 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Hidden Mechanisms of Cross-Country Content Moderation with Natural Language Processing
Mar 07, 2025
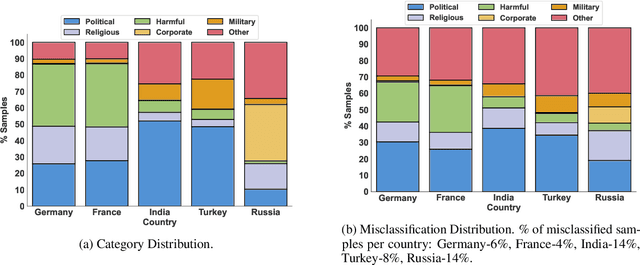
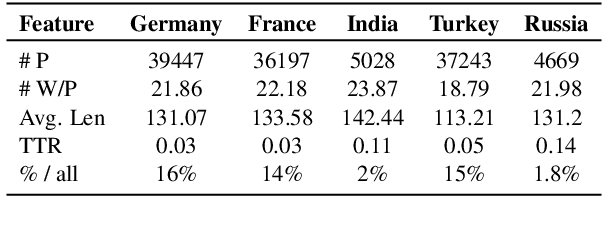
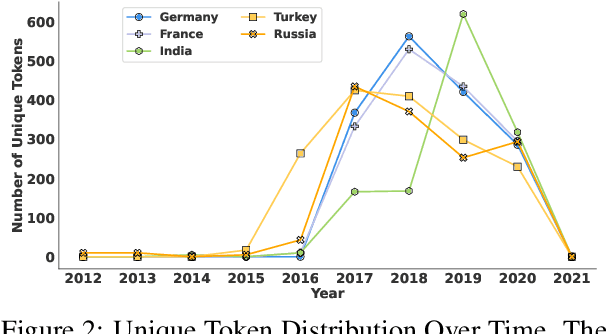
The ability of Natural Language Processing (NLP) methods to categorize text into multiple classes has motivated their use in online content moderation tasks, such as hate speech and fake news detection. However, there is limited understanding of how or why these methods make such decisions, or why certain content is moderated in the first place. To investigate the hidden mechanisms behind content moderation, we explore multiple directions: 1) training classifiers to reverse-engineer content moderation decisions across countries; 2) explaining content moderation decisions by analyzing Shapley values and LLM-guided explanations. Our primary focus is on content moderation decisions made across countries, using pre-existing corpora sampled from the Twitter Stream Grab. Our experiments reveal interesting patterns in censored posts, both across countries and over time. Through human evaluations of LLM-generated explanations across three LLMs, we assess the effectiveness of using LLMs in content moderation. Finally, we discuss potential future directions, as well as the limitations and ethical considerations of this work. Our code and data are available at https://github.com/causalNLP/censorship