 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAPTS: A Weighted Allocation Probability Adjusted Thompson Sampling Algorithm for High-Dimensional and Sparse Experiment Settings
Jan 07, 2025Aiming for more effective experiment design, such as in video content advertising where different content options compete for user engagement, these scenarios can be modeled as multi-arm bandit problems. In cases where limited interactions are available due to external factors, such as the cost of conducting experiments, recommenders often face constraints due to the small number of user interactions. In addition, there is a trade-off between selecting the best treatment and the ability to personalize and contextualize based on individual factors. A popular solution to this dilemma is the Contextual Bandit framework. It aims to maximize outcomes while incorporating personalization (contextual) factors, customizing treatments such as a user's profile to individual preferences. Despite their advantages, Contextual Bandit algorithms face challenges like measurement bias and the 'curse of dimensionality.' These issues complicate the management of numerous interventions and often lead to data sparsity through participant segmentation. To address these problems, we introduce the Weighted Allocation Probability Adjusted Thompson Sampling (WAPTS) algorithm. WAPTS builds on the contextual Thompson Sampling method by using a dynamic weighting parameter. This improves the allocation process for interventions and enables rapid optimization in data-sparse environments. We demonstrate the performance of our approach on different numbers of arms and effect sizes.
Using Adaptive Bandit Experiments to Increase and Investigate Engagement in Mental Health
Oct 13, 2023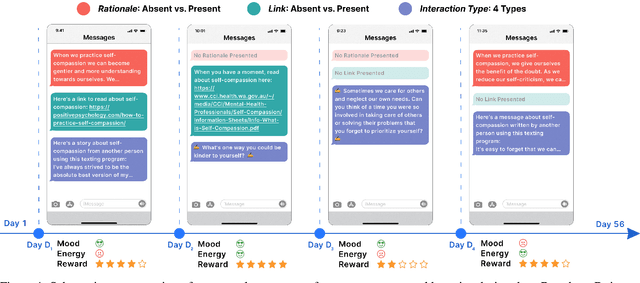

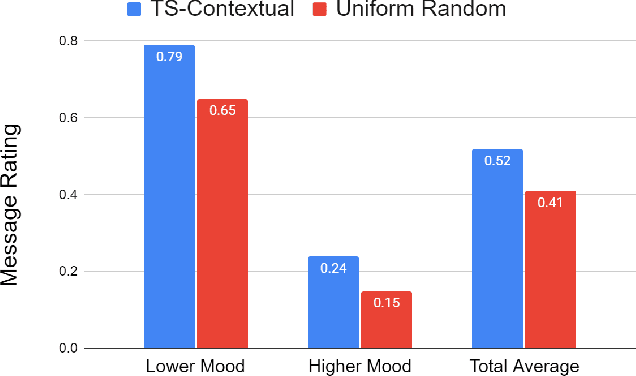

Digital mental health (DMH) interventions, such as text-message-based lessons and activities, offer immense potential for accessible mental health support. While these interventions can be effective, real-world experimental testing can further enhance their design and impact. Adaptive experimentation, utilizing algorithms like Thompson Sampling for (contextual) multi-armed bandit (MAB) problems, can lead to continuous improvement and personalization. However, it remains unclear when these algorithms can simultaneously increase user experience rewards and facilitate appropriate data collection for social-behavioral scientists to analyze with sufficient statistical confidence. Although a growing body of research addresses the practical and statistical aspects of MAB and other adaptive algorithms, further exploration is needed to assess their impact across diverse real-world contexts. This paper presents a software system developed over two years that allows text-messaging intervention components to be adapted using bandit and other algorithms while collecting data for side-by-side comparison with traditional uniform random non-adaptive experiments. We evaluate the system by deploying a text-message-based DMH intervention to 1100 users, recruited through a large mental health non-profit organization, and share the path forward for deploying this system at scale. This system not only enables applications in mental health but could also serve as a model testbed for adaptive experimentation algorithms in other domains.
Using Adaptive Experiments to Rapidly Help Students
Aug 10, 2022Adaptive experiments can increase the chance that current students obtain better outcomes from a field experiment of an instructional intervention. In such experiments, the probability of assigning students to conditions changes while more data is being collected, so students can be assigned to interventions that are likely to perform better. Digital educational environments lower the barrier to conducting such adaptive experiments, but they are rarely applied in education. One reason might be that researchers have access to few real-world case studies that illustrate the advantages and disadvantages of these experiments in a specific context. We evaluate the effect of homework email reminders in students by conducting an adaptive experiment using the Thompson Sampling algorithm and compare it to a traditional uniform random experiment. We present this as a case study on how to conduct such experiments, and we raise a range of open questions about the conditions under which adaptive randomized experiments may be more or less useful.
Increasing Students' Engagement to Reminder Emails Through Multi-Armed Bandits
Aug 10, 2022
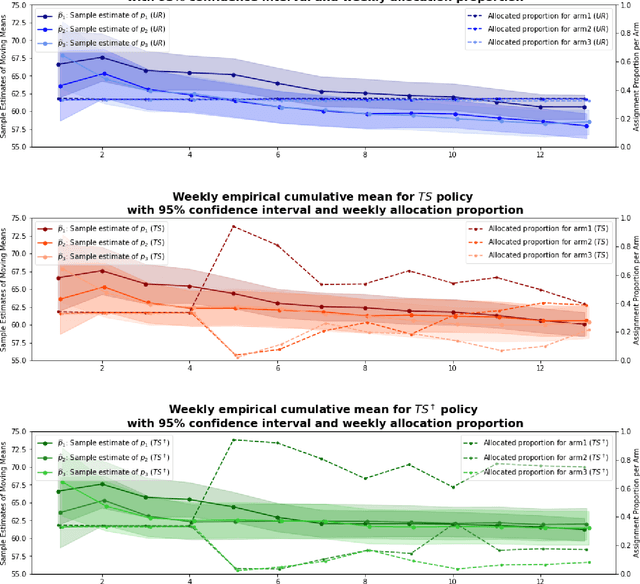


Conducting randomized experiments in education settings raises the question of how we can use machine learning techniques to improve educational interventions. Using Multi-Armed Bandits (MAB) algorithms like Thompson Sampling (TS) in adaptive experiments can increase students' chances of obtaining better outcomes by increasing the probability of assignment to the most optimal condition (arm), even before an intervention completes. This is an advantage over traditional A/B testing, which may allocate an equal number of students to both optimal and non-optimal conditions. The problem is the exploration-exploitation trade-off. Even though adaptive policies aim to collect enough information to allocate more students to better arms reliably, past work shows that this may not be enough exploration to draw reliable conclusions about whether arms differ. Hence, it is of interest to provide additional uniform random (UR) exploration throughout the experiment. This paper shows a real-world adaptive experiment on how students engage with instructors' weekly email reminders to build their time management habits. Our metric of interest is open email rates which tracks the arms represented by different subject lines. These are delivered following different allocation algorithms: UR, TS, and what we identified as TS{\dag} - which combines both TS and UR rewards to update its priors. We highlight problems with these adaptive algorithms - such as possible exploitation of an arm when there is no significant difference - and address their causes and consequences. Future directions includes studying situations where the early choice of the optimal arm is not ideal and how adaptive algorithms can address them.
Algorithms for Adaptive Experiments that Trade-off Statistical Analysis with Reward: Combining Uniform Random Assignment and Reward Maximization
Dec 21, 2021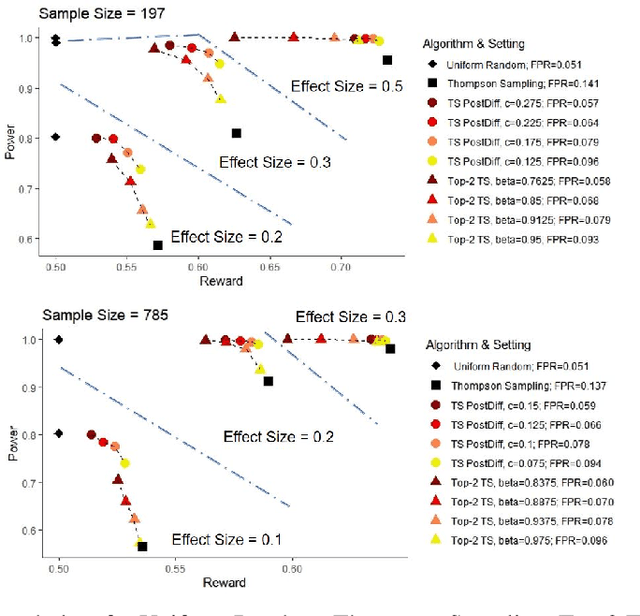
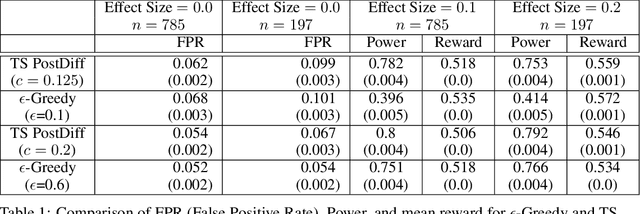
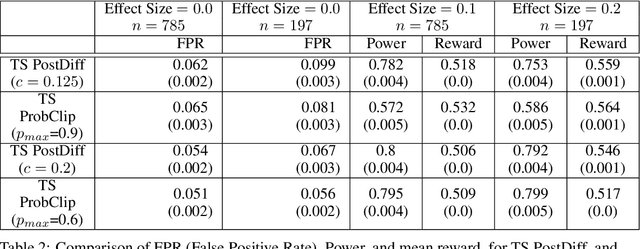
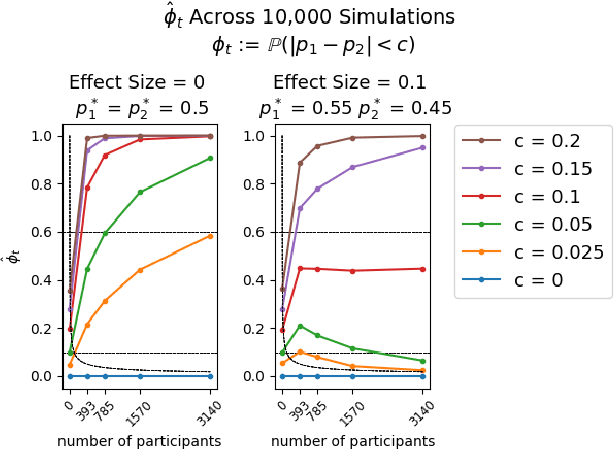
Multi-armed bandit algorithms like Thompson Sampling can be used to conduct adaptive experiments, in which maximizing reward means that data is used to progressively assign more participants to more effective arms. Such assignment strategies increase the risk of statistical hypothesis tests identifying a difference between arms when there is not one, and failing to conclude there is a difference in arms when there truly is one. We present simulations for 2-arm experiments that explore two algorithms that combine the benefits of uniform randomization for statistical analysis, with the benefits of reward maximization achieved by Thompson Sampling (TS). First, Top-Two Thompson Sampling adds a fixed amount of uniform random allocation (UR) spread evenly over time. Second, a novel heuristic algorithm, called TS PostDiff (Posterior Probability of Difference). TS PostDiff takes a Bayesian approach to mixing TS and UR: the probability a participant is assigned using UR allocation is the posterior probability that the difference between two arms is `small' (below a certain threshold), allowing for more UR exploration when there is little or no reward to be gained. We find that TS PostDiff method performs well across multiple effect sizes, and thus does not require tuning based on a guess for the true effect size.
Challenges in Statistical Analysis of Data Collected by a Bandit Algorithm: An Empirical Exploration in Applications to Adaptively Randomized Experiments
Mar 26, 2021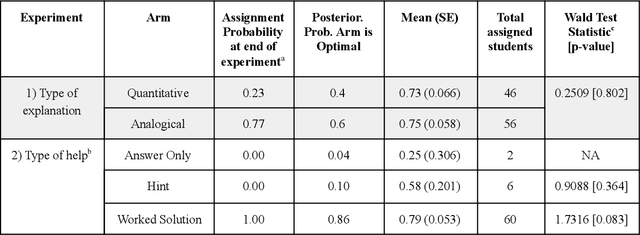
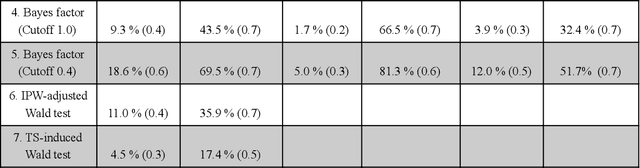
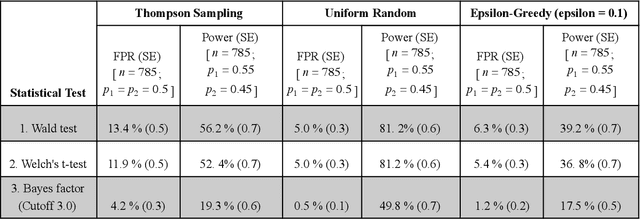
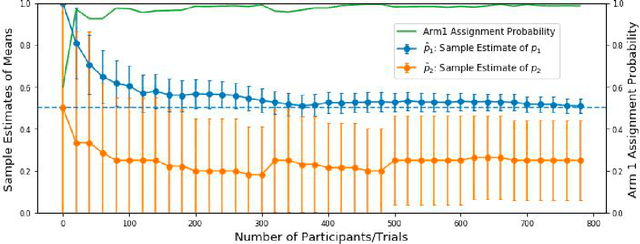
Multi-armed bandit algorithms have been argued for decades as useful for adaptively randomized experiments. In such experiments, an algorithm varies which arms (e.g. alternative interventions to help students learn) are assigned to participants, with the goal of assigning higher-reward arms to as many participants as possible. We applied the bandit algorithm Thompson Sampling (TS) to run adaptive experiments in three university classes. Instructors saw great value in trying to rapidly use data to give their students in the experiments better arms (e.g. better explanations of a concept). Our deployment, however, illustrated a major barrier for scientists and practitioners to use such adaptive experiments: a lack of quantifiable insight into how much statistical analysis of specific real-world experiments is impacted (Pallmann et al, 2018; FDA, 2019), compared to traditional uniform random assignment. We therefore use our case study of the ubiquitous two-arm binary reward setting to empirically investigate the impact of using Thompson Sampling instead of uniform random assignment. In this setting, using common statistical hypothesis tests, we show that collecting data with TS can as much as double the False Positive Rate (FPR; incorrectly reporting differences when none exist) and the False Negative Rate (FNR; failing to report differences when they exist)...