 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Narrow Gate: Localized Image-Text Communication in Vision-Language Models
Dec 09, 2024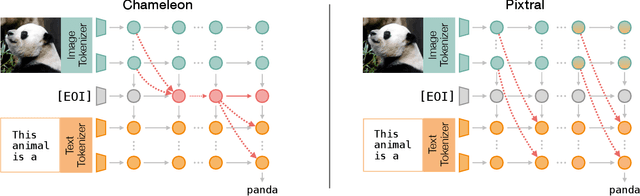
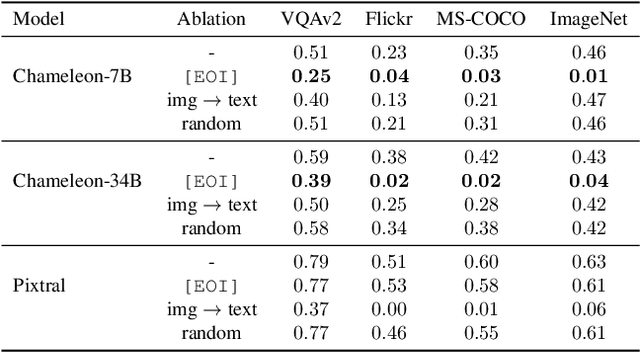
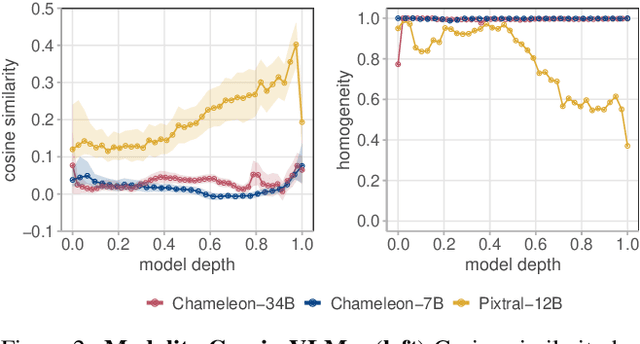
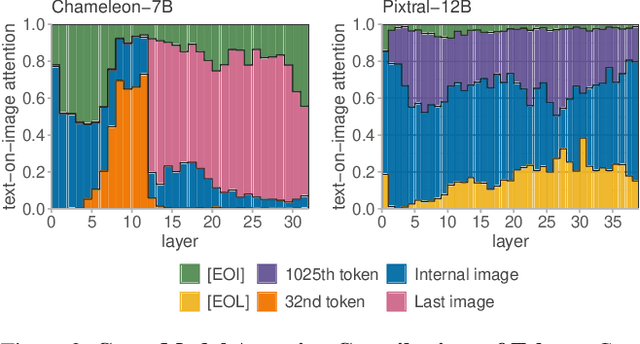
Recent advances in multimodal training have significantly improved the integration of image understanding and generation within a unified model. This study investigates how vision-language models (VLMs) handle image-understanding tasks, specifically focusing on how visual information is processed and transferred to the textual domain. We compare VLMs that generate both images and text with those that output only text, highlighting key differences in information flow. We find that in models with multimodal outputs, image and text embeddings are more separated within the residual stream. Additionally, models vary in how information is exchanged from visual to textual tokens. VLMs that only output text exhibit a distributed communication pattern, where information is exchanged through multiple image tokens. In contrast, models trained for image and text generation rely on a single token that acts as a narrow gate for the visual information. We demonstrate that ablating this single token significantly deteriorates performance on image understanding tasks. Furthermore, modifying this token enables effective steering of the image semantics, showing that targeted, local interventions can reliably control the model's global behavior.
Counterfactual rewards promote collective transport using individually controlled swarm microrobots
Jul 29, 2024Swarm robots offer fascinating opportunities to perform complex tasks beyond the capabilities of individual machines. Just as a swarm of ants collectively moves a large object, similar functions can emerge within a group of robots through individual strategies based on local sensing. However, realizing collective functions with individually controlled microrobots is particularly challenging due to their micrometer size, large number of degrees of freedom, strong thermal noise relative to the propulsion speed, complex physical coupling between neighboring microrobots, and surface collisions. Here, we implement Multi-Agent Reinforcement Learning (MARL) to generate a control strategy for up to 200 microrobots whose motions are individually controlled by laser spots. During the learning process, we employ so-called counterfactual rewards that automatically assign credit to the individual microrobots, which allows for fast and unbiased training. With the help of this efficient reward scheme, swarm microrobots learn to collectively transport a large cargo object to an arbitrary position and orientation, similar to ant swarms. We demonstrate that this flexible and versatile swarm robotic system is robust to variations in group size, the presence of malfunctioning units, and environmental noise. Such control strategies can potentially enable complex and automated assembly of mobile micromachines, programmable drug delivery capsules, and other advanced lab-on-a-chip applications.
Machine learning at the mesoscale: a computation-dissipation bottleneck
Jul 05, 2023The cost of information processing in physical systems calls for a trade-off between performance and energetic expenditure. Here we formulate and study a computation-dissipation bottleneck in mesoscopic systems used as input-output devices. Using both real datasets and synthetic tasks, we show how non-equilibrium leads to enhanced performance. Our framework sheds light on a crucial compromise between information compression, input-output computation and dynamic irreversibility induced by non-reciprocal interactions.