 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Theory of Mind and Prosocial Beliefs on Steering Human-Aligned Behaviors of LLMs in Ultimatum Games
May 30, 2025Large Language Models (LLMs) have shown potential in simulating human behaviors and performing theory-of-mind (ToM) reasoning, a crucial skill for complex social interactions. In this study, we investigate the role of ToM reasoning in aligning agentic behaviors with human norms in negotiation tasks, using the ultimatum game as a controlled environment. We initialized LLM agents with different prosocial beliefs (including Greedy, Fair, and Selfless) and reasoning methods like chain-of-thought (CoT) and varying ToM levels, and examined their decision-making processes across diverse LLMs, including reasoning models like o3-mini and DeepSeek-R1 Distilled Qwen 32B. Results from 2,700 simulations indicated that ToM reasoning enhances behavior alignment, decision-making consistency, and negotiation outcomes. Consistent with previous findings, reasoning models exhibit limited capability compared to models with ToM reasoning, different roles of the game benefits with different orders of ToM reasoning. Our findings contribute to the understanding of ToM's role in enhancing human-AI interaction and cooperative decision-making. The code used for our experiments can be found at https://github.com/Stealth-py/UltimatumToM.
Revealing Hidden Mechanisms of Cross-Country Content Moderation with Natural Language Processing
Mar 07, 2025
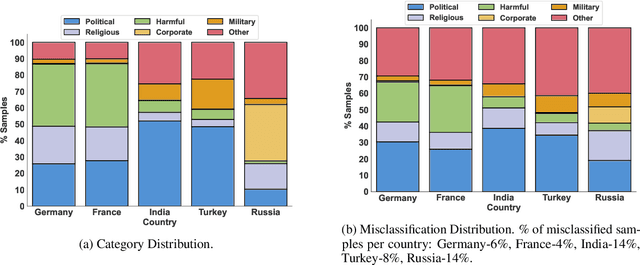
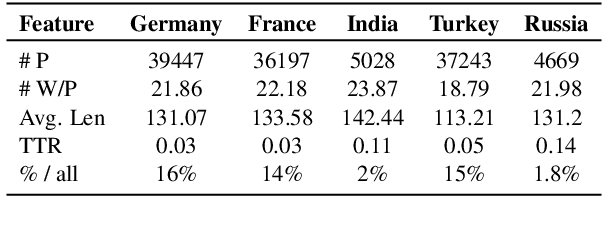
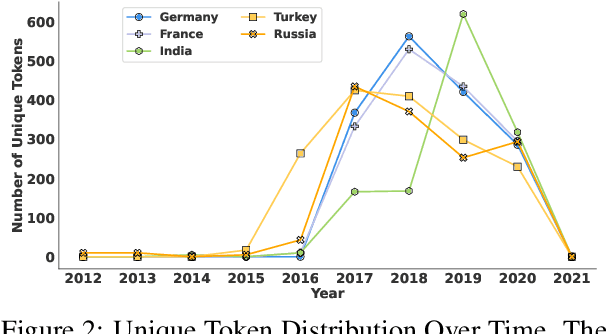
The ability of Natural Language Processing (NLP) methods to categorize text into multiple classes has motivated their use in online content moderation tasks, such as hate speech and fake news detection. However, there is limited understanding of how or why these methods make such decisions, or why certain content is moderated in the first place. To investigate the hidden mechanisms behind content moderation, we explore multiple directions: 1) training classifiers to reverse-engineer content moderation decisions across countries; 2) explaining content moderation decisions by analyzing Shapley values and LLM-guided explanations. Our primary focus is on content moderation decisions made across countries, using pre-existing corpora sampled from the Twitter Stream Grab. Our experiments reveal interesting patterns in censored posts, both across countries and over time. Through human evaluations of LLM-generated explanations across three LLMs, we assess the effectiveness of using LLMs in content moderation. Finally, we discuss potential future directions, as well as the limitations and ethical considerations of this work. Our code and data are available at https://github.com/causalNLP/censorship
QUENCH: Measuring the gap between Indic and Non-Indic Contextual General Reasoning in LLMs
Dec 16, 2024



The rise of large language models (LLMs) has created a need for advanced benchmarking systems beyond traditional setups. To this end, we introduce QUENCH, a novel text-based English Quizzing Benchmark manually curated and transcribed from YouTube quiz videos. QUENCH possesses masked entities and rationales for the LLMs to predict via generation. At the intersection of geographical context and common sense reasoning, QUENCH helps assess world knowledge and deduction capabilities of LLMs via a zero-shot, open-domain quizzing setup. We perform an extensive evaluation on 7 LLMs and 4 metrics, investigating the influence of model size, prompting style, geographical context, and gold-labeled rationale generation. The benchmarking concludes with an error analysis to which the LLMs are prone.
Tox-BART: Leveraging Toxicity Attributes for Explanation Generation of Implicit Hate Speech
Jun 06, 2024



Employing language models to generate explanations for an incoming implicit hate post is an active area of research. The explanation is intended to make explicit the underlying stereotype and aid content moderators. The training often combines top-k relevant knowledge graph (KG) tuples to provide world knowledge and improve performance on standard metrics. Interestingly, our study presents conflicting evidence for the role of the quality of KG tuples in generating implicit explanations. Consequently, simpler models incorporating external toxicity signals outperform KG-infused models. Compared to the KG-based setup, we observe a comparable performance for SBIC (LatentHatred) datasets with a performance variation of +0.44 (+0.49), +1.83 (-1.56), and -4.59 (+0.77) in BLEU, ROUGE-L, and BERTScore. Further human evaluation and error analysis reveal that our proposed setup produces more precise explanations than zero-shot GPT-3.5, highlighting the intricate nature of the task.
The Art of Embedding Fusion: Optimizing Hate Speech Detection
Jun 26, 2023Hate speech detection is a challenging natural language processing task that requires capturing linguistic and contextual nuances. Pre-trained language models (PLMs) offer rich semantic representations of text that can improve this task. However there is still limited knowledge about ways to effectively combine representations across PLMs and leverage their complementary strengths. In this work, we shed light on various combination techniques for several PLMs and comprehensively analyze their effectiveness. Our findings show that combining embeddings leads to slight improvements but at a high computational cost and the choice of combination has marginal effect on the final outcome. We also make our codebase public at https://github.com/aflah02/The-Art-of-Embedding-Fusion-Optimizing-Hate-Speech-Detection .