 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Tokens in Internal Representations of Large Language Models
Jan 17, 2025

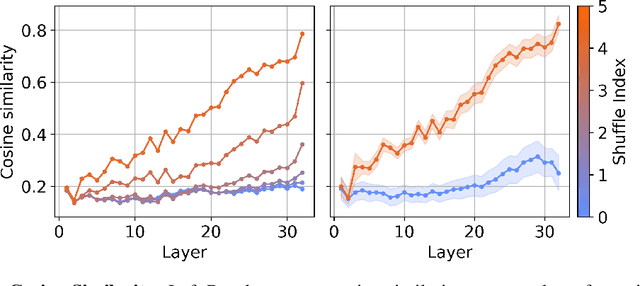
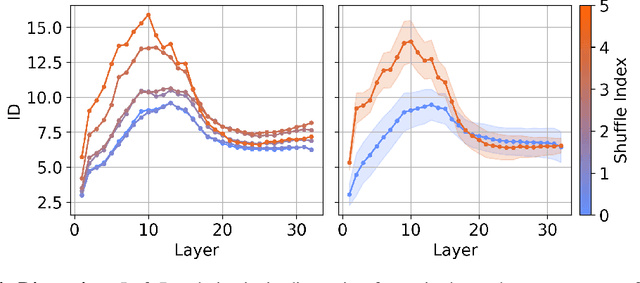
We investigate the relationship between the geometry of token embeddings and their role in the next token prediction within transformer models. An important aspect of this connection uses the notion of empirical measure, which encodes the distribution of token point clouds across transformer layers and drives the evolution of token representations in the mean-field interacting picture. We use metrics such as intrinsic dimension, neighborhood overlap, and cosine similarity to observationally probe these empirical measures across layers. To validate our approach, we compare these metrics to a dataset where the tokens are shuffled, which disrupts the syntactic and semantic structure. Our findings reveal a correlation between the geometric properties of token embeddings and the cross-entropy loss of next token predictions, implying that prompts with higher loss values have tokens represented in higher-dimensional spaces.
Persistent Topological Features in Large Language Models
Oct 14, 2024Understanding the decision-making processes of large language models (LLMs) is critical given their widespread applications. Towards this goal, describing the topological and geometrical properties of internal representations has recently provided valuable insights. For a more comprehensive characterization of these inherently complex spaces, we present a novel framework based on zigzag persistence, a method in topological data analysis (TDA) well-suited for describing data undergoing dynamic transformations across layers. Within this framework, we introduce persistence similarity, a new metric that quantifies the persistence and transformation of topological features such as $p$-cycles throughout the model layers. Unlike traditional similarity measures, our approach captures the entire evolutionary trajectory of these features, providing deeper insights into the internal workings of LLMs. As a practical application, we leverage persistence similarity to identify and prune redundant layers, demonstrating comparable performance to state-of-the-art methods across several benchmark datasets. Additionally, our analysis reveals consistent topological behaviors across various models and hyperparameter settings, suggesting a universal structure in LLM internal representations.