 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Capability Frontier: Benchmarks Miss 82% of Model Performance
Jun 25, 2026Existing benchmarks typically report accuracy for a single model on a single run. This systematically understates real-world LLM capabilities, particularly under heterogeneous data distributions: (i) different models get different questions correct according to their specializations, and (ii) given a budget, multiple generations can be sampled and selectively retained. To quantify this gap, we introduce the Capability Frontier: a Pareto frontier over a set of models that characterizes the best achievable performance at each cost level under optimal selection across models and generations (i.e., via an oracle). Our construction corrects for two opposing biases: underestimation from single-model evaluation and overestimation from taking maxima over noisy samples. We study 21 LLMs across 16 widely used benchmarks spanning coding, reasoning, medicine, factuality, instruction following, and agentic tasks, comparing Capability Frontier performance at matched cost to each benchmark's top-performing model. Correcting for single-model evaluation yields a 54% error rate reduction; additionally correcting for single runs yields an 82% improvement, with SOTA accuracy matched at 85% cost reduction. Complementing these empirical results, we use controlled probabilistic simulations to show that higher query topic entropy produces a near-monotonic increase in the performance gap between oracle routing and the best single model. Our findings suggest collective LLM capabilities are substantially underestimated, with implications for evaluation and deployment in data-heterogeneous, multi-domain settings.
Ablation-Reversible Heads Don't Transfer: A Stress Test for Mechanistic Role Claims in Transformers
Jun 06, 2026In mechanistic interpretability, attention heads are commonly elevated to role claims (e.g., "this head represents addition") when they are necessary for a behavior, encode it linearly, and recover that behavior when restored after ablation. We show this evidence is insufficient: across three 7-8B instruction-tuned models and five computation families, heads passing all three checks routinely fail to transfer the computation when their activations are patched into a different prompt under matched controls. We introduce KID (Knowing / Intent / Doing), a role-assignment lens for attention heads, and pair it with a three-stage pipeline: capability-selective screening (CSS), singular value decomposition (SVD), and activation transduction under matched controls. Our results document a preliminary role taxonomy (including prompt-trajectory stabilizers, answer-side logit-bias heads, and soft computation-pattern carriers) and show that the same-answer control (a transduction target sharing the answer string but not the requested computation) is an underused check that exposes broad state transfer masquerading as semantic specificity.
Riemannian-Manifold Steering: Geometry-Aware Generative Autoencoders for Label-Free Steering
May 24, 2026Steering a language model - intervening on its internal activations to change downstream behaviour - has recently expanded beyond linear interpolation to nonlinear methods such as angular and kernelized steering, which define intervention transformations without learning an explicit geometry over paths in activation space. Freshly introduced geometry-aware manifold methods do learn such a geometry, but require labelled class centroids together with prescribed cyclic or sequential structure. These assumptions restrict where manifold steering can be applied, since existing constructions require labelled centroids and compatible boundary conditions. We recast manifold steering more broadly as \textbf{Riemannian geodesic computation} on activation space, recovering linear and labelled-spline steering as geodesics under particular choices of metric. A principled metric within this framework is the output-space Hellinger distance pulled back to activations; we approximate this with a learned encoder trained on output distances over a small concept-token schema - no per-prompt labels, no topology prior, and no per-task curve fitting. Empirically, the method reliably drives the model onto the target class across all tasks in a standard four-task language-model arithmetic benchmark, while following more behaviourally natural trajectories than baselines on smaller output spaces. We thereby provide a unified Riemannian framework for manifold steering together with a schema-supervised, label-free instantiation that operates without labelled centroids or prescribed boundary conditions.
Position: Require Frontier AI Labs To Release Small "Analog" Models
Oct 15, 2025Recent proposals for regulating frontier AI models have sparked concerns about the cost of safety regulation, and most such regulations have been shelved due to the safety-innovation tradeoff. This paper argues for an alternative regulatory approach that ensures AI safety while actively promoting innovation: mandating that large AI laboratories release small, openly accessible analog models (scaled-down versions) trained similarly to and distilled from their largest proprietary models. Analog models serve as public proxies, allowing broad participation in safety verification, interpretability research, and algorithmic transparency without forcing labs to disclose their full-scale models. Recent research demonstrates that safety and interpretability methods developed using these smaller models generalize effectively to frontier-scale systems. By enabling the wider research community to directly investigate and innovate upon accessible analogs, our policy substantially reduces the regulatory burden and accelerates safety advancements. This mandate promises minimal additional costs, leveraging reusable resources like data and infrastructure, while significantly contributing to the public good. Our hope is not only that this policy be adopted, but that it illustrates a broader principle supporting fundamental research in machine learning: deeper understanding of models relaxes the safety-innovation tradeoff and lets us have more of both.
TinySQL: A Progressive Text-to-SQL Dataset for Mechanistic Interpretability Research
Mar 17, 2025Mechanistic interpretability research faces a gap between analyzing simple circuits in toy tasks and discovering features in large models. To bridge this gap, we propose text-to-SQL generation as an ideal task to study, as it combines the formal structure of toy tasks with real-world complexity. We introduce TinySQL, a synthetic dataset progressing from basic to advanced SQL operations, and train models ranging from 33M to 1B parameters to establish a comprehensive testbed for interpretability. We apply multiple complementary interpretability techniques, including edge attribution patching and sparse autoencoders, to identify minimal circuits and components supporting SQL generation. Our analysis reveals both the potential and limitations of current interpretability methods, showing how circuits can vary even across similar queries. Lastly, we demonstrate how mechanistic interpretability can identify flawed heuristics in models and improve synthetic dataset design. Our work provides a comprehensive framework for evaluating and advancing interpretability techniques while establishing clear boundaries for their reliable application.
Increasing Trust in Language Models through the Reuse of Verified Circuits
Feb 06, 2024Language Models (LMs) are increasingly used for a wide range of prediction tasks, but their training can often neglect rare edge cases, reducing their reliability. Here, we define a stringent standard of trustworthiness whereby the task algorithm and circuit implementation must be verified, accounting for edge cases, with no known failure modes. We show that a transformer model can be trained to meet this standard if built using mathematically and logically specified frameworks. In this paper, we fully verify a model for n-digit integer addition. To exhibit the reusability of verified modules, we insert the trained integer addition model into an untrained model and train the combined model to perform both addition and subtraction. We find extensive reuse of the addition circuits for both tasks, easing verification of the more complex subtractor model. We discuss how inserting verified task modules into LMs can leverage model reuse to improve verifiability and trustworthiness of language models built using them. The reuse of verified circuits reduces the effort to verify more complex composite models which we believe to be a significant step towards safety of language models.
Understanding Addition in Transformers
Oct 23, 2023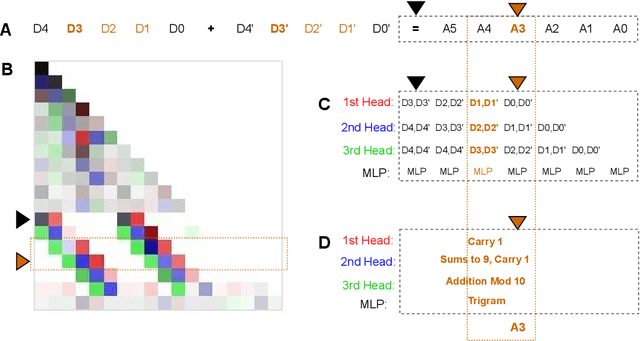
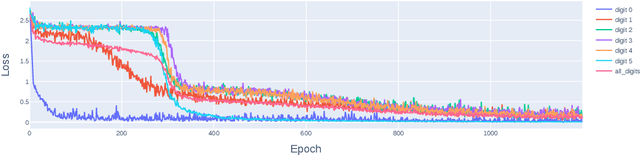
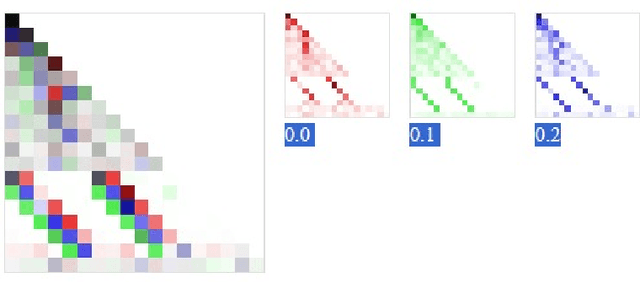
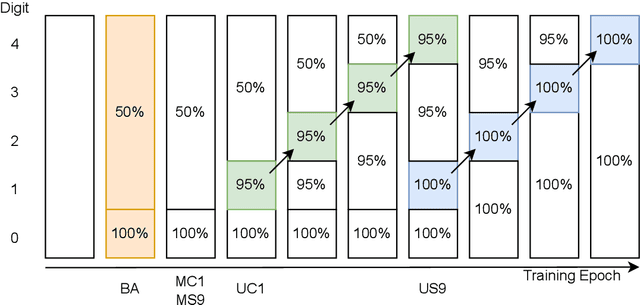
Understanding the inner workings of machine learning models like Transformers is vital for their safe and ethical use. This paper presents an in-depth analysis of a one-layer Transformer model trained for integer addition. We reveal that the model divides the task into parallel, digit-specific streams and employs distinct algorithms for different digit positions. Our study also finds that the model starts calculations late but executes them rapidly. A rare use case with high loss is identified and explained. Overall, the model's algorithm is explained in detail. These findings are validated through rigorous testing and mathematical modeling, contributing to the broader works in Mechanistic Interpretability, AI safety, and alignment. Our approach opens the door for analyzing more complex tasks and multi-layer Transformer models.
Fully transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study
Jan 23, 2023



Background: Deep learning (DL) can extract predictive and prognostic biomarkers from routine pathology slides in colorectal cancer. For example, a DL test for the diagnosis of microsatellite instability (MSI) in CRC has been approved in 2022. Current approaches rely on convolutional neural networks (CNNs). Transformer networks are outperforming CNNs and are replacing them in many applications, but have not been used for biomarker prediction in cancer at a large scale. In addition, most DL approaches have been trained on small patient cohorts, which limits their clinical utility. Methods: In this study, we developed a new fully transformer-based pipeline for end-to-end biomarker prediction from pathology slides. We combine a pre-trained transformer encoder and a transformer network for patch aggregation, capable of yielding single and multi-target prediction at patient level. We train our pipeline on over 9,000 patients from 10 colorectal cancer cohorts. Results: A fully transformer-based approach massively improves the performance, generalizability, data efficiency, and interpretability as compared with current state-of-the-art algorithms. After training on a large multicenter cohort, we achieve a sensitivity of 0.97 with a negative predictive value of 0.99 for MSI prediction on surgical resection specimens. We demonstrate for the first time that resection specimen-only training reaches clinical-grade performance on endoscopic biopsy tissue, solving a long-standing diagnostic problem. Interpretation: A fully transformer-based end-to-end pipeline trained on thousands of pathology slides yields clinical-grade performance for biomarker prediction on surgical resections and biopsies. Our new methods are freely available under an open source license.