 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNomad: Autonomous Exploration and Discovery
Apr 02, 2026We introduce Nomad, a system for autonomous data exploration and insight discovery. Given a corpus of documents, databases, or other data sources, users rarely know the full set of questions, hypotheses, or connections that could be explored. As a result, query-driven question answering and prompt-driven deep-research systems remain limited by human framing and often fail to cover the broader insight space. Nomad addresses this problem with an exploration-first architecture. It constructs an explicit Exploration Map over the domain and systematically traverses it to balance breadth and depth. It generates and selects hypotheses and investigates them with an explorer agent that can use document search, web search, and database tools. Candidate insights are then checked by an independent verifier before entering a reporting pipeline that produces cited reports and higher-level meta-reports. We also present a comprehensive evaluation framework for autonomous discovery systems that measures trustworthiness, report quality, and diversity. Using a corpus of selected UN and WHO reports, we show that Nomad produces more trustworthy and higher-quality reports than baselines, while also producing more diverse insights over several runs. Nomad is a step toward autonomous systems that not only answer user questions or conduct directed research, but also discover which questions, research directions, and insights are worth surfacing in the first place.
Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models
Aug 30, 2023
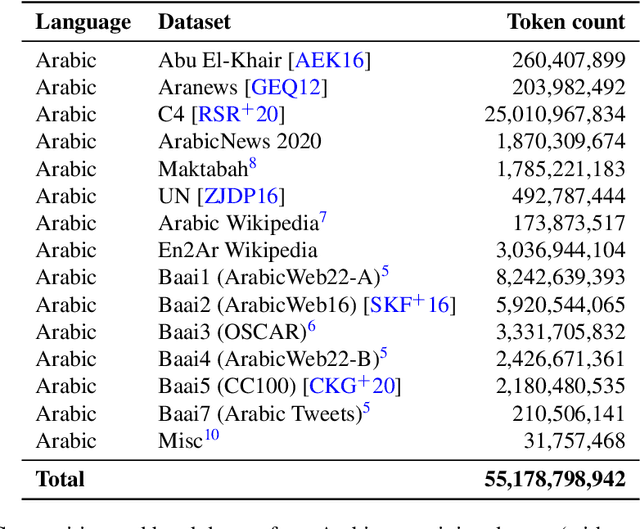
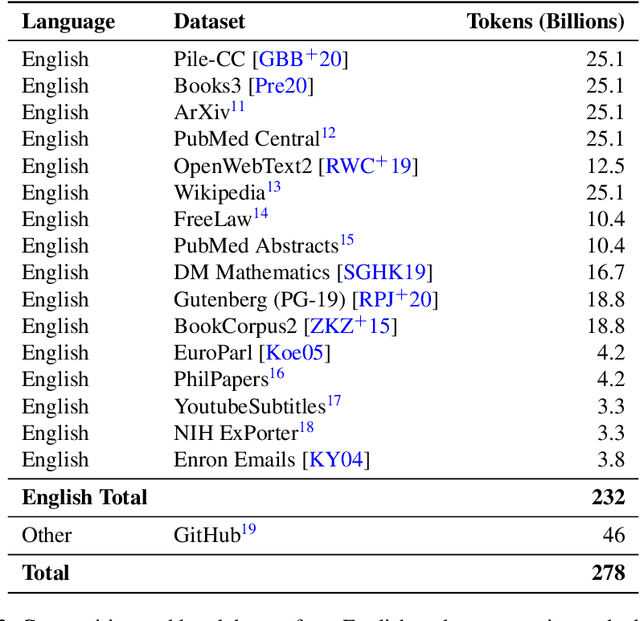
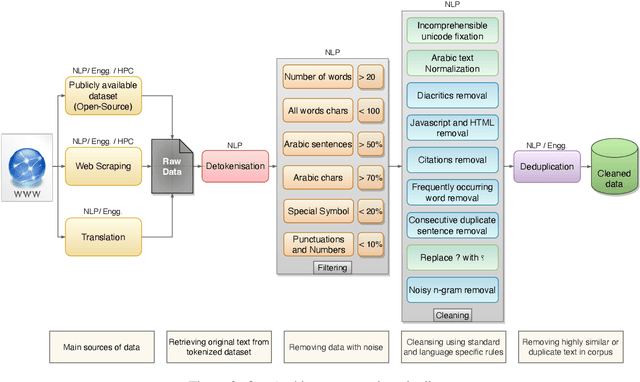
We introduce Jais and Jais-chat, new state-of-the-art Arabic-centric foundation and instruction-tuned open generative large language models (LLMs). The models are based on the GPT-3 decoder-only architecture and are pretrained on a mixture of Arabic and English texts, including source code in various programming languages. With 13 billion parameters, they demonstrate better knowledge and reasoning capabilities in Arabic than any existing open Arabic and multilingual models by a sizable margin, based on extensive evaluation. Moreover, the models are competitive in English compared to English-centric open models of similar size, despite being trained on much less English data. We provide a detailed description of the training, the tuning, the safety alignment, and the evaluation of the models. We release two open versions of the model -- the foundation Jais model, and an instruction-tuned Jais-chat variant -- with the aim of promoting research on Arabic LLMs. Available at https://huggingface.co/inception-mbzuai/jais-13b-chat
Fine-tuning Image Transformers using Learnable Memory
Mar 30, 2022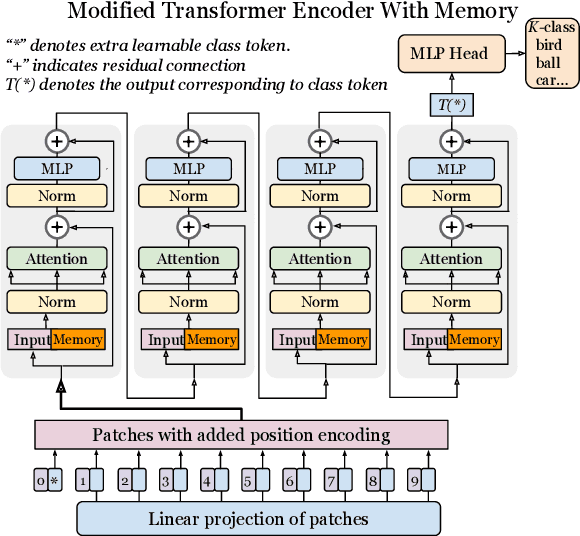
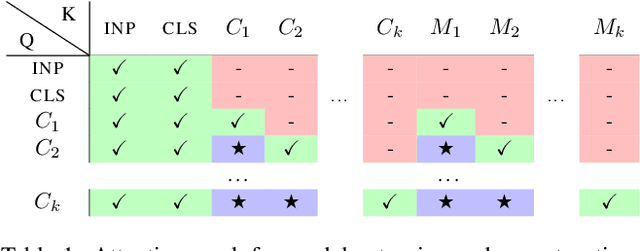
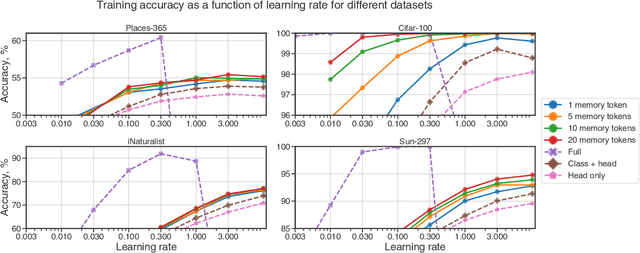
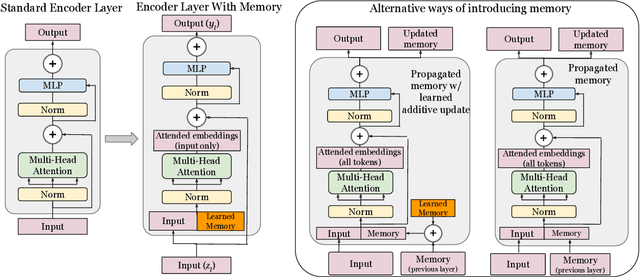
In this paper we propose augmenting Vision Transformer models with learnable memory tokens. Our approach allows the model to adapt to new tasks, using few parameters, while optionally preserving its capabilities on previously learned tasks. At each layer we introduce a set of learnable embedding vectors that provide contextual information useful for specific datasets. We call these "memory tokens". We show that augmenting a model with just a handful of such tokens per layer significantly improves accuracy when compared to conventional head-only fine-tuning, and performs only slightly below the significantly more expensive full fine-tuning. We then propose an attention-masking approach that enables extension to new downstream tasks, with a computation reuse. In this setup in addition to being parameters efficient, models can execute both old and new tasks as a part of single inference at a small incremental cost.
Meta-Learning Bidirectional Update Rules
Apr 10, 2021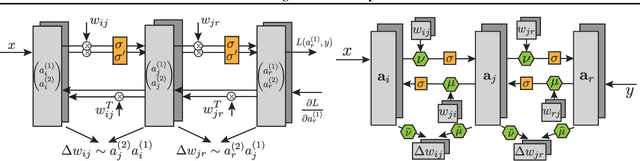
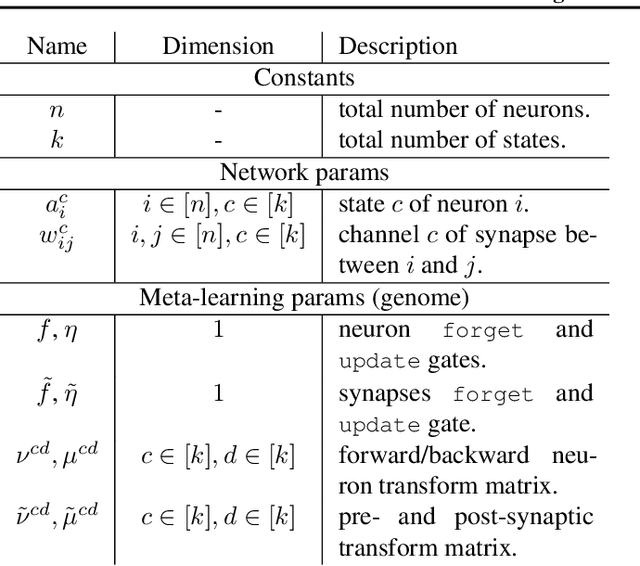
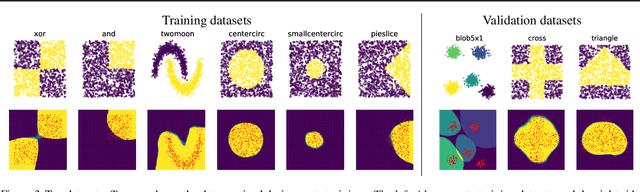
In this paper, we introduce a new type of generalized neural network where neurons and synapses maintain multiple states. We show that classical gradient-based backpropagation in neural networks can be seen as a special case of a two-state network where one state is used for activations and another for gradients, with update rules derived from the chain rule. In our generalized framework, networks have neither explicit notion of nor ever receive gradients. The synapses and neurons are updated using a bidirectional Hebb-style update rule parameterized by a shared low-dimensional "genome". We show that such genomes can be meta-learned from scratch, using either conventional optimization techniques, or evolutionary strategies, such as CMA-ES. Resulting update rules generalize to unseen tasks and train faster than gradient descent based optimizers for several standard computer vision and synthetic tasks.