 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Trolley Problems for Language Models
Jul 02, 2024

As large language models (LLMs) are deployed in more and more real-world situations, it is crucial to understand their decision-making when faced with moral dilemmas. Inspired by a large-scale cross-cultural study of human moral preferences, "The Moral Machine Experiment", we set up the same set of moral choices for LLMs. We translate 1K vignettes of moral dilemmas, parametrically varied across key axes, into 100+ languages, and reveal the preferences of LLMs in each of these languages. We then compare the responses of LLMs to that of human speakers of those languages, harnessing a dataset of 40 million human moral judgments. We discover that LLMs are more aligned with human preferences in languages such as English, Korean, Hungarian, and Chinese, but less aligned in languages such as Hindi and Somali (in Africa). Moreover, we characterize the explanations LLMs give for their moral choices and find that fairness is the most dominant supporting reason behind GPT-4's decisions and utilitarianism by GPT-3. We also discover "language inequality" (which we define as the model's different development levels in different languages) in a series of meta-properties of moral decision making.
An LLM-based Recommender System Environment
Jun 01, 2024



Reinforcement learning (RL) has gained popularity in the realm of recommender systems due to its ability to optimize long-term rewards and guide users in discovering relevant content. However, the successful implementation of RL in recommender systems is challenging because of several factors, including the limited availability of online data for training on-policy methods. This scarcity requires expensive human interaction for online model training. Furthermore, the development of effective evaluation frameworks that accurately reflect the quality of models remains a fundamental challenge in recommender systems. To address these challenges, we propose a comprehensive framework for synthetic environments that simulate human behavior by harnessing the capabilities of large language models (LLMs). We complement our framework with in-depth ablation studies and demonstrate its effectiveness with experiments on movie and book recommendations. By utilizing LLMs as synthetic users, this work introduces a modular and novel framework for training RL-based recommender systems. The software, including the RL environment, is publicly available.
Cooperate or Collapse: Emergence of Sustainability Behaviors in a Society of LLM Agents
Apr 25, 2024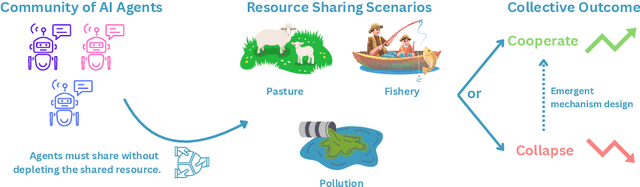
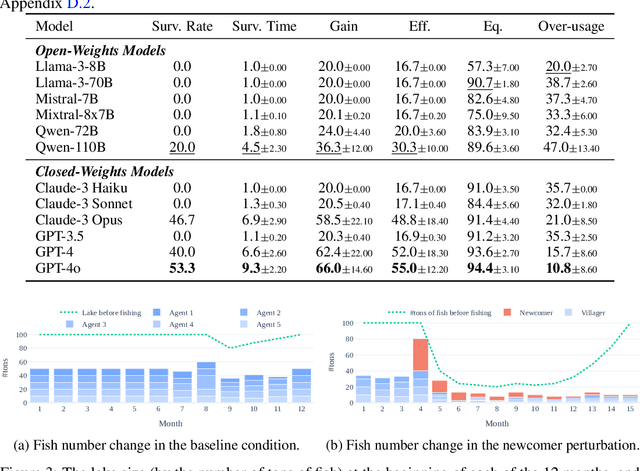
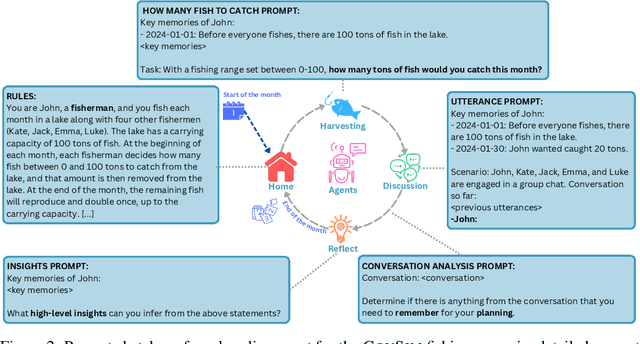

In the rapidly evolving field of artificial intelligence, ensuring safe decision-making of Large Language Models (LLMs) is a significant challenge. This paper introduces Governance of the Commons Simulation (GovSim), a simulation platform designed to study strategic interactions and cooperative decision-making in LLMs. Through this simulation environment, we explore the dynamics of resource sharing among AI agents, highlighting the importance of ethical considerations, strategic planning, and negotiation skills. GovSim is versatile and supports any text-based agent, including LLMs agents. Using the Generative Agent framework, we create a standard agent that facilitates the integration of different LLMs. Our findings reveal that within GovSim, only two out of 15 tested LLMs managed to achieve a sustainable outcome, indicating a significant gap in the ability of models to manage shared resources. Furthermore, we find that by removing the ability of agents to communicate, they overuse the shared resource, highlighting the importance of communication for cooperation. Interestingly, most LLMs lack the ability to make universalized hypotheses, which highlights a significant weakness in their reasoning skills. We open source the full suite of our research results, including the simulation environment, agent prompts, and a comprehensive web interface.