 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFootprint-Guided Exemplar-Free Continual Histopathology Report Generation
Feb 27, 2026Rapid progress in vision-language modeling has enabled pathology report generation from gigapixel whole-slide images, but most approaches assume static training with simultaneous access to all data. In clinical deployment, however, new organs, institutions, and reporting conventions emerge over time, and sequential fine-tuning can cause catastrophic forgetting. We introduce an exemplar-free continual learning framework for WSI-to-report generation that avoids storing raw slides or patch exemplars. The core idea is a compact domain footprint built in a frozen patch-embedding space: a small codebook of representative morphology tokens together with slide-level co-occurrence summaries and lightweight patch-count priors. These footprints support generative replay by synthesizing pseudo-WSI representations that reflect domain-specific morphological mixtures, while a teacher snapshot provides pseudo-reports to supervise the updated model without retaining past data. To address shifting reporting conventions, we distill domain-specific linguistic characteristics into a compact style descriptor and use it to steer generation. At inference, the model identifies the most compatible descriptor directly from the slide signal, enabling domain-agnostic setup without requiring explicit domain identifiers. Evaluated across multiple public continual learning benchmarks, our approach outperforms exemplar-free and limited-buffer rehearsal baselines, highlighting footprint-based generative replay as a practical solution for deployment in evolving clinical settings.
From Classification to Cross-Modal Understanding: Leveraging Vision-Language Models for Fine-Grained Renal Pathology
Nov 15, 2025Fine-grained glomerular subtyping is central to kidney biopsy interpretation, but clinically valuable labels are scarce and difficult to obtain. Existing computational pathology approaches instead tend to evaluate coarse diseased classification under full supervision with image-only models, so it remains unclear how vision-language models (VLMs) should be adapted for clinically meaningful subtyping under data constraints. In this work, we model fine-grained glomerular subtyping as a clinically realistic few-shot problem and systematically evaluate both pathology-specialized and general-purpose vision-language models under this setting. We assess not only classification performance (accuracy, AUC, F1) but also the geometry of the learned representations, examining feature alignment between image and text embeddings and the separability of glomerular subtypes. By jointly analyzing shot count, model architecture and domain knowledge, and adaptation strategy, this study provides guidance for future model selection and training under real clinical data constraints. Our results indicate that pathology-specialized vision-language backbones, when paired with the vanilla fine-tuning, are the most effective starting point. Even with only 4-8 labeled examples per glomeruli subtype, these models begin to capture distinctions and show substantial gains in discrimination and calibration, though additional supervision continues to yield incremental improvements. We also find that the discrimination between positive and negative examples is as important as image-text alignment. Overall, our results show that supervision level and adaptation strategy jointly shape both diagnostic performance and multimodal structure, providing guidance for model selection, adaptation strategies, and annotation investment.
Attention-based Generative Latent Replay: A Continual Learning Approach for WSI Analysis
May 13, 2025



Whole slide image (WSI) classification has emerged as a powerful tool in computational pathology, but remains constrained by domain shifts, e.g., due to different organs, diseases, or institution-specific variations. To address this challenge, we propose an Attention-based Generative Latent Replay Continual Learning framework (AGLR-CL), in a multiple instance learning (MIL) setup for domain incremental WSI classification. Our method employs Gaussian Mixture Models (GMMs) to synthesize WSI representations and patch count distributions, preserving knowledge of past domains without explicitly storing original data. A novel attention-based filtering step focuses on the most salient patch embeddings, ensuring high-quality synthetic samples. This privacy-aware strategy obviates the need for replay buffers and outperforms other buffer-free counterparts while matching the performance of buffer-based solutions. We validate AGLR-CL on clinically relevant biomarker detection and molecular status prediction across multiple public datasets with diverse centers, organs, and patient cohorts. Experimental results confirm its ability to retain prior knowledge and adapt to new domains, offering an effective, privacy-preserving avenue for domain incremental continual learning in WSI classification.
Domain-incremental White Blood Cell Classification with Privacy-aware Continual Learning
Mar 25, 2025White blood cell (WBC) classification plays a vital role in hematology for diagnosing various medical conditions. However, it faces significant challenges due to domain shifts caused by variations in sample sources (e.g., blood or bone marrow) and differing imaging conditions across hospitals. Traditional deep learning models often suffer from catastrophic forgetting in such dynamic environments, while foundation models, though generally robust, experience performance degradation when the distribution of inference data differs from that of the training data. To address these challenges, we propose a generative replay-based Continual Learning (CL) strategy designed to prevent forgetting in foundation models for WBC classification. Our method employs lightweight generators to mimic past data with a synthetic latent representation to enable privacy-preserving replay. To showcase the effectiveness, we carry out extensive experiments with a total of four datasets with different task ordering and four backbone models including ResNet50, RetCCL, CTransPath, and UNI. Experimental results demonstrate that conventional fine-tuning methods degrade performance on previously learned tasks and struggle with domain shifts. In contrast, our continual learning strategy effectively mitigates catastrophic forgetting, preserving model performance across varying domains. This work presents a practical solution for maintaining reliable WBC classification in real-world clinical settings, where data distributions frequently evolve.
Continual Domain Incremental Learning for Privacy-aware Digital Pathology
Sep 10, 2024



In recent years, there has been remarkable progress in the field of digital pathology, driven by the ability to model complex tissue patterns using advanced deep-learning algorithms. However, the robustness of these models is often severely compromised in the presence of data shifts (e.g., different stains, organs, centers, etc.). Alternatively, continual learning (CL) techniques aim to reduce the forgetting of past data when learning new data with distributional shift conditions. Specifically, rehearsal-based CL techniques, which store some past data in a buffer and then replay it with new data, have proven effective in medical image analysis tasks. However, privacy concerns arise as these approaches store past data, prompting the development of our novel Generative Latent Replay-based CL (GLRCL) approach. GLRCL captures the previous distribution through Gaussian Mixture Models instead of storing past samples, which are then utilized to generate features and perform latent replay with new data. We systematically evaluate our proposed framework under different shift conditions in histopathology data, including stain and organ shift. Our approach significantly outperforms popular buffer-free CL approaches and performs similarly to rehearsal-based CL approaches that require large buffers causing serious privacy violations.
Unsupervised Latent Stain Adaptation for Computational Pathology
Jul 03, 2024In computational pathology, deep learning (DL) models for tasks such as segmentation or tissue classification are known to suffer from domain shifts due to different staining techniques. Stain adaptation aims to reduce the generalization error between different stains by training a model on source stains that generalizes to target stains. Despite the abundance of target stain data, a key challenge is the lack of annotations. To address this, we propose a joint training between artificially labeled and unlabeled data including all available stained images called Unsupervised Latent Stain Adaptation (ULSA). Our method uses stain translation to enrich labeled source images with synthetic target images in order to increase the supervised signals. Moreover, we leverage unlabeled target stain images using stain-invariant feature consistency learning. With ULSA we present a semi-supervised strategy for efficient stain adaptation without access to annotated target stain data. Remarkably, ULSA is task agnostic in patch-level analysis for whole slide images (WSIs). Through extensive evaluation on external datasets, we demonstrate that ULSA achieves state-of-the-art (SOTA) performance in kidney tissue segmentation and breast cancer classification across a spectrum of staining variations. Our findings suggest that ULSA is an important framework for stain adaptation in computational pathology.
Unsupervised Latent Stain Adaption for Digital Pathology
Jun 27, 2024In digital pathology, deep learning (DL) models for tasks such as segmentation or tissue classification are known to suffer from domain shifts due to different staining techniques. Stain adaptation aims to reduce the generalization error between different stains by training a model on source stains that generalizes to target stains. Despite the abundance of target stain data, a key challenge is the lack of annotations. To address this, we propose a joint training between artificially labeled and unlabeled data including all available stained images called Unsupervised Latent Stain Adaption (ULSA). Our method uses stain translation to enrich labeled source images with synthetic target images in order to increase supervised signals. Moreover, we leverage unlabeled target stain images using stain-invariant feature consistency learning. With ULSA we present a semi-supervised strategy for efficient stain adaption without access to annotated target stain data. Remarkably, ULSA is task agnostic in patch-level analysis for whole slide images (WSIs). Through extensive evaluation on external datasets, we demonstrate that ULSA achieves state-of-the-art (SOTA) performance in kidney tissue segmentation and breast cancer classification across a spectrum of staining variations. Our findings suggest that ULSA is an important framework towards stain adaption in digital pathology.
Fully transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study
Jan 23, 2023



Background: Deep learning (DL) can extract predictive and prognostic biomarkers from routine pathology slides in colorectal cancer. For example, a DL test for the diagnosis of microsatellite instability (MSI) in CRC has been approved in 2022. Current approaches rely on convolutional neural networks (CNNs). Transformer networks are outperforming CNNs and are replacing them in many applications, but have not been used for biomarker prediction in cancer at a large scale. In addition, most DL approaches have been trained on small patient cohorts, which limits their clinical utility. Methods: In this study, we developed a new fully transformer-based pipeline for end-to-end biomarker prediction from pathology slides. We combine a pre-trained transformer encoder and a transformer network for patch aggregation, capable of yielding single and multi-target prediction at patient level. We train our pipeline on over 9,000 patients from 10 colorectal cancer cohorts. Results: A fully transformer-based approach massively improves the performance, generalizability, data efficiency, and interpretability as compared with current state-of-the-art algorithms. After training on a large multicenter cohort, we achieve a sensitivity of 0.97 with a negative predictive value of 0.99 for MSI prediction on surgical resection specimens. We demonstrate for the first time that resection specimen-only training reaches clinical-grade performance on endoscopic biopsy tissue, solving a long-standing diagnostic problem. Interpretation: A fully transformer-based end-to-end pipeline trained on thousands of pathology slides yields clinical-grade performance for biomarker prediction on surgical resections and biopsies. Our new methods are freely available under an open source license.
Local Attention Graph-based Transformer for Multi-target Genetic Alteration Prediction
May 13, 2022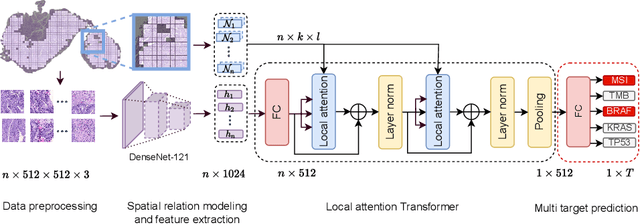

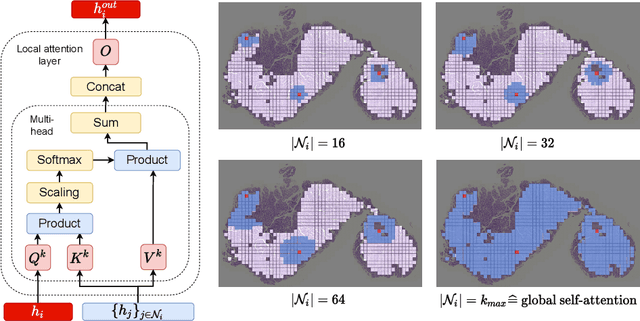
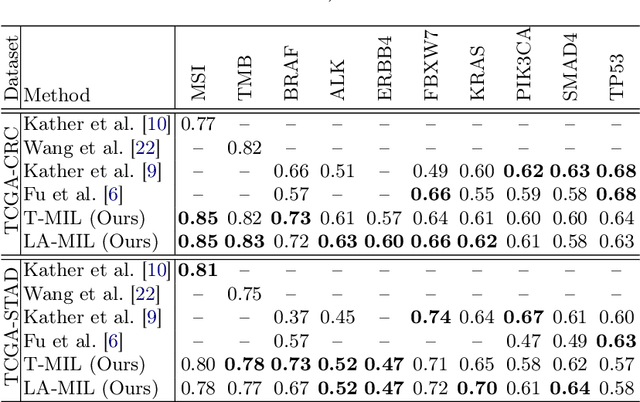
Classical multiple instance learning (MIL) methods are often based on the identical and independent distributed assumption between instances, hence neglecting the potentially rich contextual information beyond individual entities. On the other hand, Transformers with global self-attention modules have been proposed to model the interdependencies among all instances. However, in this paper we question: Is global relation modeling using self-attention necessary, or can we appropriately restrict self-attention calculations to local regimes in large-scale whole slide images (WSIs)? We propose a general-purpose local attention graph-based Transformer for MIL (LA-MIL), introducing an inductive bias by explicitly contextualizing instances in adaptive local regimes of arbitrary size. Additionally, an efficiently adapted loss function enables our approach to learn expressive WSI embeddings for the joint analysis of multiple biomarkers. We demonstrate that LA-MIL achieves state-of-the-art results in mutation prediction for gastrointestinal cancer, outperforming existing models on important biomarkers such as microsatellite instability for colorectal cancer. This suggests that local self-attention sufficiently models dependencies on par with global modules. Our implementation will be published.