 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistance or Disruption? Exploring and Evaluating the Design and Trade-offs of Proactive AI Programming Support
Feb 25, 2025AI programming tools enable powerful code generation, and recent prototypes attempt to reduce user effort with proactive AI agents, but their impact on programming workflows remains unexplored. We introduce and evaluate Codellaborator, a design probe LLM agent that initiates programming assistance based on editor activities and task context. We explored three interface variants to assess trade-offs between increasingly salient AI support: prompt-only, proactive agent, and proactive agent with presence and context (Codellaborator). In a within-subject study (N=18), we find that proactive agents increase efficiency compared to prompt-only paradigm, but also incur workflow disruptions. However, presence indicators and \revise{interaction context support} alleviated disruptions and improved users' awareness of AI processes. We underscore trade-offs of Codellaborator on user control, ownership, and code understanding, emphasizing the need to adapt proactivity to programming processes. Our research contributes to the design exploration and evaluation of proactive AI systems, presenting design implications on AI-integrated programming workflow.
Exploring the Design Space of Cognitive Engagement Techniques with AI-Generated Code for Enhanced Learning
Oct 11, 2024
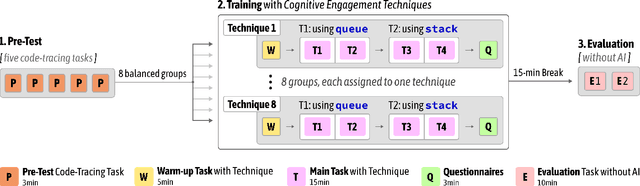
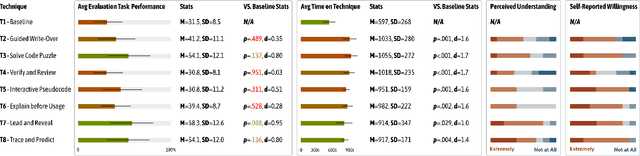
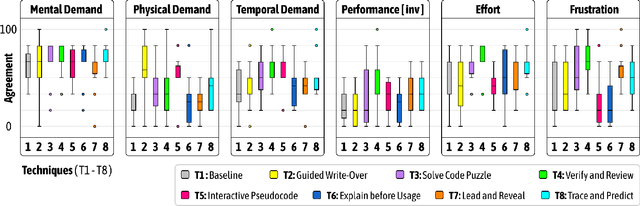
Novice programmers are increasingly relying on Large Language Models (LLMs) to generate code for learning programming concepts. However, this interaction can lead to superficial engagement, giving learners an illusion of learning and hindering skill development. To address this issue, we conducted a systematic design exploration to develop seven cognitive engagement techniques aimed at promoting deeper engagement with AI-generated code. In this paper, we describe our design process, the initial seven techniques and results from a between-subjects study (N=82). We then iteratively refined the top techniques and further evaluated them through a within-subjects study (N=42). We evaluate the friction each technique introduces, their effectiveness in helping learners apply concepts to isomorphic tasks without AI assistance, and their success in aligning learners' perceived and actual coding abilities. Ultimately, our results highlight the most effective technique: guiding learners through the step-by-step problem-solving process, where they engage in an interactive dialog with the AI, prompting what needs to be done at each stage before the corresponding code is revealed.
IdeaSynth: Iterative Research Idea Development Through Evolving and Composing Idea Facets with Literature-Grounded Feedback
Oct 05, 2024



Research ideation involves broad exploring and deep refining ideas. Both require deep engagement with literature. Existing tools focus primarily on idea broad generation, yet offer little support for iterative specification, refinement, and evaluation needed to further develop initial ideas. To bridge this gap, we introduce IdeaSynth, a research idea development system that uses LLMs to provide literature-grounded feedback for articulating research problems, solutions, evaluations, and contributions. IdeaSynth represents these idea facets as nodes on a canvas, and allow researchers to iteratively refine them by creating and exploring variations and composing them. Our lab study (N=20) showed that participants, while using IdeaSynth, explored more alternative ideas and expanded initial ideas with more details compared to a strong LLM-based baseline. Our deployment study (N=7) demonstrated that participants effectively used IdeaSynth for real-world research projects at various ideation stages from developing initial ideas to revising framings of mature manuscripts, highlighting the possibilities to adopt IdeaSynth in researcher's workflows.
Improving Steering and Verification in AI-Assisted Data Analysis with Interactive Task Decomposition
Jul 02, 2024



LLM-powered tools like ChatGPT Data Analysis, have the potential to help users tackle the challenging task of data analysis programming, which requires expertise in data processing, programming, and statistics. However, our formative study (n=15) uncovered serious challenges in verifying AI-generated results and steering the AI (i.e., guiding the AI system to produce the desired output). We developed two contrasting approaches to address these challenges. The first (Stepwise) decomposes the problem into step-by-step subgoals with pairs of editable assumptions and code until task completion, while the second (Phasewise) decomposes the entire problem into three editable, logical phases: structured input/output assumptions, execution plan, and code. A controlled, within-subjects experiment (n=18) compared these systems against a conversational baseline. Users reported significantly greater control with the Stepwise and Phasewise systems, and found intervention, correction, and verification easier, compared to the baseline. The results suggest design guidelines and trade-offs for AI-assisted data analysis tools.
OmniActions: Predicting Digital Actions in Response to Real-World Multimodal Sensory Inputs with LLMs
May 06, 2024



The progression to "Pervasive Augmented Reality" envisions easy access to multimodal information continuously. However, in many everyday scenarios, users are occupied physically, cognitively or socially. This may increase the friction to act upon the multimodal information that users encounter in the world. To reduce such friction, future interactive interfaces should intelligently provide quick access to digital actions based on users' context. To explore the range of possible digital actions, we conducted a diary study that required participants to capture and share the media that they intended to perform actions on (e.g., images or audio), along with their desired actions and other contextual information. Using this data, we generated a holistic design space of digital follow-up actions that could be performed in response to different types of multimodal sensory inputs. We then designed OmniActions, a pipeline powered by large language models (LLMs) that processes multimodal sensory inputs and predicts follow-up actions on the target information grounded in the derived design space. Using the empirical data collected in the diary study, we performed quantitative evaluations on three variations of LLM techniques (intent classification, in-context learning and finetuning) and identified the most effective technique for our task. Additionally, as an instantiation of the pipeline, we developed an interactive prototype and reported preliminary user feedback about how people perceive and react to the action predictions and its errors.
CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs
Jan 20, 2024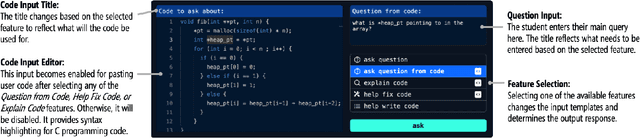



Timely, personalized feedback is essential for students learning programming, especially as class sizes expand. LLM-based tools like ChatGPT offer instant support, but reveal direct answers with code, which may hinder deep conceptual engagement. We developed CodeAid, an LLM-based programming assistant delivering helpful, technically correct responses, without revealing code solutions. For example, CodeAid can answer conceptual questions, generate pseudo-code with line-by-line explanations, and annotate student's incorrect code with fix suggestions. We deployed CodeAid in a programming class of 700 students for a 12-week semester. A thematic analysis of 8,000 usages of CodeAid was performed, further enriched by weekly surveys, and 22 student interviews. We then interviewed eight programming educators to gain further insights on CodeAid. Findings revealed students primarily used CodeAid for conceptual understanding and debugging, although a minority tried to obtain direct code. Educators appreciated CodeAid's educational approach, and expressed concerns about occasional incorrect feedback and students defaulting to ChatGPT.
SynthScribe: Deep Multimodal Tools for Synthesizer Sound Retrieval and Exploration
Dec 07, 2023Synthesizers are powerful tools that allow musicians to create dynamic and original sounds. Existing commercial interfaces for synthesizers typically require musicians to interact with complex low-level parameters or to manage large libraries of premade sounds. To address these challenges, we implement SynthScribe -- a fullstack system that uses multimodal deep learning to let users express their intentions at a much higher level. We implement features which address a number of difficulties, namely 1) searching through existing sounds, 2) creating completely new sounds, 3) making meaningful modifications to a given sound. This is achieved with three main features: a multimodal search engine for a large library of synthesizer sounds; a user centered genetic algorithm by which completely new sounds can be created and selected given the users preferences; a sound editing support feature which highlights and gives examples for key control parameters with respect to a text or audio based query. The results of our user studies show SynthScribe is capable of reliably retrieving and modifying sounds while also affording the ability to create completely new sounds that expand a musicians creative horizon.
ABScribe: Rapid Exploration of Multiple Writing Variations in Human-AI Co-Writing Tasks using Large Language Models
Oct 10, 2023Exploring alternative ideas by rewriting text is integral to the writing process. State-of-the-art large language models (LLMs) can simplify writing variation generation. However, current interfaces pose challenges for simultaneous consideration of multiple variations: creating new versions without overwriting text can be difficult, and pasting them sequentially can clutter documents, increasing workload and disrupting writers' flow. To tackle this, we present ABScribe, an interface that supports rapid, yet visually structured, exploration of writing variations in human-AI co-writing tasks. With ABScribe, users can swiftly produce multiple variations using LLM prompts, which are auto-converted into reusable buttons. Variations are stored adjacently within text segments for rapid in-place comparisons using mouse-over interactions on a context toolbar. Our user study with 12 writers shows that ABScribe significantly reduces task workload (d = 1.20, p < 0.001), enhances user perceptions of the revision process (d = 2.41, p < 0.001) compared to a popular baseline workflow, and provides insights into how writers explore variations using LLMs.
DiLogics: Creating Web Automation Programs With Diverse Logics
Aug 18, 2023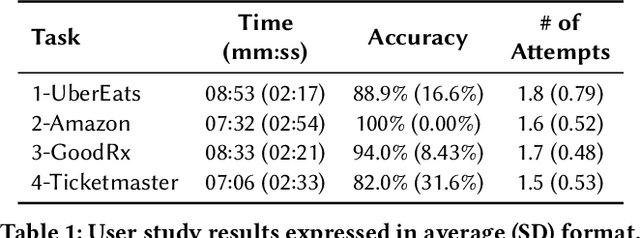
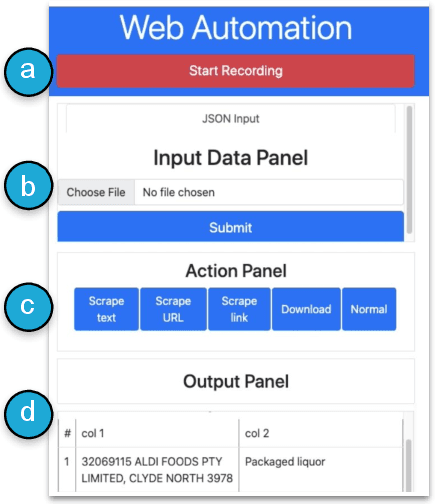
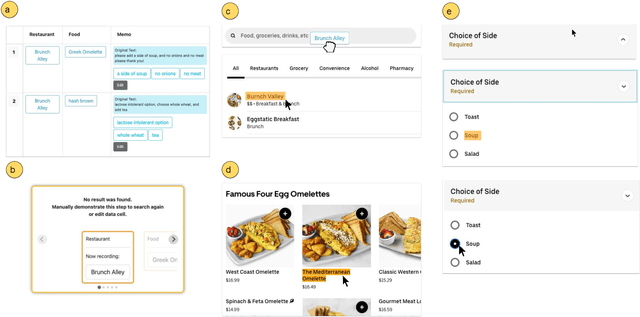
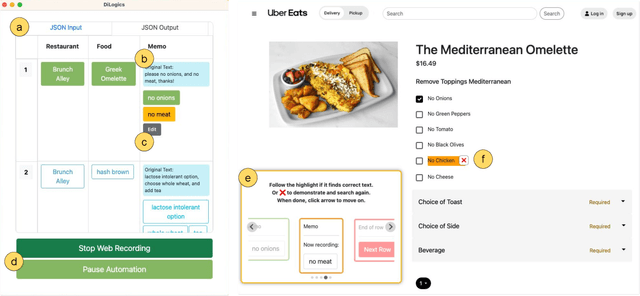
Knowledge workers frequently encounter repetitive web data entry tasks, like updating records or placing orders. Web automation increases productivity, but translating tasks to web actions accurately and extending to new specifications is challenging. Existing tools can automate tasks that perform the same logical trace of UI actions (e.g., input text in each field in order), but do not support tasks requiring different executions based on varied input conditions. We present DiLogics, a programming-by-demonstration system that utilizes NLP to assist users in creating web automation programs that handle diverse specifications. DiLogics first semantically segments input data to structured task steps. By recording user demonstrations for each step, DiLogics generalizes the web macros to novel but semantically similar task requirements. Our evaluation showed that non-experts can effectively use DiLogics to create automation programs that fulfill diverse input instructions. DiLogics provides an efficient, intuitive, and expressive method for developing web automation programs satisfying diverse specifications.
Promptify: Text-to-Image Generation through Interactive Prompt Exploration with Large Language Models
Apr 18, 2023



Text-to-image generative models have demonstrated remarkable capabilities in generating high-quality images based on textual prompts. However, crafting prompts that accurately capture the user's creative intent remains challenging. It often involves laborious trial-and-error procedures to ensure that the model interprets the prompts in alignment with the user's intention. To address the challenges, we present Promptify, an interactive system that supports prompt exploration and refinement for text-to-image generative models. Promptify utilizes a suggestion engine powered by large language models to help users quickly explore and craft diverse prompts. Our interface allows users to organize the generated images flexibly, and based on their preferences, Promptify suggests potential changes to the original prompt. This feedback loop enables users to iteratively refine their prompts and enhance desired features while avoiding unwanted ones. Our user study shows that Promptify effectively facilitates the text-to-image workflow and outperforms an existing baseline tool widely used for text-to-image generation.