 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Contrastive Reflection Enables Rapid Improvements in Reasoning
May 27, 2026Language models can use verifiable rewards to improve at a wide variety of reasoning tasks. However, both parametric (e.g. RLVR) and non-parametric (e.g. prompt optimization) approaches to doing so typically require hundreds of training samples and thousands of model rollouts, making them expensive in the best case and intractable in the worst. To address this challenge, we introduce Contrastive Reflection (CORE), a non-parametric learning algorithm that compares past reasoning traces to generate insights: short natural-language descriptions of reasoning strategies and constraints that capture differences between successful and unsuccessful problem attempts. Across four reasoning tasks, we demonstrate that CORE enables more rapid improvement than both parametric (GRPO) and non-parametric (GEPA, episodic RAG, and MemRL) methods, while using fewer rollouts. Under fixed rollout budgets with as few as five training samples, we then show that CORE also achieves comparable or greater performance gains than each baseline. Finally, we highlight how CORE is also substantially more context-efficient than non-parametric baselines, requiring fewer prompt tokens while storing learned knowledge as compact, interpretable natural-language insights. Our results therefore suggest that distilling contrasts between successful and unsuccessful reasoning traces into abstract and useful insights can provide a more efficient and interpretable route to model self-improvement than weight updates, prompt optimization, or direct reuse of stored reasoning traces.
Context informs pragmatic interpretation in vision-language models
Nov 05, 2025Iterated reference games - in which players repeatedly pick out novel referents using language - present a test case for agents' ability to perform context-sensitive pragmatic reasoning in multi-turn linguistic environments. We tested humans and vision-language models on trials from iterated reference games, varying the given context in terms of amount, order, and relevance. Without relevant context, models were above chance but substantially worse than humans. However, with relevant context, model performance increased dramatically over trials. Few-shot reference games with abstract referents remain a difficult task for machine learning models.
Scaling up the think-aloud method
May 29, 2025The think-aloud method, where participants voice their thoughts as they solve a task, is a valuable source of rich data about human reasoning processes. Yet, it has declined in popularity in contemporary cognitive science, largely because labor-intensive transcription and annotation preclude large sample sizes. Here, we develop methods to automate the transcription and annotation of verbal reports of reasoning using natural language processing tools, allowing for large-scale analysis of think-aloud data. In our study, 640 participants thought aloud while playing the Game of 24, a mathematical reasoning task. We automatically transcribed the recordings and coded the transcripts as search graphs, finding moderate inter-rater reliability with humans. We analyze these graphs and characterize consistency and variation in human reasoning traces. Our work demonstrates the value of think-aloud data at scale and serves as a proof of concept for the automated analysis of verbal reports.
Why think step-by-step? Reasoning emerges from the locality of experience
Apr 07, 2023Humans have a powerful and mysterious capacity to reason. By working through a series of purely mental steps, we can make inferences we would not be capable of making directly -- despite that fact that we get no additional data from the world. Similarly, large language models can perform better at complex tasks through chain-of-thought reasoning, where they generate intermediate steps before answering a question. We use language models to investigate the questions of when and why reasoning is helpful, testing the hypothesis that reasoning is effective when training data consisting of local clusters of variables that influence each other strongly. These training conditions enable the chaining of accurate local inferences in order to estimate relationships between variables that were not seen together in training. We train an autoregressive transformer on samples from joint distributions defined by Bayes nets, but only include a subset of all the variables in each sample. We compare language models' ability to match conditional probabilities both with and without intermediate reasoning steps, finding that intermediate steps help only when the training data is locally structured with respect to dependencies between variables. Furthermore, intermediate variables need to be relevant to the relationship between observed information and target inferences. Our results illustrate how the statistical structure of training data drives the effectiveness of reasoning step by step.
Toward a normative theory of management by goal-setting
Feb 06, 2023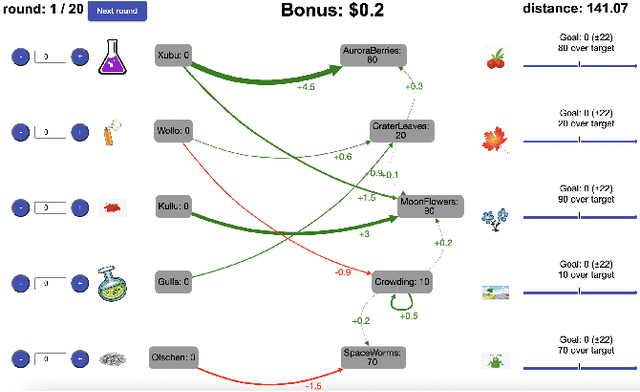
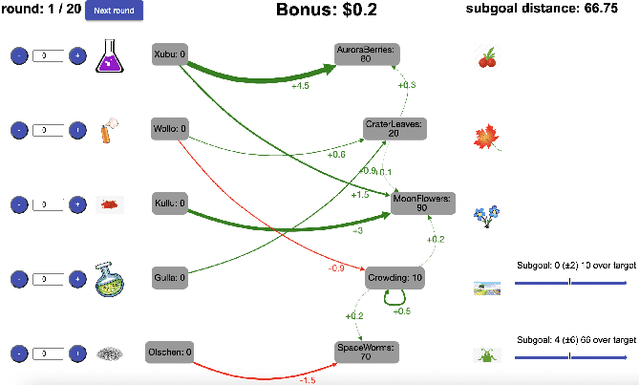
People are often confronted with problems whose complexity exceeds their cognitive capacities. To deal with this complexity, individuals and managers can break complex problems down into a series of subgoals. Which subgoals are most effective depends on people's cognitive constraints and the cognitive mechanisms of goal pursuit. This creates an untapped opportunity to derive practical recommendations for which subgoals managers and individuals should set from cognitive models of bounded rationality. To seize this opportunity, we apply the principle of resource-rationality to formulate a mathematically precise normative theory of (self-)management by goal-setting. We leverage this theory to computationally derive optimal subgoals from a resource-rational model of human goal pursuit. Finally, we show that the resulting subgoals improve the problem-solving performance of bounded agents and human participants. This constitutes a first step towards grounding prescriptive theories of management and practical recommendations for goal-setting in computational models of the relevant psychological processes and cognitive limitations.
Psychologically-informed chain-of-thought prompts for metaphor understanding in large language models
Sep 16, 2022


Probabilistic models of language understanding are interpretable and structured, for instance models of metaphor understanding describe inference about latent topics and features. However, these models are manually designed for a specific task. Large language models (LLMs) can perform many tasks through in-context learning, but they lack the clear structure of probabilistic models. In this paper, we use chain-of-thought prompts to introduce structures from probabilistic models into LLMs. These prompts lead the model to infer latent variables and reason about their relationships to choose appropriate paraphrases for metaphors. The latent variables and relationships chosen are informed by theories of metaphor understanding from cognitive psychology. We apply these prompts to the two largest versions of GPT-3 and show that they can improve paraphrase selection.
Algorithms for Adaptive Experiments that Trade-off Statistical Analysis with Reward: Combining Uniform Random Assignment and Reward Maximization
Dec 21, 2021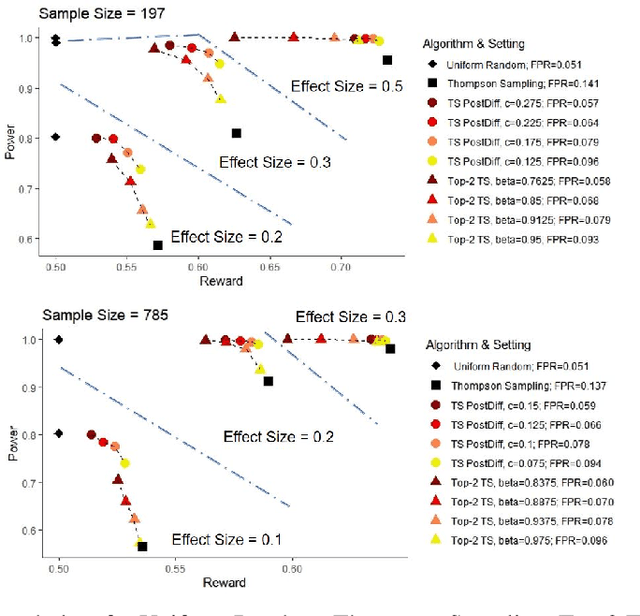
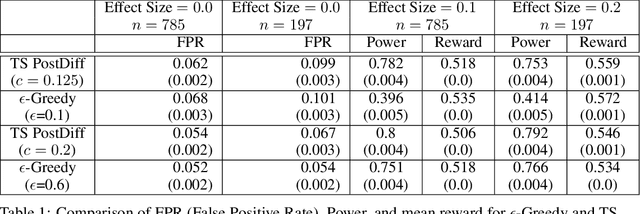
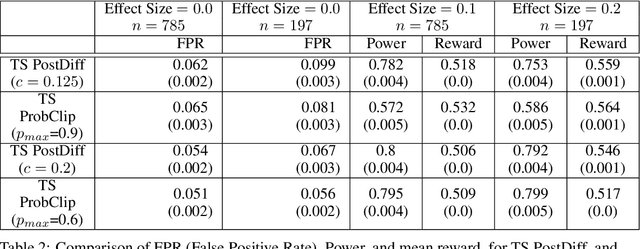
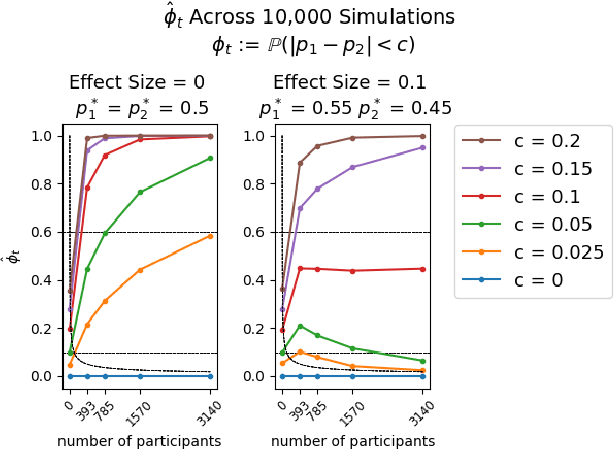
Multi-armed bandit algorithms like Thompson Sampling can be used to conduct adaptive experiments, in which maximizing reward means that data is used to progressively assign more participants to more effective arms. Such assignment strategies increase the risk of statistical hypothesis tests identifying a difference between arms when there is not one, and failing to conclude there is a difference in arms when there truly is one. We present simulations for 2-arm experiments that explore two algorithms that combine the benefits of uniform randomization for statistical analysis, with the benefits of reward maximization achieved by Thompson Sampling (TS). First, Top-Two Thompson Sampling adds a fixed amount of uniform random allocation (UR) spread evenly over time. Second, a novel heuristic algorithm, called TS PostDiff (Posterior Probability of Difference). TS PostDiff takes a Bayesian approach to mixing TS and UR: the probability a participant is assigned using UR allocation is the posterior probability that the difference between two arms is `small' (below a certain threshold), allowing for more UR exploration when there is little or no reward to be gained. We find that TS PostDiff method performs well across multiple effect sizes, and thus does not require tuning based on a guess for the true effect size.