 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Detection in Audio with Concept Drift using Adaptive Huffman Coding
Paper and Code
Feb 21, 2021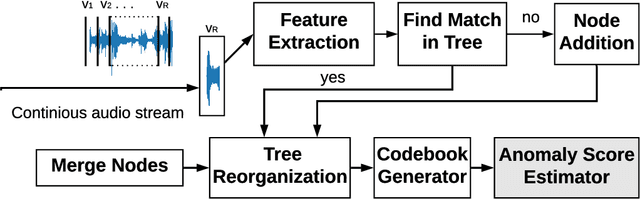

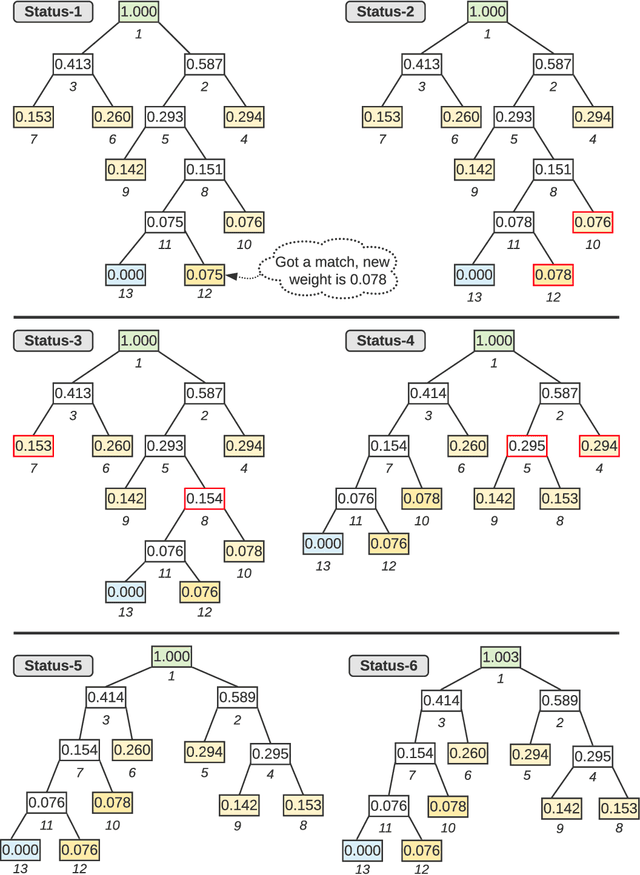
In this work, we propose a framework to apply Huffman coding for anomaly detection in audio. There are a number of advantages of using the Huffman coding technique for anomaly detection, such as less dependence on the a-priory information about clusters (e.g., number, size, density) and variable event length. The coding cost can be calculated for any duration of the audio. Huffman codes are mostly used to compress non-time series data or data without concept drift. However, the normal class distribution of audio data varies greatly with time due to environmental noise. In this work, we explore how to adapt the Huffman tree to incorporate this concept drift. We found that, instead of creating new nodes, merging existing nodes gives a more effective performance. Note that with node merging, you never actually forget the history, at least theoretically. To the best of our knowledge, this is the first work on applying Huffman coding techniques for anomaly detection in temporal data. Experiments show that this scheme improves the result without much computational overhead. The approach is time-efficient and can be easily extended to other types of time series data (e.g., video).