model in deep learning, but the reason for their superior performance is poorly understood. Here, we hypothesize that the strong performance of Transformers stems from an architectural bias towards mesa-optimization, a learned process running within the forward pass of a model consisting of the following two steps: (i) the construction of an internal learning objective, and (ii) its corresponding solution found through optimization. To test this hypothesis, we reverse-engineer a series of autoregressive Transformers trained on simple sequence modeling tasks, uncovering underlying gradient-based mesa-optimization algorithms driving the generation of predictions. Moreover, we show that the learned forward-pass optimization algorithm can be immediately repurposed to solve supervised few-shot tasks, suggesting that mesa-optimization might underlie the in-context learning capabilities of large language models. Finally, we propose a novel self-attention layer, the mesa-layer, that explicitly and efficiently solves optimization problems specified in context. We find that this layer can lead to improved performance in synthetic and preliminary language modeling experiments, adding weight to our hypothesis that mesa-optimization is an important operation hidden within the weights of trained Transformers.
Training trajectories, mini-batch losses and the curious role of the learning rate
Jan 05, 2023



Stochastic gradient descent plays a fundamental role in nearly all applications of deep learning. However its efficiency and remarkable ability to converge to global minimum remains shrouded in mystery. The loss function defined on a large network with large amount of data is known to be non-convex. However, relatively little has been explored about the behavior of loss function on individual batches. Remarkably, we show that for ResNet the loss for any fixed mini-batch when measured along side SGD trajectory appears to be accurately modeled by a quadratic function. In particular, a very low loss value can be reached in just one step of gradient descent with large enough learning rate. We propose a simple model and a geometric interpretation that allows to analyze the relationship between the gradients of stochastic mini-batches and the full batch and how the learning rate affects the relationship between improvement on individual and full batch. Our analysis allows us to discover the equivalency between iterate aggregates and specific learning rate schedules. In particular, for Exponential Moving Average (EMA) and Stochastic Weight Averaging we show that our proposed model matches the observed training trajectories on ImageNet. Our theoretical model predicts that an even simpler averaging technique, averaging just two points a few steps apart, also significantly improves accuracy compared to the baseline. We validated our findings on ImageNet and other datasets using ResNet architecture.
Decentralized Learning with Multi-Headed Distillation
Nov 28, 2022



Decentralized learning with private data is a central problem in machine learning. We propose a novel distillation-based decentralized learning technique that allows multiple agents with private non-iid data to learn from each other, without having to share their data, weights or weight updates. Our approach is communication efficient, utilizes an unlabeled public dataset and uses multiple auxiliary heads for each client, greatly improving training efficiency in the case of heterogeneous data. This approach allows individual models to preserve and enhance performance on their private tasks while also dramatically improving their performance on the global aggregated data distribution. We study the effects of data and model architecture heterogeneity and the impact of the underlying communication graph topology on learning efficiency and show that our agents can significantly improve their performance compared to learning in isolation.
Meta-Learning Bidirectional Update Rules
Apr 10, 2021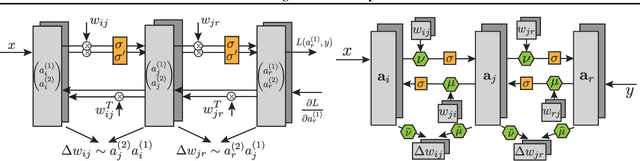
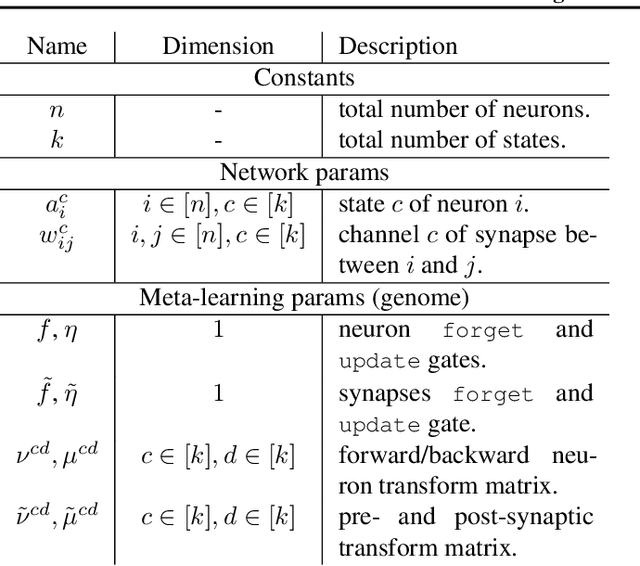
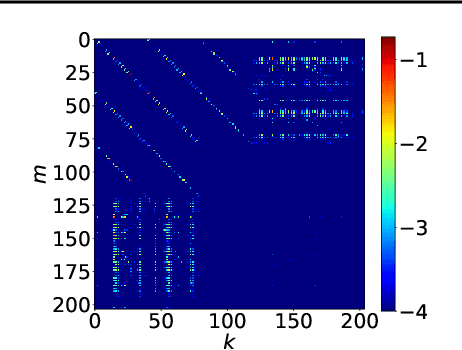
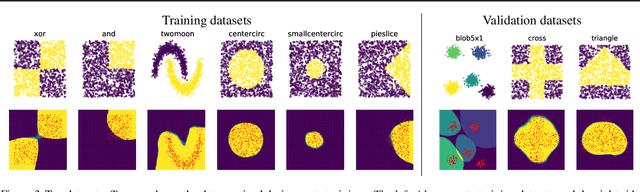
In this paper, we introduce a new type of generalized neural network where neurons and synapses maintain multiple states. We show that classical gradient-based backpropagation in neural networks can be seen as a special case of a two-state network where one state is used for activations and another for gradients, with update rules derived from the chain rule. In our generalized framework, networks have neither explicit notion of nor ever receive gradients. The synapses and neurons are updated using a bidirectional Hebb-style update rule parameterized by a shared low-dimensional "genome". We show that such genomes can be meta-learned from scratch, using either conventional optimization techniques, or evolutionary strategies, such as CMA-ES. Resulting update rules generalize to unseen tasks and train faster than gradient descent based optimizers for several standard computer vision and synthetic tasks.