 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2020 Competition: Predicting Generalization in Deep Learning
Dec 14, 2020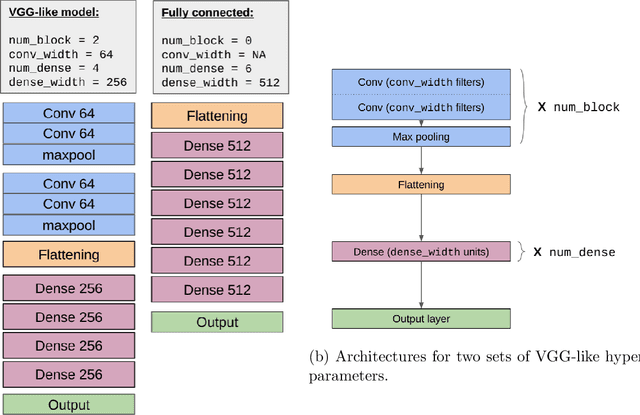
Understanding generalization in deep learning is arguably one of the most important questions in deep learning. Deep learning has been successfully adopted to a large number of problems ranging from pattern recognition to complex decision making, but many recent researchers have raised many concerns about deep learning, among which the most important is generalization. Despite numerous attempts, conventional statistical learning approaches have yet been able to provide a satisfactory explanation on why deep learning works. A recent line of works aims to address the problem by trying to predict the generalization performance through complexity measures. In this competition, we invite the community to propose complexity measures that can accurately predict generalization of models. A robust and general complexity measure would potentially lead to a better understanding of deep learning's underlying mechanism and behavior of deep models on unseen data, or shed light on better generalization bounds. All these outcomes will be important for making deep learning more robust and reliable.
Towards Task and Architecture-Independent Generalization Gap Predictors
Jun 04, 2019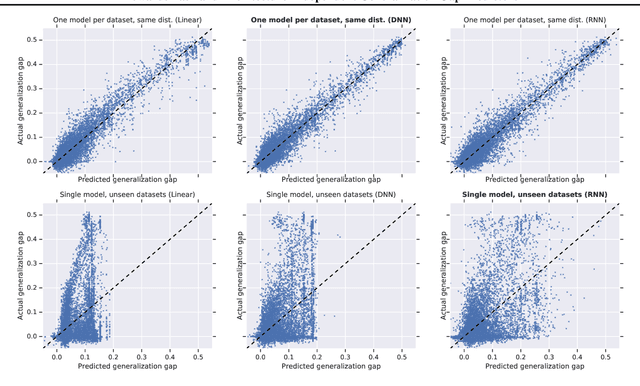

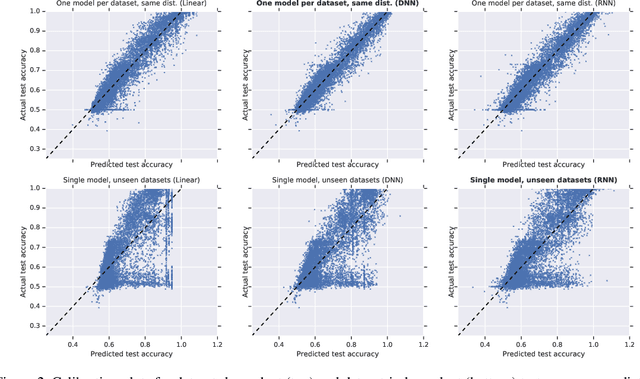

Can we use deep learning to predict when deep learning works? Our results suggest the affirmative. We created a dataset by training 13,500 neural networks with different architectures, on different variations of spiral datasets, and using different optimization parameters. We used this dataset to train task-independent and architecture-independent generalization gap predictors for those neural networks. We extend Jiang et al. (2018) to also use DNNs and RNNs and show that they outperform the linear model, obtaining $R^2=0.965$. We also show results for architecture-independent, task-independent, and out-of-distribution generalization gap prediction tasks. Both DNNs and RNNs consistently and significantly outperform linear models, with RNNs obtaining $R^2=0.584$.
AdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019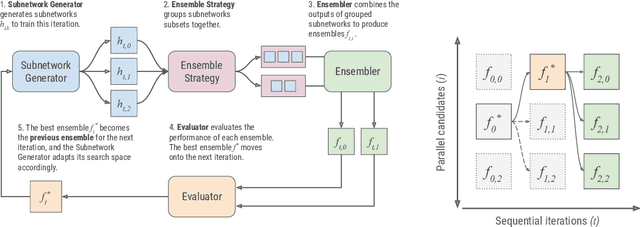
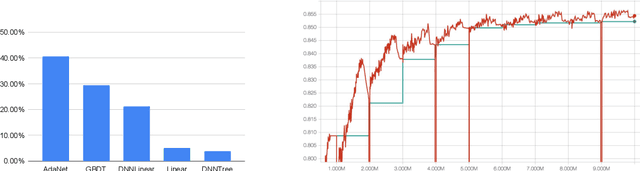
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.