 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Adaptive Experiments to Rapidly Help Students
Aug 10, 2022Adaptive experiments can increase the chance that current students obtain better outcomes from a field experiment of an instructional intervention. In such experiments, the probability of assigning students to conditions changes while more data is being collected, so students can be assigned to interventions that are likely to perform better. Digital educational environments lower the barrier to conducting such adaptive experiments, but they are rarely applied in education. One reason might be that researchers have access to few real-world case studies that illustrate the advantages and disadvantages of these experiments in a specific context. We evaluate the effect of homework email reminders in students by conducting an adaptive experiment using the Thompson Sampling algorithm and compare it to a traditional uniform random experiment. We present this as a case study on how to conduct such experiments, and we raise a range of open questions about the conditions under which adaptive randomized experiments may be more or less useful.
Challenges in Statistical Analysis of Data Collected by a Bandit Algorithm: An Empirical Exploration in Applications to Adaptively Randomized Experiments
Mar 26, 2021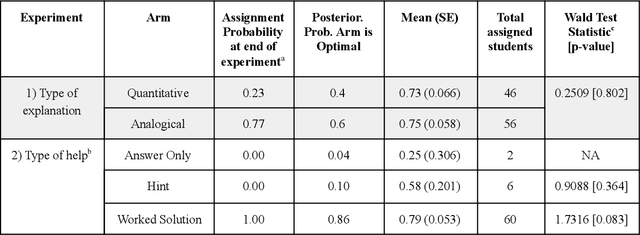
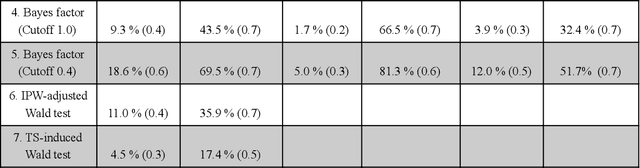
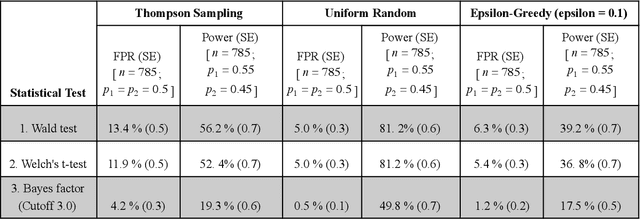
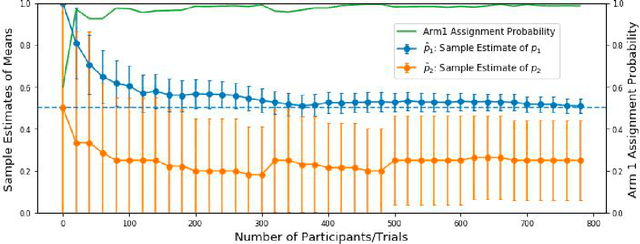
Multi-armed bandit algorithms have been argued for decades as useful for adaptively randomized experiments. In such experiments, an algorithm varies which arms (e.g. alternative interventions to help students learn) are assigned to participants, with the goal of assigning higher-reward arms to as many participants as possible. We applied the bandit algorithm Thompson Sampling (TS) to run adaptive experiments in three university classes. Instructors saw great value in trying to rapidly use data to give their students in the experiments better arms (e.g. better explanations of a concept). Our deployment, however, illustrated a major barrier for scientists and practitioners to use such adaptive experiments: a lack of quantifiable insight into how much statistical analysis of specific real-world experiments is impacted (Pallmann et al, 2018; FDA, 2019), compared to traditional uniform random assignment. We therefore use our case study of the ubiquitous two-arm binary reward setting to empirically investigate the impact of using Thompson Sampling instead of uniform random assignment. In this setting, using common statistical hypothesis tests, we show that collecting data with TS can as much as double the False Positive Rate (FPR; incorrectly reporting differences when none exist) and the False Negative Rate (FNR; failing to report differences when they exist)...