 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming GenAI Policy to Prompting Instruction: An RCT of Scalable Prompting Interventions in a CS1 Course
Feb 17, 2026Despite universal GenAI adoption, students cannot distinguish task performance from actual learning and lack skills to leverage AI for learning, leading to worse exam performance when AI use remains unreflective. Yet few interventions teaching students to prompt AI as a tutor rather than solution provider have been validated at scale through randomized controlled trials (RCTs). To bridge this gap, we conducted a semester-long RCT (N=979) with four ICAP framework-based instructional conditions varying in engagement intensity with a pre-test, immediate and delayed post-test and surveys. Mixed methods analysis results showed: (1) All conditions significantly improved prompting skills, with gains increasing progressively from Condition 1 to Condition 4, validating ICAP's cognitive engagement hierarchy; (2) for students with similar pre-test scores, higher learning gain in immediate post-test predict higher final exam score, though no direct between-group differences emerged; (3) Our interventions are suitable and scalable solutions for diverse educational contexts, resources and learners. Together, this study makes empirical and theoretical contributions: (1) theoretically, we provided one of the first large-scale RCTs examining how cognitive engagement shapes learning in prompting literacy and clarifying the relationship between learning-oriented prompting skills and broader academic performance; (2) empirically, we offered timely design guidance for transforming GenAI classroom policies into scalable, actionable prompting literacy instruction to advance learning in the era of Generative AI.
Improving Student-AI Interaction Through Pedagogical Prompting: An Example in Computer Science Education
Jun 23, 2025
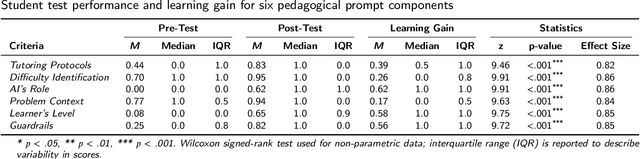


With the proliferation of large language model (LLM) applications since 2022, their use in education has sparked both excitement and concern. Recent studies consistently highlight students' (mis)use of LLMs can hinder learning outcomes. This work aims to teach students how to effectively prompt LLMs to improve their learning. We first proposed pedagogical prompting, a theoretically-grounded new concept to elicit learning-oriented responses from LLMs. To move from concept design to a proof-of-concept learning intervention in real educational settings, we selected early undergraduate CS education (CS1/CS2) as the example context. We began with a formative survey study with instructors (N=36) teaching early-stage undergraduate-level CS courses to inform the instructional design based on classroom needs. Based on their insights, we designed and developed a learning intervention through an interactive system with scenario-based instruction to train pedagogical prompting skills. Finally, we evaluated its instructional effectiveness through a user study with CS novice students (N=22) using pre/post-tests. Through mixed methods analyses, our results indicate significant improvements in learners' LLM-based pedagogical help-seeking skills, along with positive attitudes toward the system and increased willingness to use pedagogical prompts in the future. Our contributions include (1) a theoretical framework of pedagogical prompting; (2) empirical insights into current instructor attitudes toward pedagogical prompting; and (3) a learning intervention design with an interactive learning tool and scenario-based instruction leading to promising results on teaching LLM-based help-seeking. Our approach is scalable for broader implementation in classrooms and has the potential to be integrated into tools like ChatGPT as an on-boarding experience to encourage learning-oriented use of generative AI.
Insights from Social Shaping Theory: The Appropriation of Large Language Models in an Undergraduate Programming Course
Jun 10, 2024



The capability of large language models (LLMs) to generate, debug, and explain code has sparked the interest of researchers and educators in undergraduate programming, with many anticipating their transformative potential in programming education. However, decisions about why and how to use LLMs in programming education may involve more than just the assessment of an LLM's technical capabilities. Using the social shaping of technology theory as a guiding framework, our study explores how students' social perceptions influence their own LLM usage. We then examine the correlation of self-reported LLM usage with students' self-efficacy and midterm performances in an undergraduate programming course. Triangulating data from an anonymous end-of-course student survey (n = 158), a mid-course self-efficacy survey (n=158), student interviews (n = 10), self-reported LLM usage on homework, and midterm performances, we discovered that students' use of LLMs was associated with their expectations for their future careers and their perceptions of peer usage. Additionally, early self-reported LLM usage in our context correlated with lower self-efficacy and lower midterm scores, while students' perceived over-reliance on LLMs, rather than their usage itself, correlated with decreased self-efficacy later in the course.
Exploring How Multiple Levels of GPT-Generated Programming Hints Support or Disappoint Novices
Apr 02, 2024



Recent studies have integrated large language models (LLMs) into diverse educational contexts, including providing adaptive programming hints, a type of feedback focuses on helping students move forward during problem-solving. However, most existing LLM-based hint systems are limited to one single hint type. To investigate whether and how different levels of hints can support students' problem-solving and learning, we conducted a think-aloud study with 12 novices using the LLM Hint Factory, a system providing four levels of hints from general natural language guidance to concrete code assistance, varying in format and granularity. We discovered that high-level natural language hints alone can be helpless or even misleading, especially when addressing next-step or syntax-related help requests. Adding lower-level hints, like code examples with in-line comments, can better support students. The findings open up future work on customizing help responses from content, format, and granularity levels to accurately identify and meet students' learning needs.
Evaluating ChatGPT's Decimal Skills and Feedback Generation in a Digital Learning Game
Jun 29, 2023



While open-ended self-explanations have been shown to promote robust learning in multiple studies, they pose significant challenges to automated grading and feedback in technology-enhanced learning, due to the unconstrained nature of the students' input. Our work investigates whether recent advances in Large Language Models, and in particular ChatGPT, can address this issue. Using decimal exercises and student data from a prior study of the learning game Decimal Point, with more than 5,000 open-ended self-explanation responses, we investigate ChatGPT's capability in (1) solving the in-game exercises, (2) determining the correctness of students' answers, and (3) providing meaningful feedback to incorrect answers. Our results showed that ChatGPT can respond well to conceptual questions, but struggled with decimal place values and number line problems. In addition, it was able to accurately assess the correctness of 75% of the students' answers and generated generally high-quality feedback, similar to human instructors. We conclude with a discussion of ChatGPT's strengths and weaknesses and suggest several venues for extending its use cases in digital teaching and learning.