 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitSearch: Enhancing Community Notes Generation with Gap-Informed Targeted Search
Feb 09, 2026Community-based moderation offers a scalable alternative to centralized fact-checking, yet it faces significant structural challenges, and existing AI-based methods fail in "cold start" scenarios. To tackle these challenges, we introduce GitSearch (Gap-Informed Targeted Search), a framework that treats human-perceived quality gaps, such as missing context, etc., as first-class signals. GitSearch has a three-stage pipeline: identifying information deficits, executing real-time targeted web-retrieval to resolve them, and synthesizing platform-compliant notes. To facilitate evaluation, we present PolBench, a benchmark of 78,698 U.S. political tweets with their associated Community Notes. We find GitSearch achieves 99% coverage, almost doubling coverage over the state-of-the-art. GitSearch surpasses human-authored helpful notes with a 69% win rate and superior helpfulness scores (3.87 vs. 3.36), demonstrating retrieval effectiveness that balanced the trade-off between scale and quality.
Hate Personified: Investigating the role of LLMs in content moderation
Oct 03, 2024

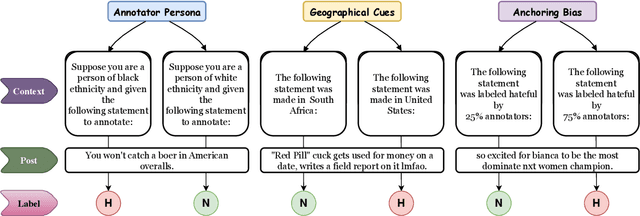
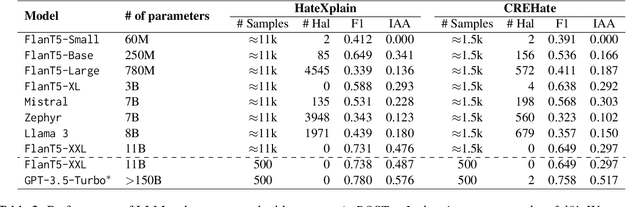
For subjective tasks such as hate detection, where people perceive hate differently, the Large Language Model's (LLM) ability to represent diverse groups is unclear. By including additional context in prompts, we comprehensively analyze LLM's sensitivity to geographical priming, persona attributes, and numerical information to assess how well the needs of various groups are reflected. Our findings on two LLMs, five languages, and six datasets reveal that mimicking persona-based attributes leads to annotation variability. Meanwhile, incorporating geographical signals leads to better regional alignment. We also find that the LLMs are sensitive to numerical anchors, indicating the ability to leverage community-based flagging efforts and exposure to adversaries. Our work provides preliminary guidelines and highlights the nuances of applying LLMs in culturally sensitive cases.
Intent-conditioned and Non-toxic Counterspeech Generation using Multi-Task Instruction Tuning with RLAIF
Mar 15, 2024Counterspeech, defined as a response to mitigate online hate speech, is increasingly used as a non-censorial solution. Addressing hate speech effectively involves dispelling the stereotypes, prejudices, and biases often subtly implied in brief, single-sentence statements or abuses. These implicit expressions challenge language models, especially in seq2seq tasks, as model performance typically excels with longer contexts. Our study introduces CoARL, a novel framework enhancing counterspeech generation by modeling the pragmatic implications underlying social biases in hateful statements. CoARL's first two phases involve sequential multi-instruction tuning, teaching the model to understand intents, reactions, and harms of offensive statements, and then learning task-specific low-rank adapter weights for generating intent-conditioned counterspeech. The final phase uses reinforcement learning to fine-tune outputs for effectiveness and non-toxicity. CoARL outperforms existing benchmarks in intent-conditioned counterspeech generation, showing an average improvement of 3 points in intent-conformity and 4 points in argument-quality metrics. Extensive human evaluation supports CoARL's efficacy in generating superior and more context-appropriate responses compared to existing systems, including prominent LLMs like ChatGPT.