 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoGR: Disaggregated Gaussian Regression for Reproducible Analysis of Heterogeneous Data
Aug 31, 2021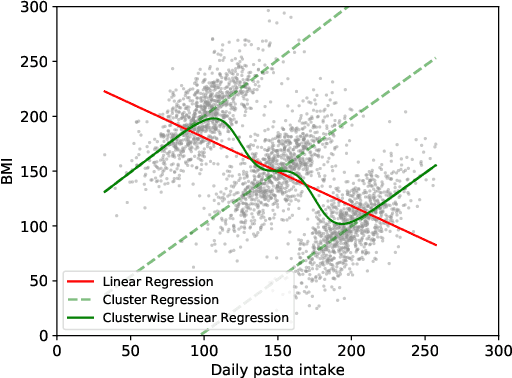
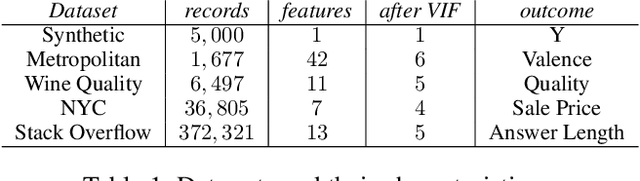
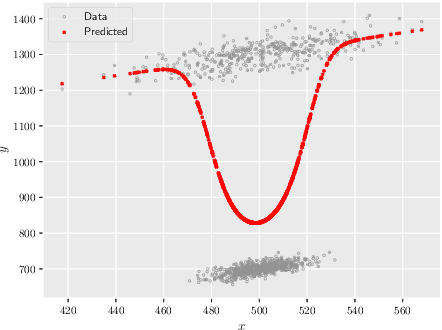
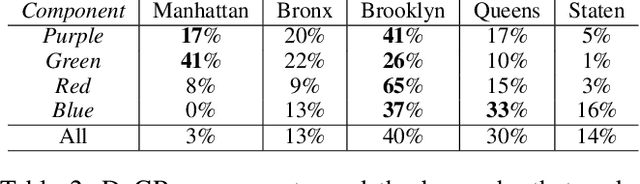
Quantitative analysis of large-scale data is often complicated by the presence of diverse subgroups, which reduce the accuracy of inferences they make on held-out data. To address the challenge of heterogeneous data analysis, we introduce DoGR, a method that discovers latent confounders by simultaneously partitioning the data into overlapping clusters (disaggregation) and modeling the behavior within them (regression). When applied to real-world data, our method discovers meaningful clusters and their characteristic behaviors, thus giving insight into group differences and their impact on the outcome of interest. By accounting for latent confounders, our framework facilitates exploratory analysis of noisy, heterogeneous data and can be used to learn predictive models that better generalize to new data. We provide the code to enable others to use DoGR within their data analytic workflows.
MixHop: Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
May 28, 2019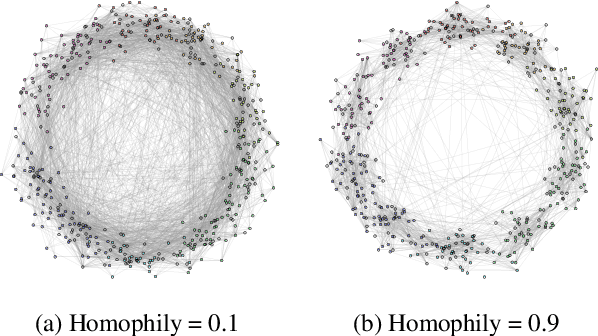
Existing popular methods for semi-supervised learning with Graph Neural Networks (such as the Graph Convolutional Network) provably cannot learn a general class of neighborhood mixing relationships. To address this weakness, we propose a new model, MixHop, that can learn these relationships, including difference operators, by repeatedly mixing feature representations of neighbors at various distances. Mixhop requires no additional memory or computational complexity, and outperforms on challenging baselines. In addition, we propose sparsity regularization that allows us to visualize how the network prioritizes neighborhood information across different graph datasets. Our analysis of the learned architectures reveals that neighborhood mixing varies per datasets.
Using Simpson's Paradox to Discover Interesting Patterns in Behavioral Data
May 08, 2018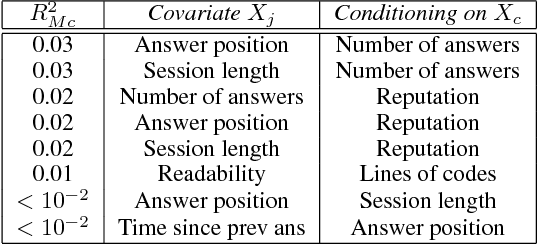

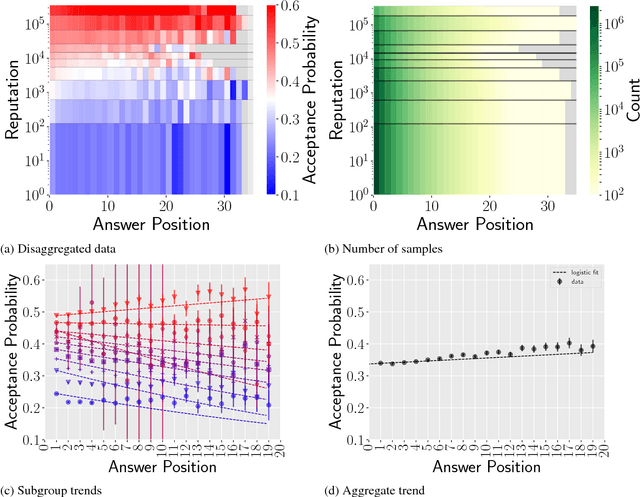
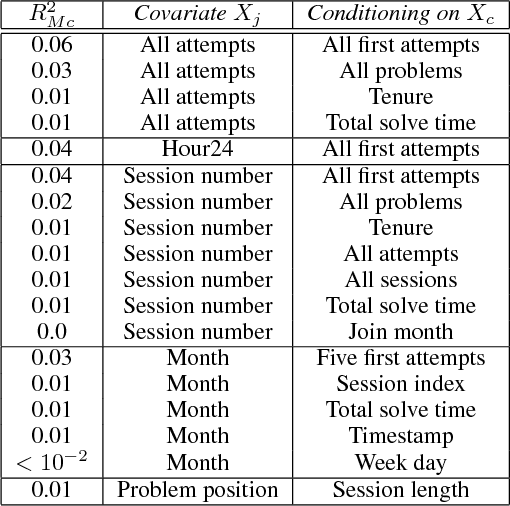
We describe a data-driven discovery method that leverages Simpson's paradox to uncover interesting patterns in behavioral data. Our method systematically disaggregates data to identify subgroups within a population whose behavior deviates significantly from the rest of the population. Given an outcome of interest and a set of covariates, the method follows three steps. First, it disaggregates data into subgroups, by conditioning on a particular covariate, so as minimize the variation of the outcome within the subgroups. Next, it models the outcome as a linear function of another covariate, both in the subgroups and in the aggregate data. Finally, it compares trends to identify disaggregations that produce subgroups with different behaviors from the aggregate. We illustrate the method by applying it to three real-world behavioral datasets, including Q\&A site Stack Exchange and online learning platforms Khan Academy and Duolingo.