 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederatedFactory: Generative One-Shot Learning for Extremely Non-IID Distributed Scenarios
Mar 17, 2026Federated Learning (FL) enables distributed optimization without compromising data sovereignty. Yet, where local label distributions are mutually exclusive, standard weight aggregation fails due to conflicting optimization trajectories. Often, FL methods rely on pretrained foundation models, introducing unrealistic assumptions. We introduce FederatedFactory, a zero-dependency framework that inverts the unit of federation from discriminative parameters to generative priors. By exchanging generative modules in a single communication round, our architecture supports ex nihilo synthesis of universally class balanced datasets, eliminating gradient conflict and external prior bias entirely. Evaluations across diverse medical imagery benchmarks, including MedMNIST and ISIC2019, demonstrate that our approach recovers centralized upper-bound performance. Under pathological heterogeneity, it lifts baseline accuracy from a collapsed 11.36% to 90.57% on CIFAR-10 and restores ISIC2019 AUROC to 90.57%. Additionally, this framework facilitates exact modular unlearning through the deterministic deletion of specific generative modules.
Amnesia: Adversarial Semantic Layer Specific Activation Steering in Large Language Models
Mar 10, 2026Warning: This article includes red-teaming experiments, which contain examples of compromised LLM responses that may be offensive or upsetting. Large Language Models (LLMs) have the potential to create harmful content, such as generating sophisticated phishing emails and assisting in writing code of harmful computer viruses. Thus, it is crucial to ensure their safe and responsible response generation. To reduce the risk of generating harmful or irresponsible content, researchers have developed techniques such as reinforcement learning with human feedback to align LLM's outputs with human values and preferences. However, it is still undetermined whether such measures are sufficient to prevent LLMs from generating interesting responses. In this study, we propose Amnesia, a lightweight activation-space adversarial attack that manipulates internal transformer states to bypass existing safety mechanisms in open-weight LLMs. Through experimental analysis on state-of-the-art, open-weight LLMs, we demonstrate that our attack effectively circumvents existing safeguards, enabling the generation of harmful content without the need for any fine-tuning or additional training. Our experiments on benchmark datasets show that the proposed attack can induce various antisocial behaviors in LLMs. These findings highlight the urgent need for more robust security measures in open-weight LLMs and underscore the importance of continued research to prevent their potential misuse.
LADFA: A Framework of Using Large Language Models and Retrieval-Augmented Generation for Personal Data Flow Analysis in Privacy Policies
Jan 15, 2026Privacy policies help inform people about organisations' personal data processing practices, covering different aspects such as data collection, data storage, and sharing of personal data with third parties. Privacy policies are often difficult for people to fully comprehend due to the lengthy and complex legal language used and inconsistent practices across different sectors and organisations. To help conduct automated and large-scale analyses of privacy policies, many researchers have studied applications of machine learning and natural language processing techniques, including large language models (LLMs). While a limited number of prior studies utilised LLMs for extracting personal data flows from privacy policies, our approach builds on this line of work by combining LLMs with retrieval-augmented generation (RAG) and a customised knowledge base derived from existing studies. This paper presents the development of LADFA, an end-to-end computational framework, which can process unstructured text in a given privacy policy, extract personal data flows and construct a personal data flow graph, and conduct analysis of the data flow graph to facilitate insight discovery. The framework consists of a pre-processor, an LLM-based processor, and a data flow post-processor. We demonstrated and validated the effectiveness and accuracy of the proposed approach by conducting a case study that involved examining ten selected privacy policies from the automotive industry. Moreover, it is worth noting that LADFA is designed to be flexible and customisable, making it suitable for a range of text-based analysis tasks beyond privacy policy analysis.
TeraRIS NOMA-MIMO Communications for 6G and Beyond Industrial Networks
Aug 07, 2025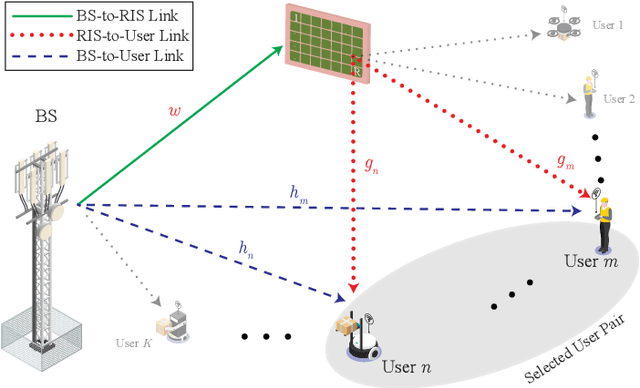
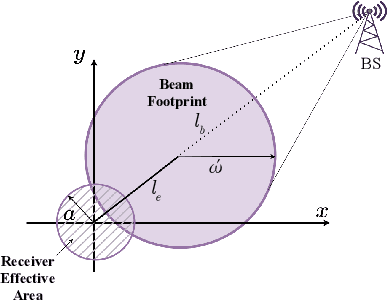
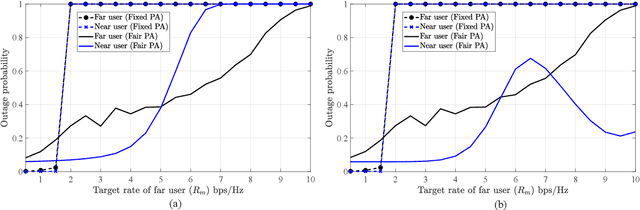
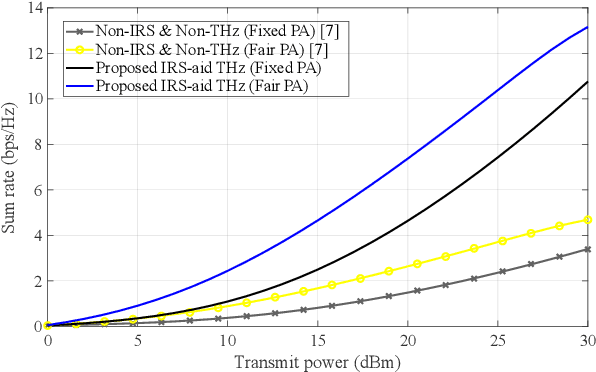
This paper presents a joint framework that integrates reconfigurable intelligent surfaces (RISs) with Terahertz (THz) communications and non-orthogonal multiple access (NOMA) to enhance smart industrial communications. The proposed system leverages the advantages of RIS and THz bands to improve spectral efficiency, coverage, and reliability key requirements for industrial automation and real-time communications in future 6G networks and beyond. Within this framework, two power allocation strategies are investigated: the first optimally distributes power between near and far industrial nodes, and the second prioritizes network demands to enhance system performance further. A performance evaluation is conducted to compare the sum rate and outage probability against a fixed power allocation scheme. Our scheme achieves up to a 23% sum rate gain over fixed PA at 30 dBm. Simulation results validate the theoretical analysis, demonstrating the effectiveness and robustness of the RIS-assisted NOMA MIMO framework for THz enabled industrial communications.
A Novel Labeled Human Voice Signal Dataset for Misbehavior Detection
Jun 28, 2024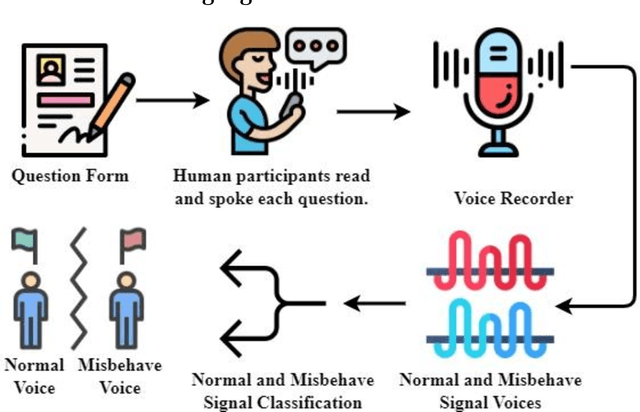
Voice signal classification based on human behaviours involves analyzing various aspects of speech patterns and delivery styles. In this study, a real-time dataset collection is performed where participants are instructed to speak twelve psychology questions in two distinct manners: first, in a harsh voice, which is categorized as "misbehaved"; and second, in a polite manner, categorized as "normal". These classifications are crucial in understanding how different vocal behaviours affect the interpretation and classification of voice signals. This research highlights the significance of voice tone and delivery in automated machine-learning systems for voice analysis and recognition. This research contributes to the broader field of voice signal analysis by elucidating the impact of human behaviour on the perception and categorization of voice signals, thereby enhancing the development of more accurate and context-aware voice recognition technologies.
Abstractive Summary Generation for the Urdu Language
May 25, 2023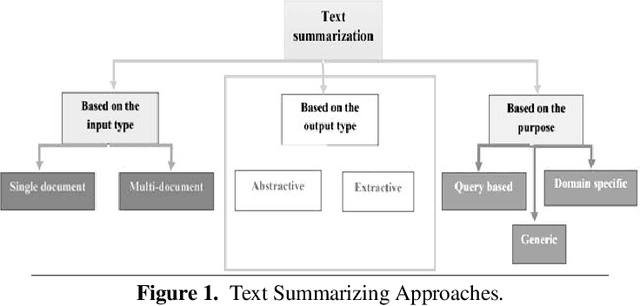



Abstractive summary generation is a challenging task that requires the model to comprehend the source text and generate a concise and coherent summary that captures the essential information. In this paper, we explore the use of an encoder/decoder approach for abstractive summary generation in the Urdu language. We employ a transformer-based model that utilizes self-attention mechanisms to encode the input text and generate a summary. Our experiments show that our model can produce summaries that are grammatically correct and semantically meaningful. We evaluate our model on a publicly available dataset and achieve state-of-the-art results in terms of Rouge scores. We also conduct a qualitative analysis of our model's output to assess its effectiveness and limitations. Our findings suggest that the encoder/decoder approach is a promising method for abstractive summary generation in Urdu and can be extended to other languages with suitable modifications.
Proof of Swarm Based Ensemble Learning for Federated Learning Applications
Jan 02, 2023



Ensemble learning combines results from multiple machine learning models in order to provide a better and optimised predictive model with reduced bias, variance and improved predictions. However, in federated learning it is not feasible to apply centralised ensemble learning directly due to privacy concerns. Hence, a mechanism is required to combine results of local models to produce a global model. Most distributed consensus algorithms, such as Byzantine fault tolerance (BFT), do not normally perform well in such applications. This is because, in such methods predictions of some of the peers are disregarded, so a majority of peers can win without even considering other peers' decisions. Additionally, the confidence score of the result of each peer is not normally taken into account, although it is an important feature to consider for ensemble learning. Moreover, the problem of a tie event is often left un-addressed by methods such as BFT. To fill these research gaps, we propose PoSw (Proof of Swarm), a novel distributed consensus algorithm for ensemble learning in a federated setting, which was inspired by particle swarm based algorithms for solving optimisation problems. The proposed algorithm is theoretically proved to always converge in a relatively small number of steps and has mechanisms to resolve tie events while trying to achieve sub-optimum solutions. We experimentally validated the performance of the proposed algorithm using ECG classification as an example application in healthcare, showing that the ensemble learning model outperformed all local models and even the FL-based global model. To the best of our knowledge, the proposed algorithm is the first attempt to make consensus over the output results of distributed models trained using federated learning.
Detection of Poisoning Attacks with Anomaly Detection in Federated Learning for Healthcare Applications: A Machine Learning Approach
Jul 18, 2022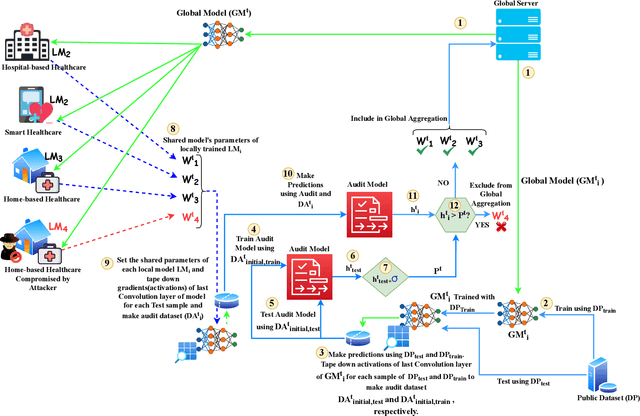
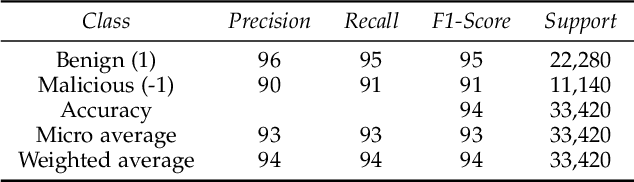
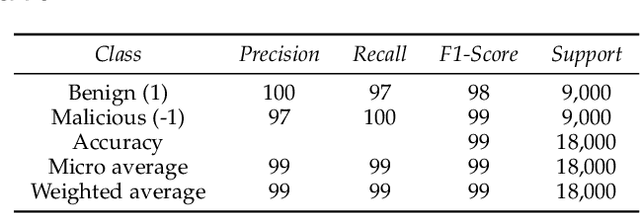
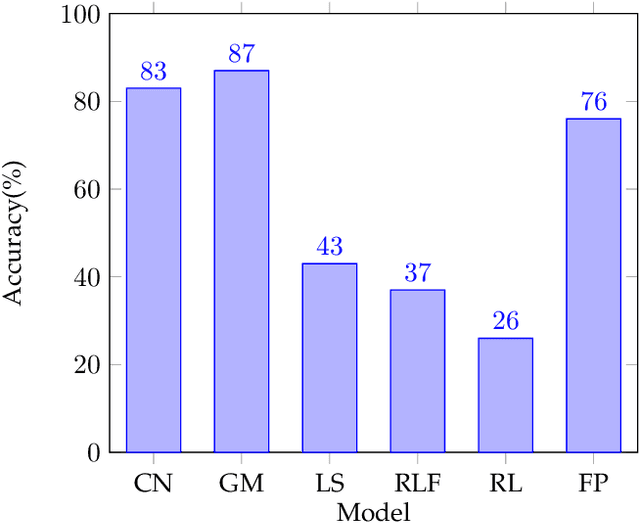
The application of Federated Learning (FL) is steadily increasing, especially in privacy-aware applications, such as healthcare. However, its applications have been limited by security concerns due to various adversarial attacks, such as poisoning attacks (model and data poisoning). Such attacks attempt to poison the local models and data to manipulate the global models in order to obtain undue benefits and malicious use. Traditional methods of data auditing to mitigate poisoning attacks find their limited applications in FL because the edge devices never share their raw data directly due to privacy concerns, and are globally distributed with no insight into their training data. Thereafter, it is challenging to develop appropriate strategies to address such attacks and minimize their impact on the global model in federated learning. In order to address such challenges in FL, we proposed a novel framework to detect poisoning attacks using deep neural networks and support vector machines, in the form of anomaly without acquiring any direct access or information about the underlying training data of local edge devices. We illustrate and evaluate the proposed framework using different state of art poisoning attacks for two different healthcare applications: Electrocardiograph classification and human activity recognition. Our experimental analysis shows that the proposed method can efficiently detect poisoning attacks and can remove the identified poisoned updated from the global aggregation. Thereafter can increase the performance of the federated global.
Non-equilibrium molecular geometries in graph neural networks
Mar 07, 2022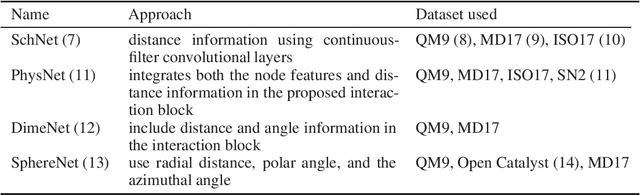
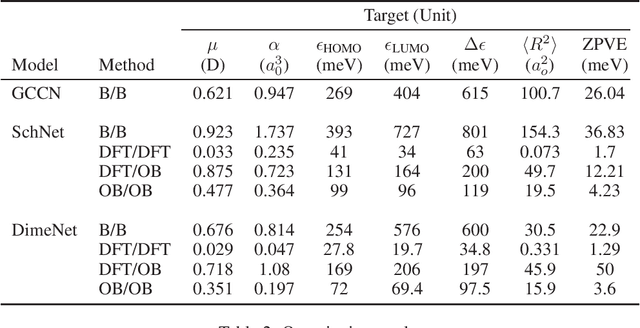
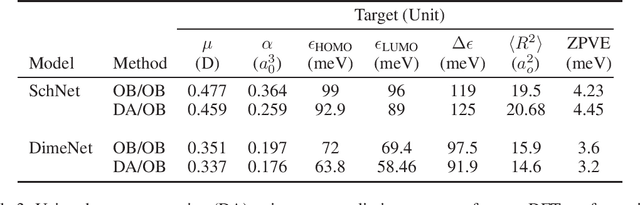
Graph neural networks have become a powerful framework for learning complex structure-property relationships and fast screening of chemical compounds. Recently proposed methods have demonstrated that using 3D geometry information of the molecule along with the bonding structure can lead to more accurate prediction on a wide range of properties. A common practice is to use 3D geometries computed through density functional theory (DFT) for both training and testing of models. However, the computational time needed for DFT calculations can be prohibitively large. Moreover, many of the properties that we aim to predict can often be obtained with little or no overhead on top of the DFT calculations used to produce the 3D geometry information, voiding the need for a predictive model. To be practically useful for high-throughput chemical screening and drug discovery, it is desirable to work with 3D geometries obtained using less-accurate but much more efficient non-DFT methods. In this work we investigate the impact of using non-DFT conformations in the training and the testing of existing models and propose a data augmentation method for improving the prediction accuracy of classical forcefield-derived geometries.
Deep Camera Pose Regression Using Pseudo-LiDAR
Feb 28, 2022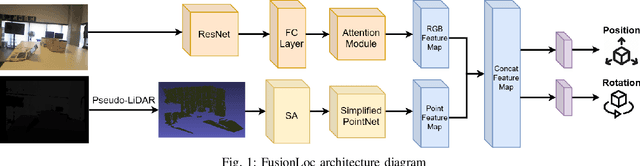

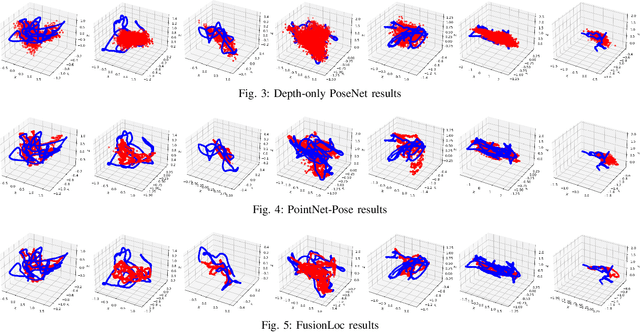
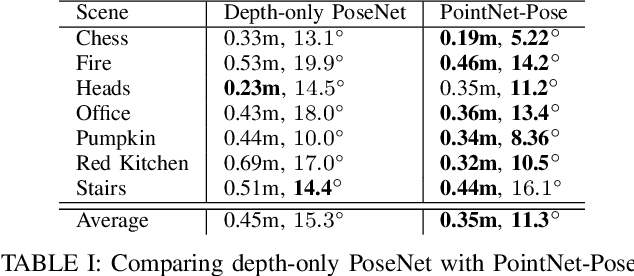
An accurate and robust large-scale localization system is an integral component for active areas of research such as autonomous vehicles and augmented reality. To this end, many learning algorithms have been proposed that predict 6DOF camera pose from RGB or RGB-D images. However, previous methods that incorporate depth typically treat the data the same way as RGB images, often adding depth maps as additional channels to RGB images and passing them through convolutional neural networks (CNNs). In this paper, we show that converting depth maps into pseudo-LiDAR signals, previously shown to be useful for 3D object detection, is a better representation for camera localization tasks by projecting point clouds that can accurately determine 6DOF camera pose. This is demonstrated by first comparing localization accuracies of a network operating exclusively on pseudo-LiDAR representations, with networks operating exclusively on depth maps. We then propose FusionLoc, a novel architecture that uses pseudo-LiDAR to regress a 6DOF camera pose. FusionLoc is a dual stream neural network, which aims to remedy common issues with typical 2D CNNs operating on RGB-D images. The results from this architecture are compared against various other state-of-the-art deep pose regression implementations using the 7 Scenes dataset. The findings are that FusionLoc performs better than a number of other camera localization methods, with a notable improvement being, on average, 0.33m and 4.35{\deg} more accurate than RGB-D PoseNet. By proving the validity of using pseudo-LiDAR signals over depth maps for localization, there are new considerations when implementing large-scale localization systems.