 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Simpson's Paradox to Discover Interesting Patterns in Behavioral Data
May 08, 2018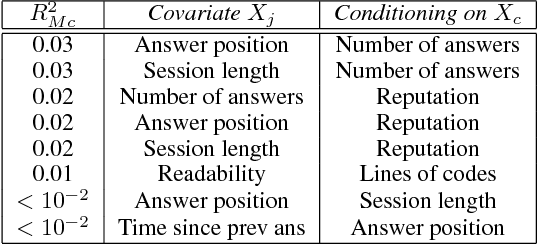

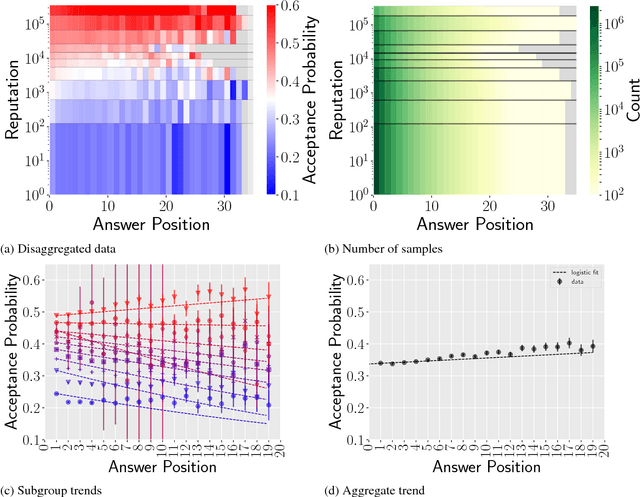
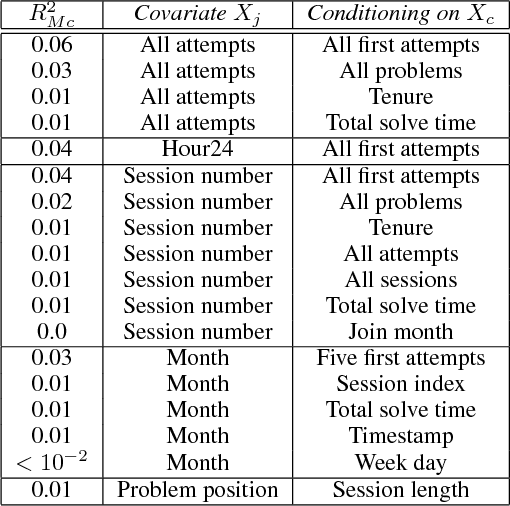
We describe a data-driven discovery method that leverages Simpson's paradox to uncover interesting patterns in behavioral data. Our method systematically disaggregates data to identify subgroups within a population whose behavior deviates significantly from the rest of the population. Given an outcome of interest and a set of covariates, the method follows three steps. First, it disaggregates data into subgroups, by conditioning on a particular covariate, so as minimize the variation of the outcome within the subgroups. Next, it models the outcome as a linear function of another covariate, both in the subgroups and in the aggregate data. Finally, it compares trends to identify disaggregations that produce subgroups with different behaviors from the aggregate. We illustrate the method by applying it to three real-world behavioral datasets, including Q\&A site Stack Exchange and online learning platforms Khan Academy and Duolingo.