 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Guided Multi-Mutation Differential Evolution for Crop Model Calibration
Feb 26, 2026In this paper, we propose a multi-mutation optimization algorithm, Differential Evolution with Multi-Mutation Operator-Guided Communication (DE-MMOGC), implemented to improve the performance and convergence abilities of standard differential evolution in uncertain environments. DE-MMOGC introduces a communication-guided scheme integrated with multiple mutation operators to encourage exploration and avoid premature convergence. Along with this, it includes a dynamic operator selection mechanism to use the best-performing operator over successive generations. To assimilate real-world uncertainties and missing observations into the predictive model, the proposed algorithm is combined with the Ensemble Kalman Filter. To evaluate the efficacy of the proposed DE-MMOGC in uncertain systems, the unified framework is applied to improve the predictive accuracy of crop simulation models. These simulation models are essential to precision agriculture, as they make it easier to estimate crop growth in a variety of unpredictable weather scenarios. Additionally, precisely calibrating these models raises a challenge due to missing observations. Hence, the simplified WOFOST crop simulation model is incorporated in this study for leaf area index (LAI)-based crop yield estimation. DE-MMOGC enhances the WOFOST performance by optimizing crucial weather parameters (temperature and rainfall), since these parameters are highly uncertain across different crop varieties, such as wheat, rice, and cotton. The experimental study shows that DE-MMOGC outperforms the traditional evolutionary optimizers and achieves better correlation with real LAI values. We found that DE-MMOGC is a resilient solution for crop monitoring.
FLNet: Flood-Induced Agriculture Damage Assessment using Super Resolution of Satellite Images
Jan 07, 2026Distributing government relief efforts after a flood is challenging. In India, the crops are widely affected by floods; therefore, making rapid and accurate crop damage assessment is crucial for effective post-disaster agricultural management. Traditional manual surveys are slow and biased, while current satellite-based methods face challenges like cloud cover and low spatial resolution. Therefore, to bridge this gap, this paper introduced FLNet, a novel deep learning based architecture that used super-resolution to enhance the 10 m spatial resolution of Sentinel-2 satellite images into 3 m resolution before classifying damage. We tested our model on the Bihar Flood Impacted Croplands Dataset (BFCD-22), and the results showed an improved critical "Full Damage" F1-score from 0.83 to 0.89, nearly matching the 0.89 score of commercial high-resolution imagery. This work presented a cost-effective and scalable solution, paving the way for a nationwide shift from manual to automated, high-fidelity damage assessment.
From ChatGPT to DeepSeek AI: A Comprehensive Analysis of Evolution, Deviation, and Future Implications in AI-Language Models
Apr 04, 2025



The rapid advancement of artificial intelligence (AI) has reshaped the field of natural language processing (NLP), with models like OpenAI ChatGPT and DeepSeek AI. Although ChatGPT established a strong foundation for conversational AI, DeepSeek AI introduces significant improvements in architecture, performance, and ethical considerations. This paper presents a detailed analysis of the evolution from ChatGPT to DeepSeek AI, highlighting their technical differences, practical applications, and broader implications for AI development. To assess their capabilities, we conducted a case study using a predefined set of multiple choice questions in various domains, evaluating the strengths and limitations of each model. By examining these aspects, we provide valuable insight into the future trajectory of AI, its potential to transform industries, and key research directions for improving AI-driven language models.
Characterizing Continual Learning Scenarios and Strategies for Audio Analysis
Jun 29, 2024



Audio analysis is useful in many application scenarios. The state-of-the-art audio analysis approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can encounter new classes in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we characterize continual learning (CL) approaches in audio analysis. In this paper, we characterize continual learning (CL) approaches, intended to tackle catastrophic forgetting arising due to drifts. As there is no CL dataset for audio analysis, we use DCASE 2020 to 2023 datasets to create various CL scenarios for audio-based monitoring tasks. We have investigated the following CL and non-CL approaches: EWC, LwF, SI, GEM, A-GEM, GDumb, Replay, Naive, cumulative, and joint training. The study is very beneficial for researchers and practitioners working in the area of audio analysis for developing adaptive models. We observed that Replay achieved better results than other methods in the DCASE challenge data. It achieved an accuracy of 70.12% for the domain incremental scenario and an accuracy of 96.98% for the class incremental scenario.
Concept Drift Challenge in Multimedia Anomaly Detection: A Case Study with Facial Datasets
Jul 27, 2022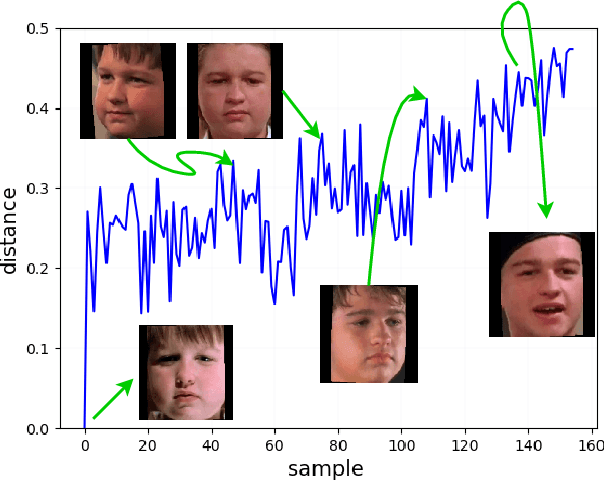
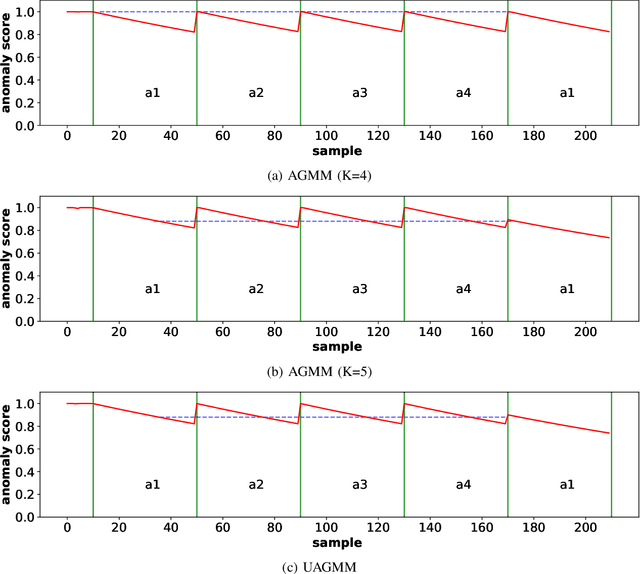
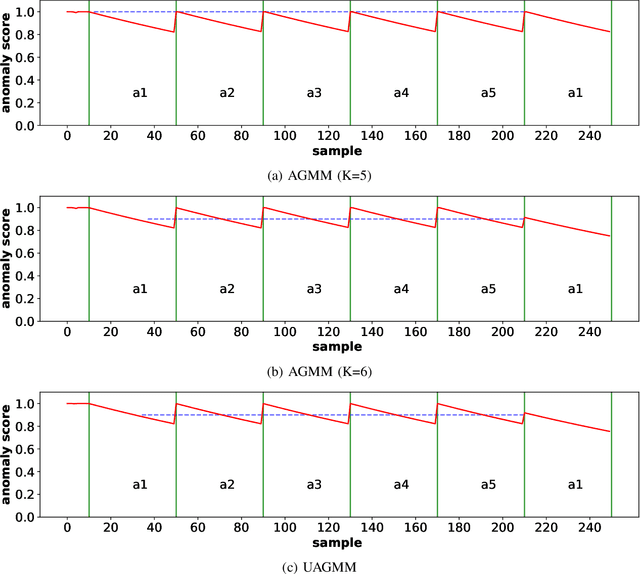
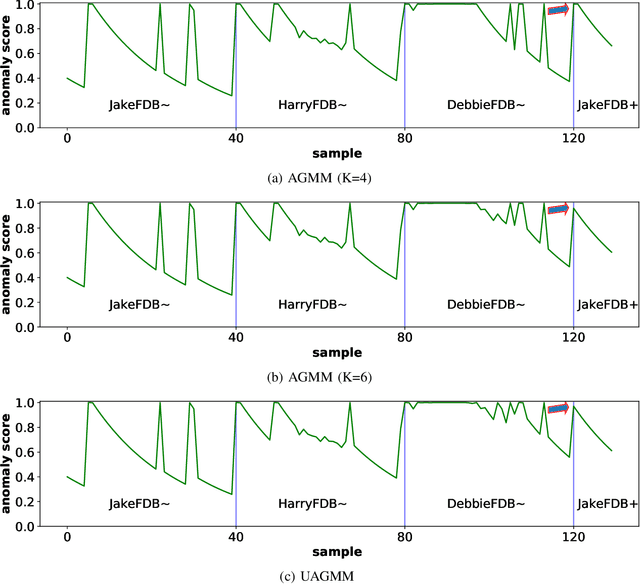
Anomaly detection in multimedia datasets is a widely studied area. Yet, the concept drift challenge in data has been ignored or poorly handled by the majority of the anomaly detection frameworks. The state-of-the-art approaches assume that the data distribution at training and deployment time will be the same. However, due to various real-life environmental factors, the data may encounter drift in its distribution or can drift from one class to another in the late future. Thus, a one-time trained model might not perform adequately. In this paper, we systematically investigate the effect of concept drift on various detection models and propose a modified Adaptive Gaussian Mixture Model (AGMM) based framework for anomaly detection in multimedia data. In contrast to the baseline AGMM, the proposed extension of AGMM remembers the past for a longer period in order to handle the drift better. Extensive experimental analysis shows that the proposed model better handles the drift in data as compared with the baseline AGMM. Further, to facilitate research and comparison with the proposed framework, we contribute three multimedia datasets constituting faces as samples. The face samples of individuals correspond to the age difference of more than ten years to incorporate a longer temporal context.
Multimedia Datasets for Anomaly Detection: A Survey
Dec 10, 2021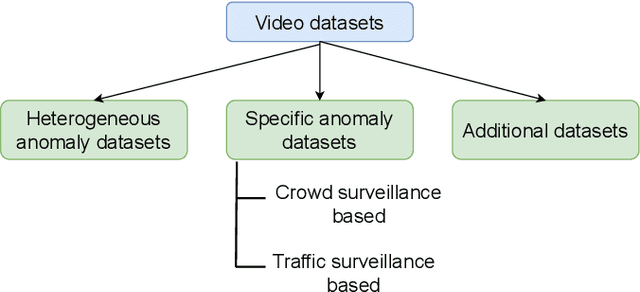


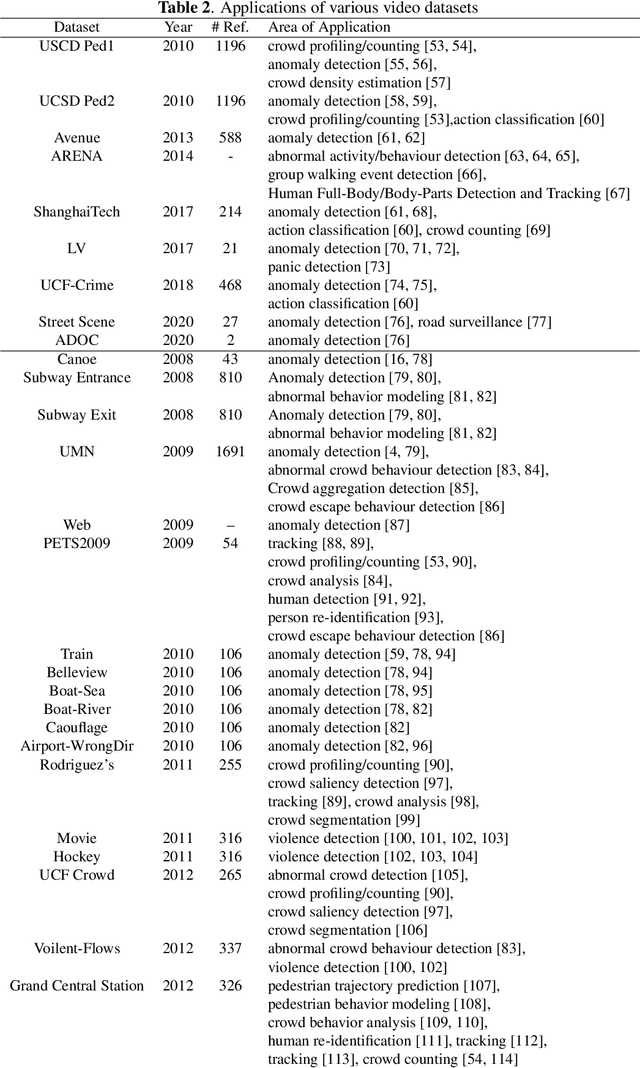
Multimedia anomaly datasets play a crucial role in automated surveillance. They have a wide range of applications expanding from outlier object/ situation detection to the detection of life-threatening events. This field is receiving a huge level of research interest for more than 1.5 decades, and consequently, more and more datasets dedicated to anomalous actions and object detection have been created. Tapping these public anomaly datasets enable researchers to generate and compare various anomaly detection frameworks with the same input data. This paper presents a comprehensive survey on a variety of video, audio, as well as audio-visual datasets based on the application of anomaly detection. This survey aims to address the lack of a comprehensive comparison and analysis of multimedia public datasets based on anomaly detection. Also, it can assist researchers in selecting the best available dataset for bench-marking frameworks. Additionally, we discuss gaps in the existing dataset and future direction insights towards developing multimodal anomaly detection datasets.
An End-to-End Framework for Dynamic Crime Profiling of Places
Nov 20, 2021
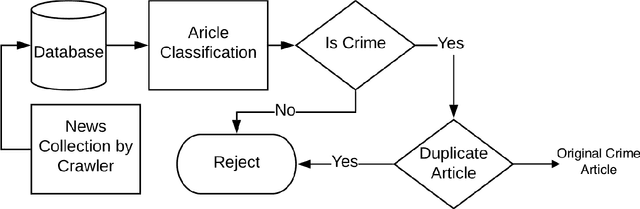


Much effort is being made to ensure the safety of people. One of the main requirements of travellers and city administrators is to have knowledge of places that are more prone to criminal activities. To rate a place as a potential crime location, it needs the past crime history at that location. Such data is not easily available in the public domain, however, it floats around on the Internet in the form of newspaper and social media posts, in an unstructured manner though. Consequently, a large number of works are reported on extracting crime information from news articles, providing piecemeal solutions to the problem. This chapter complements these works by building an end-to-end framework for crime profiling of any given location/area. It customizes individual components of the framework and provides a Spatio-temporal integration of crime information. It develops an automated framework that crawls online news articles, analyzes them, and extracts relevant information to create a crime knowledge base that gets dynamically updated in real-time. The crime density can be easily visualized in the form of a heat map which is generated by the knowledge base. As a case study, it investigates 345448 news articles published by 6 daily English newspapers collected for approximately two years. Experimental results show that the crime profiling matches with the ratings calculated manually by various organizations.
Anomaly Detection in Audio with Concept Drift using Adaptive Huffman Coding
Feb 21, 2021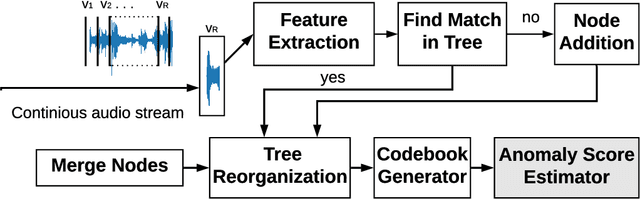

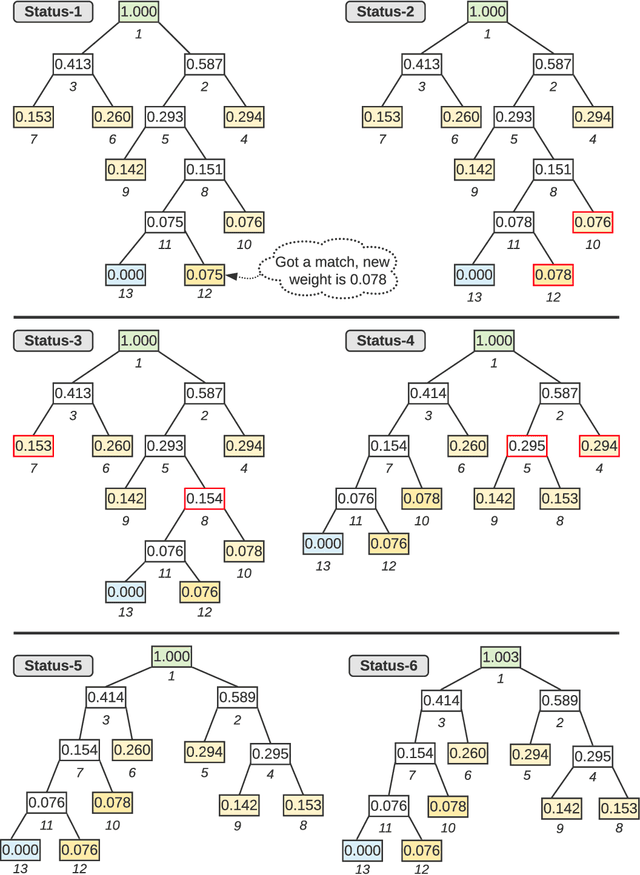
In this work, we propose a framework to apply Huffman coding for anomaly detection in audio. There are a number of advantages of using the Huffman coding technique for anomaly detection, such as less dependence on the a-priory information about clusters (e.g., number, size, density) and variable event length. The coding cost can be calculated for any duration of the audio. Huffman codes are mostly used to compress non-time series data or data without concept drift. However, the normal class distribution of audio data varies greatly with time due to environmental noise. In this work, we explore how to adapt the Huffman tree to incorporate this concept drift. We found that, instead of creating new nodes, merging existing nodes gives a more effective performance. Note that with node merging, you never actually forget the history, at least theoretically. To the best of our knowledge, this is the first work on applying Huffman coding techniques for anomaly detection in temporal data. Experiments show that this scheme improves the result without much computational overhead. The approach is time-efficient and can be easily extended to other types of time series data (e.g., video).
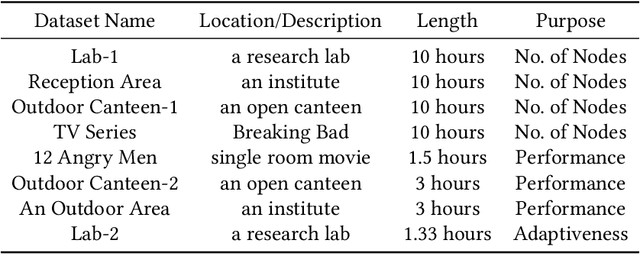
sZoom: A Framework for Automatic Zoom into High Resolution Surveillance Videos
Sep 23, 2019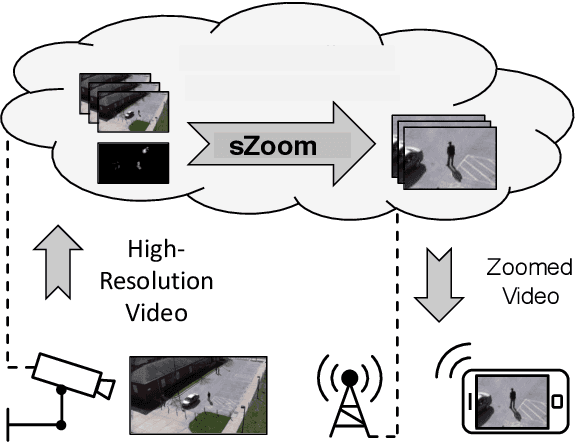

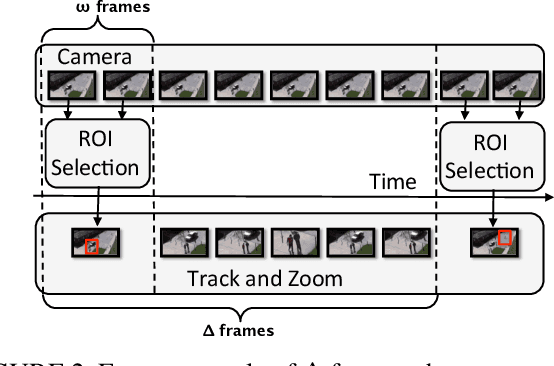
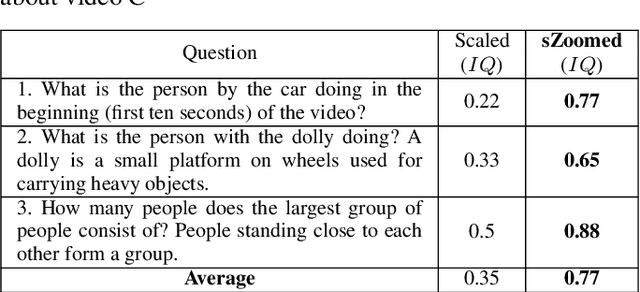
Current cameras are capable of recording high resolution video. While viewing on a mobile device, a user can manually zoom into this high resolution video to get more detailed view of objects and activities. However, manual zooming is not suitable for surveillance and monitoring. It is tiring to continuously keep zooming into various regions of the video. Also, while viewing one region, the operator may miss activities in other regions. In this paper, we propose sZoom, a framework to automatically zoom into a high resolution surveillance video. The proposed framework selectively zooms into the sensitive regions of the video to present details of the scene, while still preserving the overall context required for situation assessment. A multi-variate Gaussian penalty is introduced to ensure full coverage of the scene. The method achieves near real-time performance through a number of timing optimizations. An extensive user study shows that, while watching a full HD video on a mobile device, the system enhances the security operator's efficiency in understanding the details of the scene by 99% on the average compared to a scaled version of the original high resolution video. The produced video achieved 46% higher ratings for usefulness in a surveillance task.