 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlagiarism and AI Assistance Misuse in Web Programming: Unfair Benefits and Characteristics
Oct 31, 2023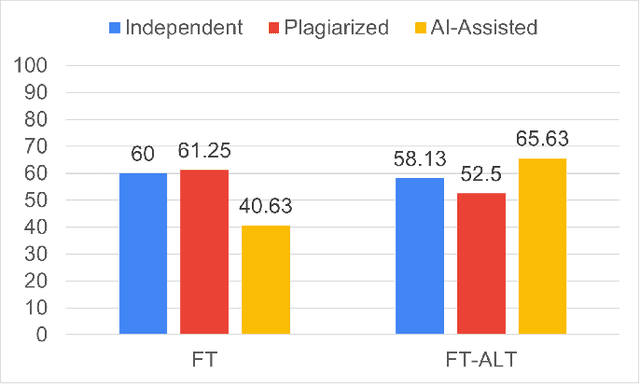
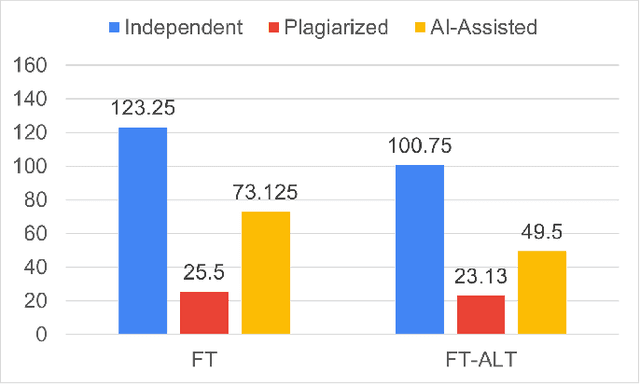
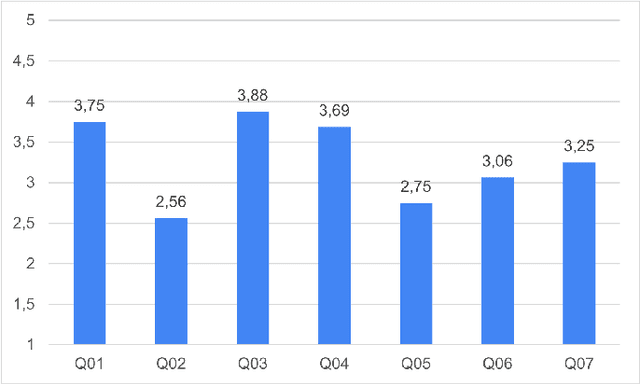

In programming education, plagiarism and misuse of artificial intelligence (AI) assistance are emerging issues. However, not many relevant studies are focused on web programming. We plan to develop automated tools to help instructors identify both misconducts. To fully understand the issues, we conducted a controlled experiment to observe the unfair benefits and the characteristics. We compared student performance in completing web programming tasks independently, with a submission to plagiarize, and with the help of AI assistance (ChatGPT). Our study shows that students who are involved in such misconducts get comparable test marks with less completion time. Plagiarized submissions are similar to the independent ones except in trivial aspects such as color and identifier names. AI-assisted submissions are more complex, making them less readable. Students believe AI assistance could be useful given proper acknowledgment of the use, although they are not convinced with readability and correctness of the solutions.
Detecting LLM-Generated Text in Computing Education: A Comparative Study for ChatGPT Cases
Jul 10, 2023



Due to the recent improvements and wide availability of Large Language Models (LLMs), they have posed a serious threat to academic integrity in education. Modern LLM-generated text detectors attempt to combat the problem by offering educators with services to assess whether some text is LLM-generated. In this work, we have collected 124 submissions from computer science students before the creation of ChatGPT. We then generated 40 ChatGPT submissions. We used this data to evaluate eight publicly-available LLM-generated text detectors through the measures of accuracy, false positives, and resilience. The purpose of this work is to inform the community of what LLM-generated text detectors work and which do not, but also to provide insights for educators to better maintain academic integrity in their courses. Our results find that CopyLeaks is the most accurate LLM-generated text detector, GPTKit is the best LLM-generated text detector to reduce false positives, and GLTR is the most resilient LLM-generated text detector. We also express concerns over 52 false positives (of 114 human written submissions) generated by GPTZero. Finally, we note that all LLM-generated text detectors are less accurate with code, other languages (aside from English), and after the use of paraphrasing tools (like QuillBot). Modern detectors are still in need of improvements so that they can offer a full-proof solution to help maintain academic integrity. Further, their usability can be improved by facilitating a smooth API integration, providing clear documentation of their features and the understandability of their model(s), and supporting more commonly used languages.