 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining in reverse: How iteration order influences convergence and stability in deep learning
Feb 03, 2025Despite exceptional achievements, training neural networks remains computationally expensive and is often plagued by instabilities that can degrade convergence. While learning rate schedules can help mitigate these issues, finding optimal schedules is time-consuming and resource-intensive. This work explores theoretical issues concerning training stability in the constant-learning-rate (i.e., without schedule) and small-batch-size regime. Surprisingly, we show that the order of gradient updates affects stability and convergence in gradient-based optimizers. We illustrate this new line of thinking using backward-SGD, which processes batch gradient updates like SGD but in reverse order. Our theoretical analysis shows that in contractive regions (e.g., around minima) backward-SGD converges to a point while the standard forward-SGD generally only converges to a distribution. This leads to improved stability and convergence which we demonstrate experimentally. While full backward-SGD is computationally intensive in practice, it highlights opportunities to exploit reverse training dynamics (or more generally alternate iteration orders) to improve training. To our knowledge, this represents a new and unexplored avenue in deep learning optimization.
Deep limits and cut-off phenomena for neural networks
Apr 21, 2021
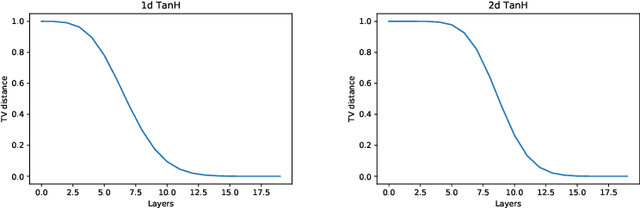

We consider dynamical and geometrical aspects of deep learning. For many standard choices of layer maps we display semi-invariant metrics which quantify differences between data or decision functions. This allows us, when considering random layer maps and using non-commutative ergodic theorems, to deduce that certain limits exist when letting the number of layers tend to infinity. We also examine the random initialization of standard networks where we observe a surprising cut-off phenomenon in terms of the number of layers, the depth of the network. This could be a relevant parameter when choosing an appropriate number of layers for a given learning task, or for selecting a good initialization procedure. More generally, we hope that the notions and results in this paper can provide a framework, in particular a geometric one, for a part of the theoretical understanding of deep neural networks.