 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Hidden Mechanisms of Cross-Country Content Moderation with Natural Language Processing
Mar 07, 2025
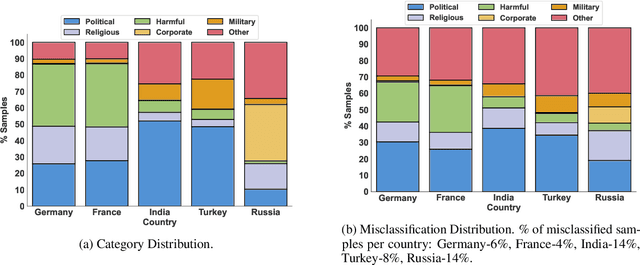
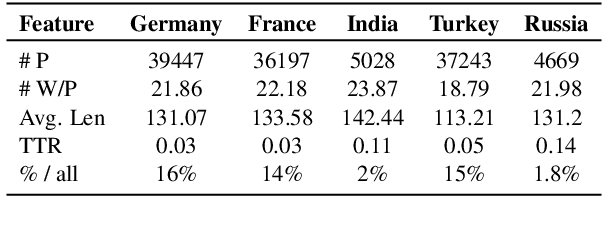
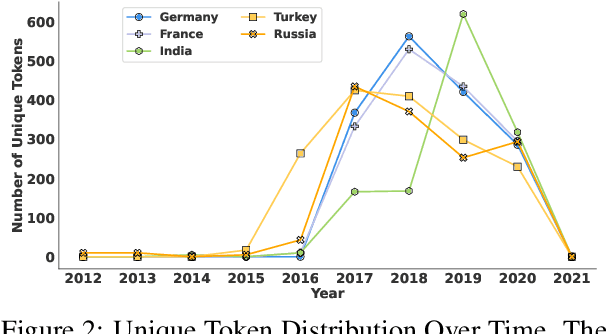
The ability of Natural Language Processing (NLP) methods to categorize text into multiple classes has motivated their use in online content moderation tasks, such as hate speech and fake news detection. However, there is limited understanding of how or why these methods make such decisions, or why certain content is moderated in the first place. To investigate the hidden mechanisms behind content moderation, we explore multiple directions: 1) training classifiers to reverse-engineer content moderation decisions across countries; 2) explaining content moderation decisions by analyzing Shapley values and LLM-guided explanations. Our primary focus is on content moderation decisions made across countries, using pre-existing corpora sampled from the Twitter Stream Grab. Our experiments reveal interesting patterns in censored posts, both across countries and over time. Through human evaluations of LLM-generated explanations across three LLMs, we assess the effectiveness of using LLMs in content moderation. Finally, we discuss potential future directions, as well as the limitations and ethical considerations of this work. Our code and data are available at https://github.com/causalNLP/censorship
The Narrow Gate: Localized Image-Text Communication in Vision-Language Models
Dec 09, 2024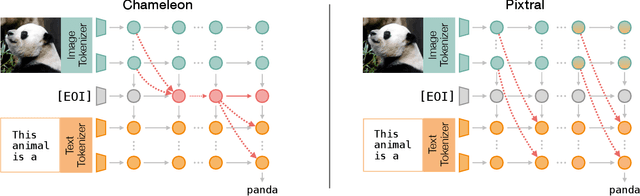
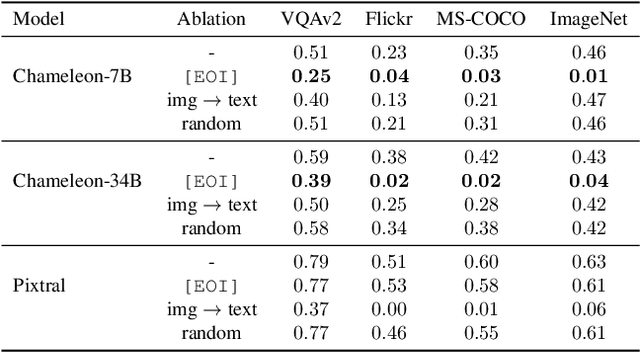
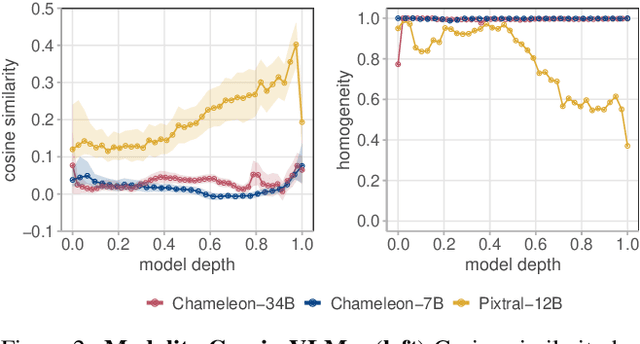
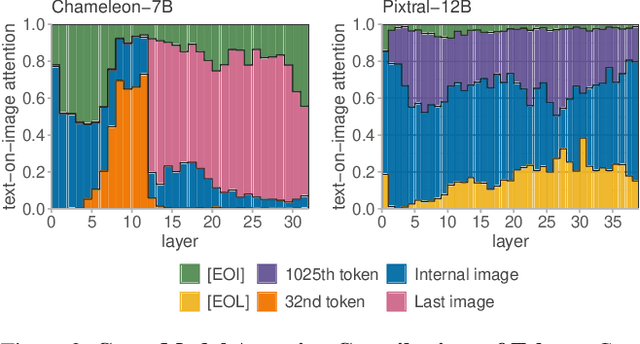
Recent advances in multimodal training have significantly improved the integration of image understanding and generation within a unified model. This study investigates how vision-language models (VLMs) handle image-understanding tasks, specifically focusing on how visual information is processed and transferred to the textual domain. We compare VLMs that generate both images and text with those that output only text, highlighting key differences in information flow. We find that in models with multimodal outputs, image and text embeddings are more separated within the residual stream. Additionally, models vary in how information is exchanged from visual to textual tokens. VLMs that only output text exhibit a distributed communication pattern, where information is exchanged through multiple image tokens. In contrast, models trained for image and text generation rely on a single token that acts as a narrow gate for the visual information. We demonstrate that ablating this single token significantly deteriorates performance on image understanding tasks. Furthermore, modifying this token enables effective steering of the image semantics, showing that targeted, local interventions can reliably control the model's global behavior.
Multilingual Trolley Problems for Language Models
Jul 02, 2024

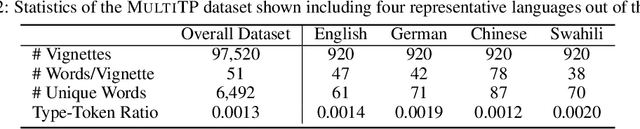
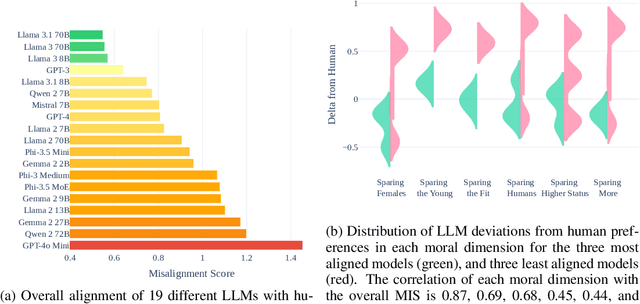
As large language models (LLMs) are deployed in more and more real-world situations, it is crucial to understand their decision-making when faced with moral dilemmas. Inspired by a large-scale cross-cultural study of human moral preferences, "The Moral Machine Experiment", we set up the same set of moral choices for LLMs. We translate 1K vignettes of moral dilemmas, parametrically varied across key axes, into 100+ languages, and reveal the preferences of LLMs in each of these languages. We then compare the responses of LLMs to that of human speakers of those languages, harnessing a dataset of 40 million human moral judgments. We discover that LLMs are more aligned with human preferences in languages such as English, Korean, Hungarian, and Chinese, but less aligned in languages such as Hindi and Somali (in Africa). Moreover, we characterize the explanations LLMs give for their moral choices and find that fairness is the most dominant supporting reason behind GPT-4's decisions and utilitarianism by GPT-3. We also discover "language inequality" (which we define as the model's different development levels in different languages) in a series of meta-properties of moral decision making.
Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals
Feb 18, 2024



Interpretability research aims to bridge the gap between the empirical success and our scientific understanding of the inner workings of large language models (LLMs). However, most existing research in this area focused on analyzing a single mechanism, such as how models copy or recall factual knowledge. In this work, we propose the formulation of competition of mechanisms, which instead of individual mechanisms focuses on the interplay of multiple mechanisms, and traces how one of them becomes dominant in the final prediction. We uncover how and where the competition of mechanisms happens within LLMs using two interpretability methods, logit inspection and attention modification. Our findings show traces of the mechanisms and their competition across various model components, and reveal attention positions that effectively control the strength of certain mechanisms. Our code and data are at https://github.com/francescortu/Competition_of_Mechanisms.