 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFootprint-Guided Exemplar-Free Continual Histopathology Report Generation
Feb 27, 2026Rapid progress in vision-language modeling has enabled pathology report generation from gigapixel whole-slide images, but most approaches assume static training with simultaneous access to all data. In clinical deployment, however, new organs, institutions, and reporting conventions emerge over time, and sequential fine-tuning can cause catastrophic forgetting. We introduce an exemplar-free continual learning framework for WSI-to-report generation that avoids storing raw slides or patch exemplars. The core idea is a compact domain footprint built in a frozen patch-embedding space: a small codebook of representative morphology tokens together with slide-level co-occurrence summaries and lightweight patch-count priors. These footprints support generative replay by synthesizing pseudo-WSI representations that reflect domain-specific morphological mixtures, while a teacher snapshot provides pseudo-reports to supervise the updated model without retaining past data. To address shifting reporting conventions, we distill domain-specific linguistic characteristics into a compact style descriptor and use it to steer generation. At inference, the model identifies the most compatible descriptor directly from the slide signal, enabling domain-agnostic setup without requiring explicit domain identifiers. Evaluated across multiple public continual learning benchmarks, our approach outperforms exemplar-free and limited-buffer rehearsal baselines, highlighting footprint-based generative replay as a practical solution for deployment in evolving clinical settings.
Towards Modality-Agnostic Continual Domain-Incremental Brain Lesion Segmentation
Jan 20, 2026Brain lesion segmentation from multi-modal MRI often assumes fixed modality sets or predefined pathologies, making existing models difficult to adapt across cohorts and imaging protocols. Continual learning (CL) offers a natural solution but current approaches either impose a maximum modality configuration or suffer from severe forgetting in buffer-free settings. We introduce CLMU-Net, a replay-based CL framework for 3D brain lesion segmentation that supports arbitrary and variable modality combinations without requiring prior knowledge of the maximum set. A conceptually simple yet effective channel-inflation strategy maps any modality subset into a unified multi-channel representation, enabling a single model to operate across diverse datasets. To enrich inherently local 3D patch features, we incorporate lightweight domain-conditioned textual embeddings that provide global modality-disease context for each training case. Forgetting is further reduced through principled replay using a compact buffer composed of both prototypical and challenging samples. Experiments on five heterogeneous MRI brain datasets demonstrate that CLMU-Net consistently outperforms popular CL baselines. Notably, our method yields an average Dice score improvement of $\geq$ 18\% while remaining robust under heterogeneous-modality conditions. These findings underscore the value of flexible modality handling, targeted replay, and global contextual cues for continual medical image segmentation. Our implementation is available at https://github.com/xmindflow/CLMU-Net.
Attention-based Generative Latent Replay: A Continual Learning Approach for WSI Analysis
May 13, 2025



Whole slide image (WSI) classification has emerged as a powerful tool in computational pathology, but remains constrained by domain shifts, e.g., due to different organs, diseases, or institution-specific variations. To address this challenge, we propose an Attention-based Generative Latent Replay Continual Learning framework (AGLR-CL), in a multiple instance learning (MIL) setup for domain incremental WSI classification. Our method employs Gaussian Mixture Models (GMMs) to synthesize WSI representations and patch count distributions, preserving knowledge of past domains without explicitly storing original data. A novel attention-based filtering step focuses on the most salient patch embeddings, ensuring high-quality synthetic samples. This privacy-aware strategy obviates the need for replay buffers and outperforms other buffer-free counterparts while matching the performance of buffer-based solutions. We validate AGLR-CL on clinically relevant biomarker detection and molecular status prediction across multiple public datasets with diverse centers, organs, and patient cohorts. Experimental results confirm its ability to retain prior knowledge and adapt to new domains, offering an effective, privacy-preserving avenue for domain incremental continual learning in WSI classification.
Modality-Independent Brain Lesion Segmentation with Privacy-aware Continual Learning
Mar 26, 2025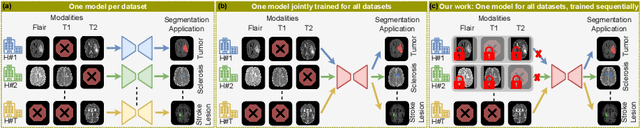

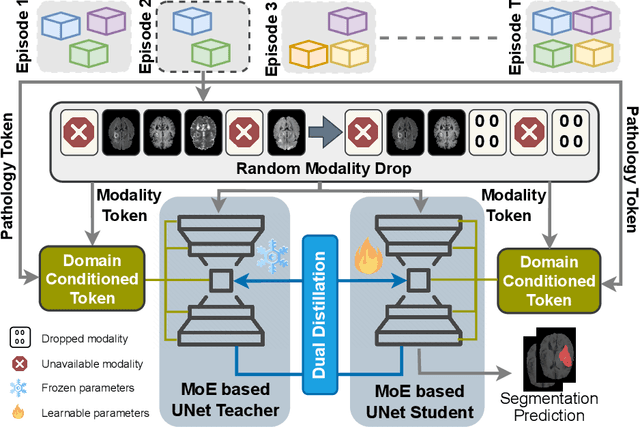
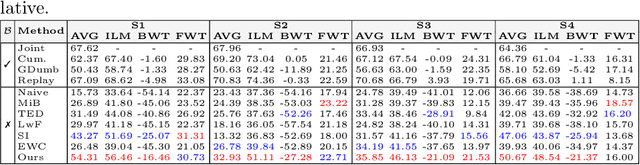
Traditional brain lesion segmentation models for multi-modal MRI are typically tailored to specific pathologies, relying on datasets with predefined modalities. Adapting to new MRI modalities or pathologies often requires training separate models, which contrasts with how medical professionals incrementally expand their expertise by learning from diverse datasets over time. Inspired by this human learning process, we propose a unified segmentation model capable of sequentially learning from multiple datasets with varying modalities and pathologies. Our approach leverages a privacy-aware continual learning framework that integrates a mixture-of-experts mechanism and dual knowledge distillation to mitigate catastrophic forgetting while not compromising performance on newly encountered datasets. Extensive experiments across five diverse brain MRI datasets and four dataset sequences demonstrate the effectiveness of our framework in maintaining a single adaptable model, capable of handling varying hospital protocols, imaging modalities, and disease types. Compared to widely used privacy-aware continual learning methods such as LwF, SI, EWC, and MiB, our method achieves an average Dice score improvement of approximately 11%. Our framework represents a significant step toward more versatile and practical brain lesion segmentation models, with implementation available at \href{https://github.com/xmindflow/BrainCL}{GitHub}.
Domain-incremental White Blood Cell Classification with Privacy-aware Continual Learning
Mar 25, 2025White blood cell (WBC) classification plays a vital role in hematology for diagnosing various medical conditions. However, it faces significant challenges due to domain shifts caused by variations in sample sources (e.g., blood or bone marrow) and differing imaging conditions across hospitals. Traditional deep learning models often suffer from catastrophic forgetting in such dynamic environments, while foundation models, though generally robust, experience performance degradation when the distribution of inference data differs from that of the training data. To address these challenges, we propose a generative replay-based Continual Learning (CL) strategy designed to prevent forgetting in foundation models for WBC classification. Our method employs lightweight generators to mimic past data with a synthetic latent representation to enable privacy-preserving replay. To showcase the effectiveness, we carry out extensive experiments with a total of four datasets with different task ordering and four backbone models including ResNet50, RetCCL, CTransPath, and UNI. Experimental results demonstrate that conventional fine-tuning methods degrade performance on previously learned tasks and struggle with domain shifts. In contrast, our continual learning strategy effectively mitigates catastrophic forgetting, preserving model performance across varying domains. This work presents a practical solution for maintaining reliable WBC classification in real-world clinical settings, where data distributions frequently evolve.
Touchstone Benchmark: Are We on the Right Way for Evaluating AI Algorithms for Medical Segmentation?
Nov 06, 2024



How can we test AI performance? This question seems trivial, but it isn't. Standard benchmarks often have problems such as in-distribution and small-size test sets, oversimplified metrics, unfair comparisons, and short-term outcome pressure. As a consequence, good performance on standard benchmarks does not guarantee success in real-world scenarios. To address these problems, we present Touchstone, a large-scale collaborative segmentation benchmark of 9 types of abdominal organs. This benchmark is based on 5,195 training CT scans from 76 hospitals around the world and 5,903 testing CT scans from 11 additional hospitals. This diverse test set enhances the statistical significance of benchmark results and rigorously evaluates AI algorithms across various out-of-distribution scenarios. We invited 14 inventors of 19 AI algorithms to train their algorithms, while our team, as a third party, independently evaluated these algorithms on three test sets. In addition, we also evaluated pre-existing AI frameworks--which, differing from algorithms, are more flexible and can support different algorithms--including MONAI from NVIDIA, nnU-Net from DKFZ, and numerous other open-source frameworks. We are committed to expanding this benchmark to encourage more innovation of AI algorithms for the medical domain.
Continual Domain Incremental Learning for Privacy-aware Digital Pathology
Sep 10, 2024



In recent years, there has been remarkable progress in the field of digital pathology, driven by the ability to model complex tissue patterns using advanced deep-learning algorithms. However, the robustness of these models is often severely compromised in the presence of data shifts (e.g., different stains, organs, centers, etc.). Alternatively, continual learning (CL) techniques aim to reduce the forgetting of past data when learning new data with distributional shift conditions. Specifically, rehearsal-based CL techniques, which store some past data in a buffer and then replay it with new data, have proven effective in medical image analysis tasks. However, privacy concerns arise as these approaches store past data, prompting the development of our novel Generative Latent Replay-based CL (GLRCL) approach. GLRCL captures the previous distribution through Gaussian Mixture Models instead of storing past samples, which are then utilized to generate features and perform latent replay with new data. We systematically evaluate our proposed framework under different shift conditions in histopathology data, including stain and organ shift. Our approach significantly outperforms popular buffer-free CL approaches and performs similarly to rehearsal-based CL approaches that require large buffers causing serious privacy violations.
Characterizing Continual Learning Scenarios and Strategies for Audio Analysis
Jun 29, 2024



Audio analysis is useful in many application scenarios. The state-of-the-art audio analysis approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can encounter new classes in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we characterize continual learning (CL) approaches in audio analysis. In this paper, we characterize continual learning (CL) approaches, intended to tackle catastrophic forgetting arising due to drifts. As there is no CL dataset for audio analysis, we use DCASE 2020 to 2023 datasets to create various CL scenarios for audio-based monitoring tasks. We have investigated the following CL and non-CL approaches: EWC, LwF, SI, GEM, A-GEM, GDumb, Replay, Naive, cumulative, and joint training. The study is very beneficial for researchers and practitioners working in the area of audio analysis for developing adaptive models. We observed that Replay achieved better results than other methods in the DCASE challenge data. It achieved an accuracy of 70.12% for the domain incremental scenario and an accuracy of 96.98% for the class incremental scenario.
LHU-Net: A Light Hybrid U-Net for Cost-Efficient, High-Performance Volumetric Medical Image Segmentation
Apr 07, 2024As a result of the rise of Transformer architectures in medical image analysis, specifically in the domain of medical image segmentation, a multitude of hybrid models have been created that merge the advantages of Convolutional Neural Networks (CNNs) and Transformers. These hybrid models have achieved notable success by significantly improving segmentation accuracy. Yet, this progress often comes at the cost of increased model complexity, both in terms of parameters and computational demand. Moreover, many of these models fail to consider the crucial interplay between spatial and channel features, which could further refine and improve segmentation outcomes. To address this, we introduce LHU-Net, a Light Hybrid U-Net architecture optimized for volumetric medical image segmentation. LHU-Net is meticulously designed to prioritize spatial feature analysis in its initial layers before shifting focus to channel-based features in its deeper layers, ensuring a comprehensive feature extraction process. Rigorous evaluation across five benchmark datasets - Synapse, LA, Pancreas, ACDC, and BRaTS 2018 - underscores LHU-Net's superior performance, showcasing its dual capacity for efficiency and accuracy. Notably, LHU-Net sets new performance benchmarks, such as attaining a Dice score of 92.66 on the ACDC dataset, while simultaneously reducing parameters by 85% and quartering the computational load compared to existing state-of-the-art models. Achieved without any reliance on pre-training, additional data, or model ensemble, LHU-Net's effectiveness is further evidenced by its state-of-the-art performance across all evaluated datasets, utilizing fewer than 11 million parameters. This achievement highlights that balancing computational efficiency with high accuracy in medical image segmentation is feasible. Our implementation of LHU-Net is freely accessible to the research community on GitHub.
Continual Learning in Medical Imaging Analysis: A Comprehensive Review of Recent Advancements and Future Prospects
Dec 28, 2023



Medical imaging analysis has witnessed remarkable advancements even surpassing human-level performance in recent years, driven by the rapid development of advanced deep-learning algorithms. However, when the inference dataset slightly differs from what the model has seen during one-time training, the model performance is greatly compromised. The situation requires restarting the training process using both the old and the new data which is computationally costly, does not align with the human learning process, and imposes storage constraints and privacy concerns. Alternatively, continual learning has emerged as a crucial approach for developing unified and sustainable deep models to deal with new classes, tasks, and the drifting nature of data in non-stationary environments for various application areas. Continual learning techniques enable models to adapt and accumulate knowledge over time, which is essential for maintaining performance on evolving datasets and novel tasks. This systematic review paper provides a comprehensive overview of the state-of-the-art in continual learning techniques applied to medical imaging analysis. We present an extensive survey of existing research, covering topics including catastrophic forgetting, data drifts, stability, and plasticity requirements. Further, an in-depth discussion of key components of a continual learning framework such as continual learning scenarios, techniques, evaluation schemes, and metrics is provided. Continual learning techniques encompass various categories, including rehearsal, regularization, architectural, and hybrid strategies. We assess the popularity and applicability of continual learning categories in various medical sub-fields like radiology and histopathology...