 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Traces for Novice Programmers: Learning Effects and Learner Differences in a Multi-Institutional Study
Jun 02, 2026Introductory programming (CS1) courses often struggle to support students' understanding of program execution. While visualizations can make execution processes explicit, their effectiveness depends on design and context, and empirical evidence for AI-generated visualizations remains limited. We propose Generated Animated Traces (GATs), AI-generated, analogy-based, narrated animations that coordinate source code, execution state, and conceptual analogies. We conduct a study at two institutions in CS1 courses (Python, N=961; Java N=151) comparing GATs to textual explanations. We measure immediate learning performance and experience, end-of-course engagement and exam performance. Results show that GATs can yield selective benefits for immediate learning, but benefits are context-dependent and short-term. We observe that GATs' influence on performance is moderated by learner engagement profiles. This finding underscores the importance of personalized approaches.
Generative Experiences for Digital Mental Health Interventions: Evidence from a Randomized Study
Apr 08, 2026Digital mental health (DMH) tools have extensively explored personalization of interventions to users' needs and contexts. However, this personalization often targets what support is provided, not how it is experienced. Even well-matched content can fail when the interaction format misaligns with how someone can engage. We introduce generative experience as a paradigm for DMH support, where the intervention experience is composed at runtime. We instantiate this in GUIDE, a system that generates personalized intervention content and multimodal interaction structure through rubric-guided generation of modular components. In a preregistered study with N = 237 participants, GUIDE significantly reduced stress (p = .02) and improved the user experience (p = .04) compared to an LLM-based cognitive restructuring control. GUIDE also supported diverse forms of reflection and action through varied interaction flows, while revealing tensions around personalization across the interaction sequence. This work lays the foundation for interventions that dynamically shape how support is experienced and enacted in digital settings.
Transforming GenAI Policy to Prompting Instruction: An RCT of Scalable Prompting Interventions in a CS1 Course
Feb 17, 2026Despite universal GenAI adoption, students cannot distinguish task performance from actual learning and lack skills to leverage AI for learning, leading to worse exam performance when AI use remains unreflective. Yet few interventions teaching students to prompt AI as a tutor rather than solution provider have been validated at scale through randomized controlled trials (RCTs). To bridge this gap, we conducted a semester-long RCT (N=979) with four ICAP framework-based instructional conditions varying in engagement intensity with a pre-test, immediate and delayed post-test and surveys. Mixed methods analysis results showed: (1) All conditions significantly improved prompting skills, with gains increasing progressively from Condition 1 to Condition 4, validating ICAP's cognitive engagement hierarchy; (2) for students with similar pre-test scores, higher learning gain in immediate post-test predict higher final exam score, though no direct between-group differences emerged; (3) Our interventions are suitable and scalable solutions for diverse educational contexts, resources and learners. Together, this study makes empirical and theoretical contributions: (1) theoretically, we provided one of the first large-scale RCTs examining how cognitive engagement shapes learning in prompting literacy and clarifying the relationship between learning-oriented prompting skills and broader academic performance; (2) empirically, we offered timely design guidance for transforming GenAI classroom policies into scalable, actionable prompting literacy instruction to advance learning in the era of Generative AI.
Reflexis: Supporting Reflexivity and Rigor in Collaborative Qualitative Analysis through Design for Deliberation
Jan 21, 2026Reflexive Thematic Analysis (RTA) is a critical method for generating deep interpretive insights. Yet its core tenets, including researcher reflexivity, tangible analytical evolution, and productive disagreement, are often poorly supported by software tools that prioritize speed and consensus over interpretive depth. To address this gap, we introduce Reflexis, a collaborative workspace that centers these practices. It supports reflexivity by integrating in-situ reflection prompts, makes code evolution transparent and tangible, and scaffolds collaborative interpretation by turning differences into productive, positionality-aware dialogue. Results from our paired-analyst study (N=12) indicate that Reflexis encouraged participants toward more granular reflection and reframed disagreements as productive conversations. The evaluation also surfaced key design tensions, including a desire for higher-level, networked memos and more user control over the timing of proactive alerts. Reflexis contributes a design framework for tools that prioritize rigor and transparency to support deep, collaborative interpretation in an age of automation.
TreeWriter: AI-Assisted Hierarchical Planning and Writing for Long-Form Documents
Jan 19, 2026Long documents pose many challenges to current intelligent writing systems. These include maintaining consistency across sections, sustaining efficient planning and writing as documents become more complex, and effectively providing and integrating AI assistance to the user. Existing AI co-writing tools offer either inline suggestions or limited structured planning, but rarely support the entire writing process that begins with high-level ideas and ends with polished prose, in which many layers of planning and outlining are needed. Here, we introduce TreeWriter, a hierarchical writing system that represents documents as trees and integrates contextual AI support. TreeWriter allows authors to create, save, and refine document outlines at multiple levels, facilitating drafting, understanding, and iterative editing of long documents. A built-in AI agent can dynamically load relevant content, navigate the document hierarchy, and provide context-aware editing suggestions. A within-subject study (N=12) comparing TreeWriter with Google Docs + Gemini on long-document editing and creative writing tasks shows that TreeWriter improves idea exploration/development, AI helpfulness, and perceived authorial control. A two-month field deployment (N=8) further demonstrated that hierarchical organization supports collaborative writing. Our findings highlight the potential of hierarchical, tree-structured editors with integrated AI support and provide design guidelines for future AI-assisted writing tools that balance automation with user agency.
Improving Student-AI Interaction Through Pedagogical Prompting: An Example in Computer Science Education
Jun 23, 2025
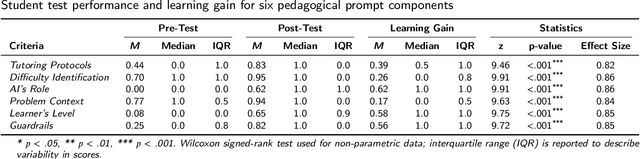


With the proliferation of large language model (LLM) applications since 2022, their use in education has sparked both excitement and concern. Recent studies consistently highlight students' (mis)use of LLMs can hinder learning outcomes. This work aims to teach students how to effectively prompt LLMs to improve their learning. We first proposed pedagogical prompting, a theoretically-grounded new concept to elicit learning-oriented responses from LLMs. To move from concept design to a proof-of-concept learning intervention in real educational settings, we selected early undergraduate CS education (CS1/CS2) as the example context. We began with a formative survey study with instructors (N=36) teaching early-stage undergraduate-level CS courses to inform the instructional design based on classroom needs. Based on their insights, we designed and developed a learning intervention through an interactive system with scenario-based instruction to train pedagogical prompting skills. Finally, we evaluated its instructional effectiveness through a user study with CS novice students (N=22) using pre/post-tests. Through mixed methods analyses, our results indicate significant improvements in learners' LLM-based pedagogical help-seeking skills, along with positive attitudes toward the system and increased willingness to use pedagogical prompts in the future. Our contributions include (1) a theoretical framework of pedagogical prompting; (2) empirical insights into current instructor attitudes toward pedagogical prompting; and (3) a learning intervention design with an interactive learning tool and scenario-based instruction leading to promising results on teaching LLM-based help-seeking. Our approach is scalable for broader implementation in classrooms and has the potential to be integrated into tools like ChatGPT as an on-boarding experience to encourage learning-oriented use of generative AI.
The Design Space of Recent AI-assisted Research Tools for Ideation, Sensemaking, and Scientific Creativity
Feb 22, 2025Generative AI (GenAI) tools are radically expanding the scope and capability of automation in knowledge work such as academic research. AI-assisted research tools show promise for augmenting human cognition and streamlining research processes, but could potentially increase automation bias and stifle critical thinking. We surveyed the past three years of publications from leading HCI venues. We closely examined 11 AI-assisted research tools, five employing traditional AI approaches and six integrating GenAI, to explore how these systems envision novel capabilities and design spaces. We consolidate four design recommendations that inform cognitive engagement when working with an AI research tool: Providing user agency and control; enabling divergent and convergent thinking; supporting adaptability and flexibility; and ensuring transparency and accuracy. We discuss how these ideas mark a shift in AI-assisted research tools from mimicking a researcher's established workflows to generative co-creation with the researcher and the opportunities this shift affords the research community.
Understanding Help-Seeking Behavior of Students Using LLMs vs. Web Search for Writing SQL Queries
Aug 15, 2024

Growth in the use of large language models (LLMs) in programming education is altering how students write SQL queries. Traditionally, students relied heavily on web search for coding assistance, but this has shifted with the adoption of LLMs like ChatGPT. However, the comparative process and outcomes of using web search versus LLMs for coding help remain underexplored. To address this, we conducted a randomized interview study in a database classroom to compare web search and LLMs, including a publicly available LLM (ChatGPT) and an instructor-tuned LLM, for writing SQL queries. Our findings indicate that using an instructor-tuned LLM required significantly more interactions than both ChatGPT and web search, but resulted in a similar number of edits to the final SQL query. No significant differences were found in the quality of the final SQL queries between conditions, although the LLM conditions directionally showed higher query quality. Furthermore, students using instructor-tuned LLM reported a lower mental demand. These results have implications for learning and productivity in programming education.
Opportunities for Adaptive Experiments to Enable Continuous Improvement that Trades-off Instructor and Researcher Incentives
Oct 18, 2023



Randomized experimental comparisons of alternative pedagogical strategies could provide useful empirical evidence in instructors' decision-making. However, traditional experiments do not have a clear and simple pathway to using data rapidly to try to increase the chances that students in an experiment get the best conditions. Drawing inspiration from the use of machine learning and experimentation in product development at leading technology companies, we explore how adaptive experimentation might help in continuous course improvement. In adaptive experiments, as different arms/conditions are deployed to students, data is analyzed and used to change the experience for future students. This can be done using machine learning algorithms to identify which actions are more promising for improving student experience or outcomes. This algorithm can then dynamically deploy the most effective conditions to future students, resulting in better support for students' needs. We illustrate the approach with a case study providing a side-by-side comparison of traditional and adaptive experimentation of self-explanation prompts in online homework problems in a CS1 course. This provides a first step in exploring the future of how this methodology can be useful in bridging research and practice in doing continuous improvement.
Impact of Guidance and Interaction Strategies for LLM Use on Learner Performance and Perception
Oct 13, 2023Personalized chatbot-based teaching assistants can be crucial in addressing increasing classroom sizes, especially where direct teacher presence is limited. Large language models (LLMs) offer a promising avenue, with increasing research exploring their educational utility. However, the challenge lies not only in establishing the efficacy of LLMs but also in discerning the nuances of interaction between learners and these models, which impact learners' engagement and results. We conducted a formative study in an undergraduate computer science classroom (N=145) and a controlled experiment on Prolific (N=356) to explore the impact of four pedagogically informed guidance strategies and the interaction between student approaches and LLM responses. Direct LLM answers marginally improved performance, while refining student solutions fostered trust. Our findings suggest a nuanced relationship between the guidance provided and LLM's role in either answering or refining student input. Based on our findings, we provide design recommendations for optimizing learner-LLM interactions.