 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Narrow Gate: Localized Image-Text Communication in Vision-Language Models
Dec 09, 2024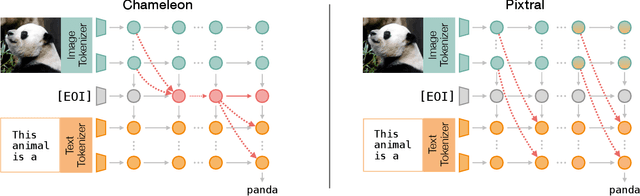
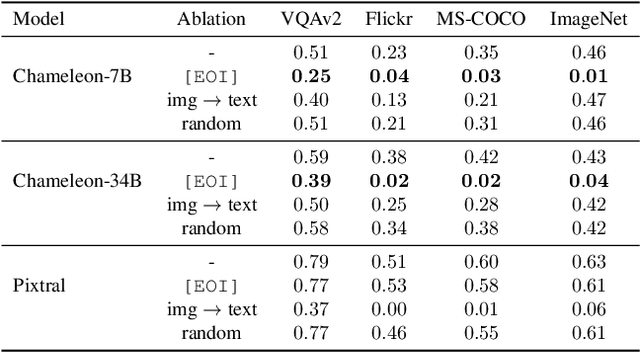
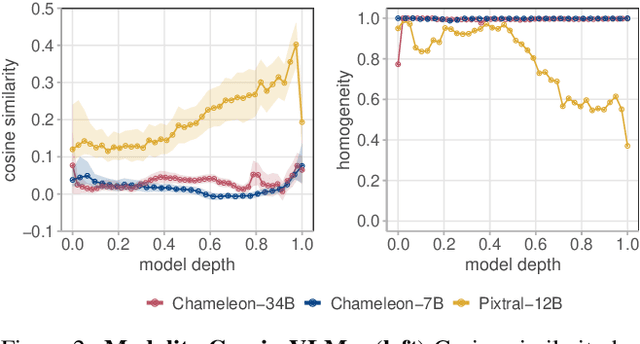
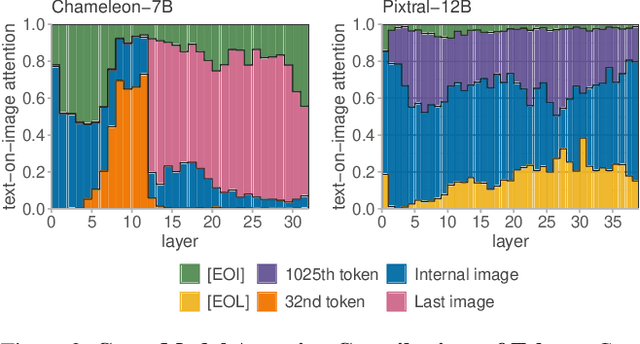
Recent advances in multimodal training have significantly improved the integration of image understanding and generation within a unified model. This study investigates how vision-language models (VLMs) handle image-understanding tasks, specifically focusing on how visual information is processed and transferred to the textual domain. We compare VLMs that generate both images and text with those that output only text, highlighting key differences in information flow. We find that in models with multimodal outputs, image and text embeddings are more separated within the residual stream. Additionally, models vary in how information is exchanged from visual to textual tokens. VLMs that only output text exhibit a distributed communication pattern, where information is exchanged through multiple image tokens. In contrast, models trained for image and text generation rely on a single token that acts as a narrow gate for the visual information. We demonstrate that ablating this single token significantly deteriorates performance on image understanding tasks. Furthermore, modifying this token enables effective steering of the image semantics, showing that targeted, local interventions can reliably control the model's global behavior.
The geometry of hidden representations of large transformer models
Feb 01, 2023



Large transformers are powerful architectures for self-supervised analysis of data of various nature, ranging from protein sequences to text to images. In these models, the data representation in the hidden layers live in the same space, and the semantic structure of the dataset emerges by a sequence of functionally identical transformations between one representation and the next. We here characterize the geometric and statistical properties of these representations, focusing on the evolution of such proprieties across the layers. By analyzing geometric properties such as the intrinsic dimension (ID) and the neighbor composition we find that the representations evolve in a strikingly similar manner in transformers trained on protein language tasks and image reconstruction tasks. In the first layers, the data manifold expands, becoming high-dimensional, and then it contracts significantly in the intermediate layers. In the last part of the model, the ID remains approximately constant or forms a second shallow peak. We show that the semantic complexity of the dataset emerges at the end of the first peak. This phenomenon can be observed across many models trained on diverse datasets. Based on these observations, we suggest using the ID profile as an unsupervised proxy to identify the layers which are more suitable for downstream learning tasks.