 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Trolley Problems for Language Models
Paper and Code


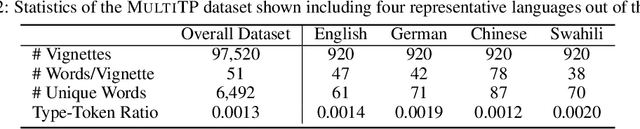
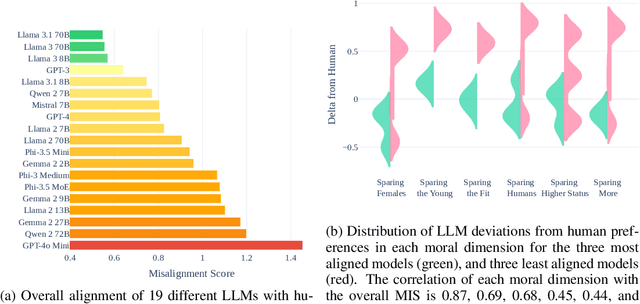
As large language models (LLMs) are deployed in more and more real-world situations, it is crucial to understand their decision-making when faced with moral dilemmas. Inspired by a large-scale cross-cultural study of human moral preferences, "The Moral Machine Experiment", we set up the same set of moral choices for LLMs. We translate 1K vignettes of moral dilemmas, parametrically varied across key axes, into 100+ languages, and reveal the preferences of LLMs in each of these languages. We then compare the responses of LLMs to that of human speakers of those languages, harnessing a dataset of 40 million human moral judgments. We discover that LLMs are more aligned with human preferences in languages such as English, Korean, Hungarian, and Chinese, but less aligned in languages such as Hindi and Somali (in Africa). Moreover, we characterize the explanations LLMs give for their moral choices and find that fairness is the most dominant supporting reason behind GPT-4's decisions and utilitarianism by GPT-3. We also discover "language inequality" (which we define as the model's different development levels in different languages) in a series of meta-properties of moral decision making.