 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Instruction Tuning Aligns Modalities through Abstraction
Jun 02, 2026Visual instruction tuning effectively adapts a pre-trained Large Language Model (LLM) to process image information alongside text. Yet, it remains unclear how visual features are embedded into the layer-wise hierarchy of abstractions of the LLM backbone. Across a diverse set of vision-language architectures, we show that instruction tuning primarily serves as a bridge, embedding visual features directly into the intermediate semantic layers of the LLM, bypassing the early layers devoted to unimodal processing. With probing analyses and causal interventions, we show that these intermediate layers are the semantic core of vision-language processing and play a critical role in the performance on a broad set of multimodal benchmarks. In addition, by comparing the geometry of semantically equivalent visual and textual representations, we find that fine-tuning extends and strengthens the existing abstraction phase, aligning visual features with pre-existing textual ones. Finally, we confirm the functional role of this localized alignment by restricting fine-tuning to intermediate layers alone: this strategy preserves the performance of full fine-tuning on vision-centric benchmarks while reducing training time. Our results suggest that multimodal integration is a localized phenomenon driven by the repurposing of the internal abstraction engine of the LLM.
Generative Image Restoration and Super-Resolution using Physics-Informed Synthetic Data for Scanning Tunneling Microscopy
Oct 29, 2025Scanning tunnelling microscopy (STM) enables atomic-resolution imaging and atom manipulation, but its utility is often limited by tip degradation and slow serial data acquisition. Fabrication adds another layer of complexity since the tip is often subjected to large voltages, which may alter the shape of its apex, requiring it to be conditioned. Here, we propose a machine learning (ML) approach for image repair and super-resolution to alleviate both challenges. Using a dataset of only 36 pristine experimental images of Si(001):H, we demonstrate that a physics-informed synthetic data generation pipeline can be used to train several state-of-the-art flow-matching and diffusion models. Quantitative evaluation with metrics such as the CLIP Maximum Mean Discrepancy (CMMD) score and structural similarity demonstrates that our models are able to effectively restore images and offer a two- to fourfold reduction in image acquisition time by accurately reconstructing images from sparsely sampled data. Our framework has the potential to significantly increase STM experimental throughput by offering a route to reducing the frequency of tip-conditioning procedures and to enhancing frame rates in existing high-speed STM systems.
Head Pursuit: Probing Attention Specialization in Multimodal Transformers
Oct 24, 2025Language and vision-language models have shown impressive performance across a wide range of tasks, but their internal mechanisms remain only partly understood. In this work, we study how individual attention heads in text-generative models specialize in specific semantic or visual attributes. Building on an established interpretability method, we reinterpret the practice of probing intermediate activations with the final decoding layer through the lens of signal processing. This lets us analyze multiple samples in a principled way and rank attention heads based on their relevance to target concepts. Our results show consistent patterns of specialization at the head level across both unimodal and multimodal transformers. Remarkably, we find that editing as few as 1% of the heads, selected using our method, can reliably suppress or enhance targeted concepts in the model output. We validate our approach on language tasks such as question answering and toxicity mitigation, as well as vision-language tasks including image classification and captioning. Our findings highlight an interpretable and controllable structure within attention layers, offering simple tools for understanding and editing large-scale generative models.
The Geometry of Tokens in Internal Representations of Large Language Models
Jan 17, 2025

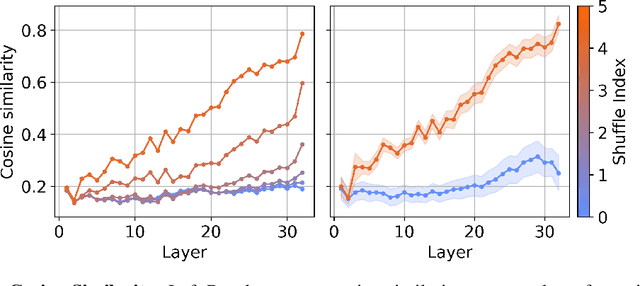
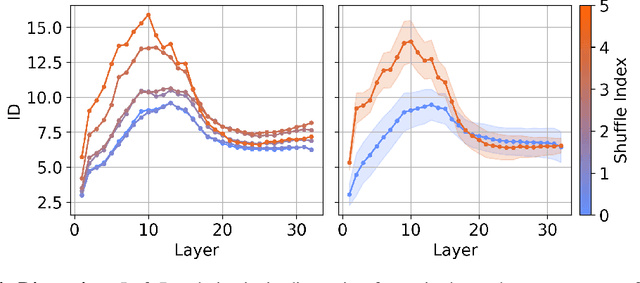
We investigate the relationship between the geometry of token embeddings and their role in the next token prediction within transformer models. An important aspect of this connection uses the notion of empirical measure, which encodes the distribution of token point clouds across transformer layers and drives the evolution of token representations in the mean-field interacting picture. We use metrics such as intrinsic dimension, neighborhood overlap, and cosine similarity to observationally probe these empirical measures across layers. To validate our approach, we compare these metrics to a dataset where the tokens are shuffled, which disrupts the syntactic and semantic structure. Our findings reveal a correlation between the geometric properties of token embeddings and the cross-entropy loss of next token predictions, implying that prompts with higher loss values have tokens represented in higher-dimensional spaces.
The Narrow Gate: Localized Image-Text Communication in Vision-Language Models
Dec 09, 2024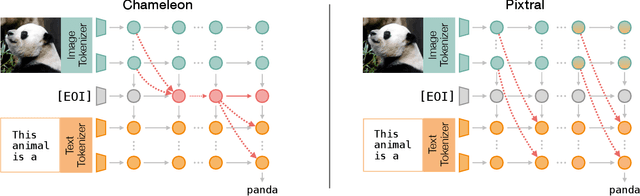
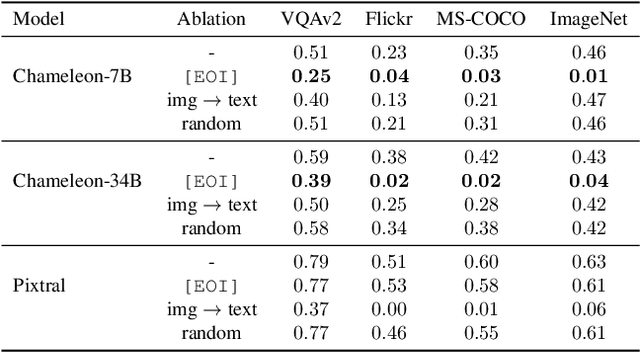
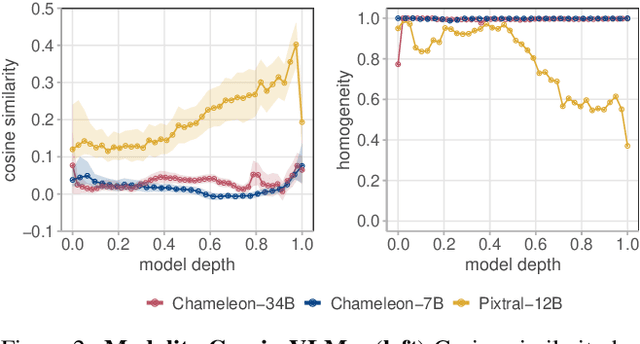
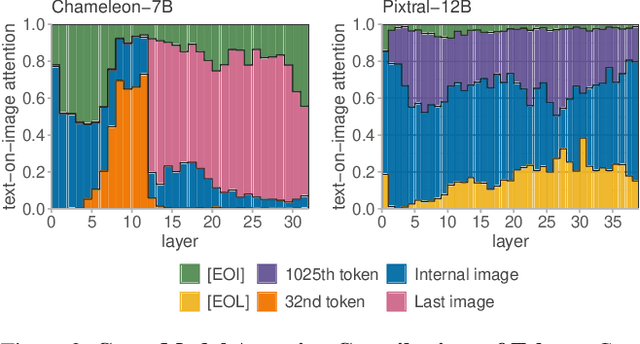
Recent advances in multimodal training have significantly improved the integration of image understanding and generation within a unified model. This study investigates how vision-language models (VLMs) handle image-understanding tasks, specifically focusing on how visual information is processed and transferred to the textual domain. We compare VLMs that generate both images and text with those that output only text, highlighting key differences in information flow. We find that in models with multimodal outputs, image and text embeddings are more separated within the residual stream. Additionally, models vary in how information is exchanged from visual to textual tokens. VLMs that only output text exhibit a distributed communication pattern, where information is exchanged through multiple image tokens. In contrast, models trained for image and text generation rely on a single token that acts as a narrow gate for the visual information. We demonstrate that ablating this single token significantly deteriorates performance on image understanding tasks. Furthermore, modifying this token enables effective steering of the image semantics, showing that targeted, local interventions can reliably control the model's global behavior.
Persistent Topological Features in Large Language Models
Oct 14, 2024Understanding the decision-making processes of large language models (LLMs) is critical given their widespread applications. Towards this goal, describing the topological and geometrical properties of internal representations has recently provided valuable insights. For a more comprehensive characterization of these inherently complex spaces, we present a novel framework based on zigzag persistence, a method in topological data analysis (TDA) well-suited for describing data undergoing dynamic transformations across layers. Within this framework, we introduce persistence similarity, a new metric that quantifies the persistence and transformation of topological features such as $p$-cycles throughout the model layers. Unlike traditional similarity measures, our approach captures the entire evolutionary trajectory of these features, providing deeper insights into the internal workings of LLMs. As a practical application, we leverage persistence similarity to identify and prune redundant layers, demonstrating comparable performance to state-of-the-art methods across several benchmark datasets. Additionally, our analysis reveals consistent topological behaviors across various models and hyperparameter settings, suggesting a universal structure in LLM internal representations.
The representation landscape of few-shot learning and fine-tuning in large language models
Sep 05, 2024



In-context learning (ICL) and supervised fine-tuning (SFT) are two common strategies for improving the performance of modern large language models (LLMs) on specific tasks. Despite their different natures, these strategies often lead to comparable performance gains. However, little is known about whether they induce similar representations inside LLMs. We approach this problem by analyzing the probability landscape of their hidden representations in the two cases. More specifically, we compare how LLMs solve the same question-answering task, finding that ICL and SFT create very different internal structures, in both cases undergoing a sharp transition in the middle of the network. In the first half of the network, ICL shapes interpretable representations hierarchically organized according to their semantic content. In contrast, the probability landscape obtained with SFT is fuzzier and semantically mixed. In the second half of the model, the fine-tuned representations develop probability modes that better encode the identity of answers, while the landscape of ICL representations is characterized by less defined peaks. Our approach reveals the diverse computational strategies developed inside LLMs to solve the same task across different conditions, allowing us to make a step towards designing optimal methods to extract information from language models.
Competition of Mechanisms: Tracing How Language Models Handle Facts and Counterfactuals
Feb 18, 2024



Interpretability research aims to bridge the gap between the empirical success and our scientific understanding of the inner workings of large language models (LLMs). However, most existing research in this area focused on analyzing a single mechanism, such as how models copy or recall factual knowledge. In this work, we propose the formulation of competition of mechanisms, which instead of individual mechanisms focuses on the interplay of multiple mechanisms, and traces how one of them becomes dominant in the final prediction. We uncover how and where the competition of mechanisms happens within LLMs using two interpretability methods, logit inspection and attention modification. Our findings show traces of the mechanisms and their competition across various model components, and reveal attention positions that effectively control the strength of certain mechanisms. Our code and data are at https://github.com/francescortu/Competition_of_Mechanisms.
Emergent representations in networks trained with the Forward-Forward algorithm
May 26, 2023



The Backpropagation algorithm, widely used to train neural networks, has often been criticised for its lack of biological realism. In an attempt to find a more biologically plausible alternative, and avoid to back-propagate gradients in favour of using local learning rules, the recently introduced Forward-Forward algorithm replaces the traditional forward and backward passes of Backpropagation with two forward passes. In this work, we show that internal representations obtained with the Forward-Forward algorithm organize into robust, category-specific ensembles, composed by an extremely low number of active units (high sparsity). This is remarkably similar to what is observed in cortical representations during sensory processing. While not found in models trained with standard Backpropagation, sparsity emerges also in networks optimized by Backpropagation, on the same training objective of Forward-Forward. These results suggest that the learning procedure proposed by Forward-Forward may be superior to Backpropagation in modelling learning in the cortex, even when a backward pass is used.
The geometry of hidden representations of large transformer models
Feb 01, 2023



Large transformers are powerful architectures for self-supervised analysis of data of various nature, ranging from protein sequences to text to images. In these models, the data representation in the hidden layers live in the same space, and the semantic structure of the dataset emerges by a sequence of functionally identical transformations between one representation and the next. We here characterize the geometric and statistical properties of these representations, focusing on the evolution of such proprieties across the layers. By analyzing geometric properties such as the intrinsic dimension (ID) and the neighbor composition we find that the representations evolve in a strikingly similar manner in transformers trained on protein language tasks and image reconstruction tasks. In the first layers, the data manifold expands, becoming high-dimensional, and then it contracts significantly in the intermediate layers. In the last part of the model, the ID remains approximately constant or forms a second shallow peak. We show that the semantic complexity of the dataset emerges at the end of the first peak. This phenomenon can be observed across many models trained on diverse datasets. Based on these observations, we suggest using the ID profile as an unsupervised proxy to identify the layers which are more suitable for downstream learning tasks.