 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-Cos Aligned Transformers Learn Human-Interpretable Features
Jan 18, 2024Vision Transformers (ViTs) and Swin Transformers (Swin) are currently state-of-the-art in computational pathology. However, domain experts are still reluctant to use these models due to their lack of interpretability. This is not surprising, as critical decisions need to be transparent and understandable. The most common approach to understanding transformers is to visualize their attention. However, attention maps of ViTs are often fragmented, leading to unsatisfactory explanations. Here, we introduce a novel architecture called the B-cos Vision Transformer (BvT) that is designed to be more interpretable. It replaces all linear transformations with the B-cos transform to promote weight-input alignment. In a blinded study, medical experts clearly ranked BvTs above ViTs, suggesting that our network is better at capturing biomedically relevant structures. This is also true for the B-cos Swin Transformer (Bwin). Compared to the Swin Transformer, it even improves the F1-score by up to 4.7% on two public datasets.
Fully transformer-based biomarker prediction from colorectal cancer histology: a large-scale multicentric study
Jan 23, 2023



Background: Deep learning (DL) can extract predictive and prognostic biomarkers from routine pathology slides in colorectal cancer. For example, a DL test for the diagnosis of microsatellite instability (MSI) in CRC has been approved in 2022. Current approaches rely on convolutional neural networks (CNNs). Transformer networks are outperforming CNNs and are replacing them in many applications, but have not been used for biomarker prediction in cancer at a large scale. In addition, most DL approaches have been trained on small patient cohorts, which limits their clinical utility. Methods: In this study, we developed a new fully transformer-based pipeline for end-to-end biomarker prediction from pathology slides. We combine a pre-trained transformer encoder and a transformer network for patch aggregation, capable of yielding single and multi-target prediction at patient level. We train our pipeline on over 9,000 patients from 10 colorectal cancer cohorts. Results: A fully transformer-based approach massively improves the performance, generalizability, data efficiency, and interpretability as compared with current state-of-the-art algorithms. After training on a large multicenter cohort, we achieve a sensitivity of 0.97 with a negative predictive value of 0.99 for MSI prediction on surgical resection specimens. We demonstrate for the first time that resection specimen-only training reaches clinical-grade performance on endoscopic biopsy tissue, solving a long-standing diagnostic problem. Interpretation: A fully transformer-based end-to-end pipeline trained on thousands of pathology slides yields clinical-grade performance for biomarker prediction on surgical resections and biopsies. Our new methods are freely available under an open source license.
Local Attention Graph-based Transformer for Multi-target Genetic Alteration Prediction
May 13, 2022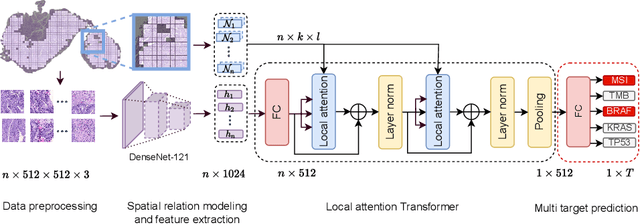

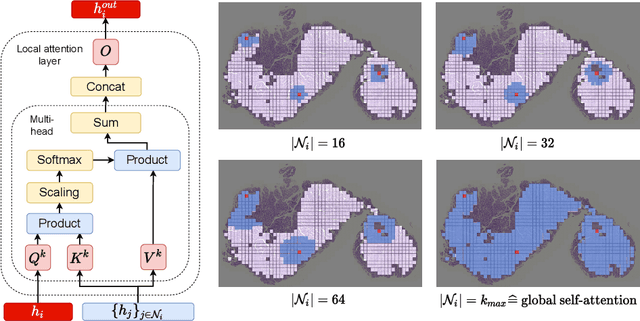
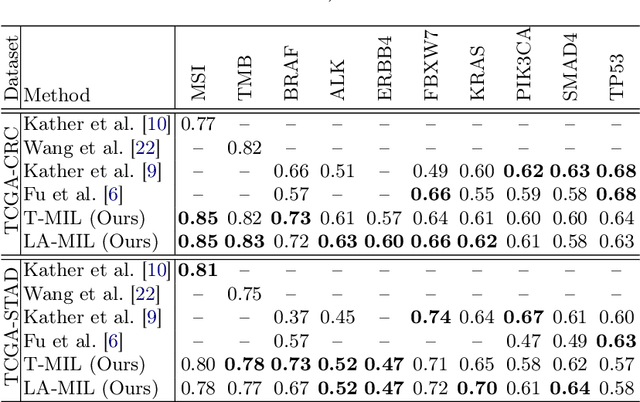
Classical multiple instance learning (MIL) methods are often based on the identical and independent distributed assumption between instances, hence neglecting the potentially rich contextual information beyond individual entities. On the other hand, Transformers with global self-attention modules have been proposed to model the interdependencies among all instances. However, in this paper we question: Is global relation modeling using self-attention necessary, or can we appropriately restrict self-attention calculations to local regimes in large-scale whole slide images (WSIs)? We propose a general-purpose local attention graph-based Transformer for MIL (LA-MIL), introducing an inductive bias by explicitly contextualizing instances in adaptive local regimes of arbitrary size. Additionally, an efficiently adapted loss function enables our approach to learn expressive WSI embeddings for the joint analysis of multiple biomarkers. We demonstrate that LA-MIL achieves state-of-the-art results in mutation prediction for gastrointestinal cancer, outperforming existing models on important biomarkers such as microsatellite instability for colorectal cancer. This suggests that local self-attention sufficiently models dependencies on par with global modules. Our implementation will be published.
S5CL: Unifying Fully-Supervised, Self-Supervised, and Semi-Supervised Learning Through Hierarchical Contrastive Learning
Mar 14, 2022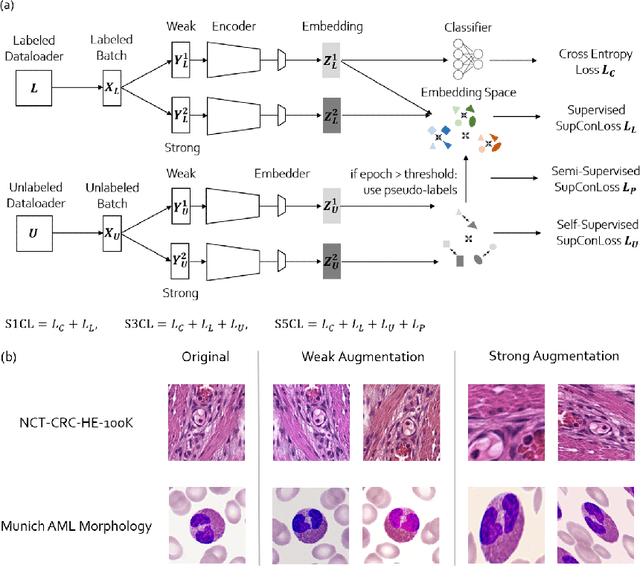
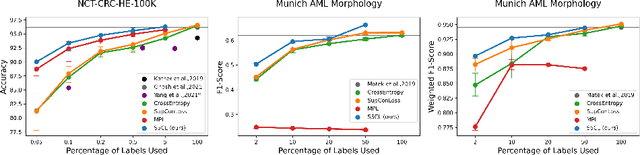
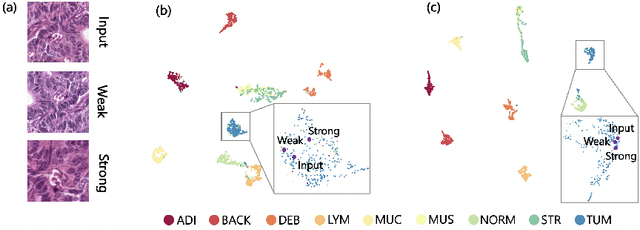
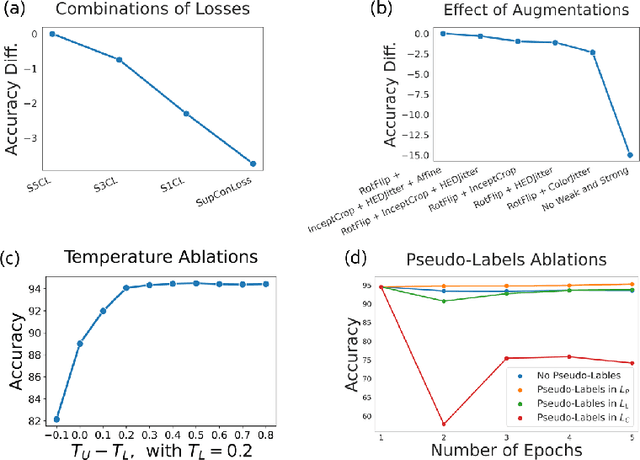
In computational pathology, we often face a scarcity of annotations and a large amount of unlabeled data. One method for dealing with this is semi-supervised learning which is commonly split into a self-supervised pretext task and a subsequent model fine-tuning. Here, we compress this two-stage training into one by introducing S5CL, a unified framework for fully-supervised, self-supervised, and semi-supervised learning. With three contrastive losses defined for labeled, unlabeled, and pseudo-labeled images, S5CL can learn feature representations that reflect the hierarchy of distance relationships: similar images and augmentations are embedded the closest, followed by different looking images of the same class, while images from separate classes have the largest distance. Moreover, S5CL allows us to flexibly combine these losses to adapt to different scenarios. Evaluations of our framework on two public histopathological datasets show strong improvements in the case of sparse labels: for a H&E-stained colorectal cancer dataset, the accuracy increases by up to 9% compared to supervised cross-entropy loss; for a highly imbalanced dataset of single white blood cells from leukemia patient blood smears, the F1-score increases by up to 6%.
Structure-Preserving Multi-Domain Stain Color Augmentation using Style-Transfer with Disentangled Representations
Jul 26, 2021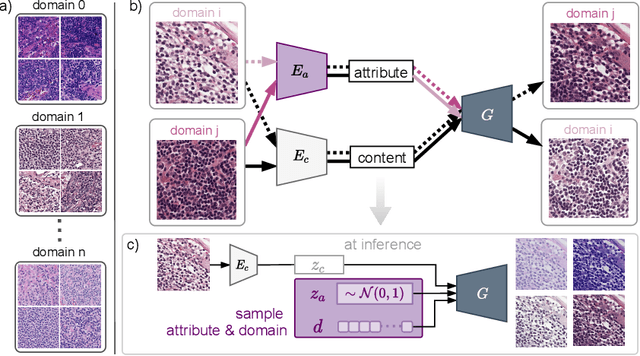
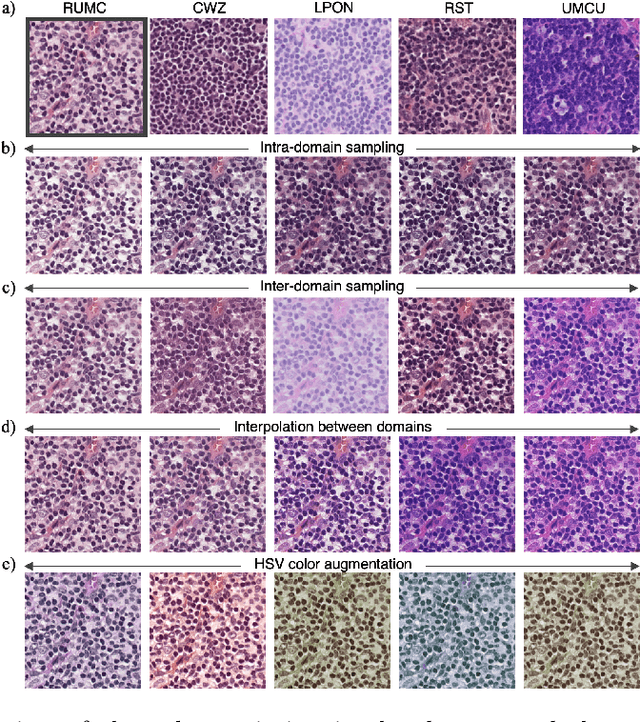
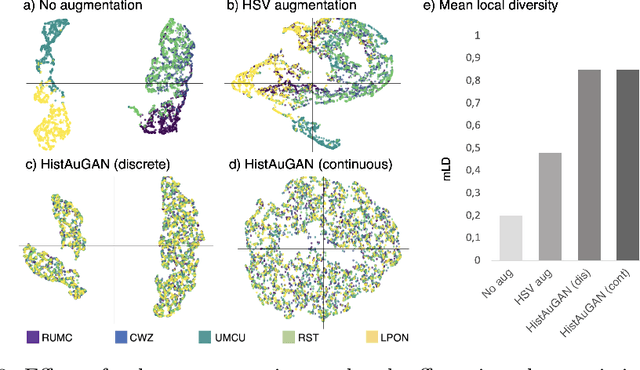
In digital pathology, different staining procedures and scanners cause substantial color variations in whole-slide images (WSIs), especially across different laboratories. These color shifts result in a poor generalization of deep learning-based methods from the training domain to external pathology data. To increase test performance, stain normalization techniques are used to reduce the variance between training and test domain. Alternatively, color augmentation can be applied during training leading to a more robust model without the extra step of color normalization at test time. We propose a novel color augmentation technique, HistAuGAN, that can simulate a wide variety of realistic histology stain colors, thus making neural networks stain-invariant when applied during training. Based on a generative adversarial network (GAN) for image-to-image translation, our model disentangles the content of the image, i.e., the morphological tissue structure, from the stain color attributes. It can be trained on multiple domains and, therefore, learns to cover different stain colors as well as other domain-specific variations introduced in the slide preparation and imaging process. We demonstrate that HistAuGAN outperforms conventional color augmentation techniques on a classification task on the publicly available dataset Camelyon17 and show that it is able to mitigate present batch effects.