 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS5CL: Unifying Fully-Supervised, Self-Supervised, and Semi-Supervised Learning Through Hierarchical Contrastive Learning
Paper and Code
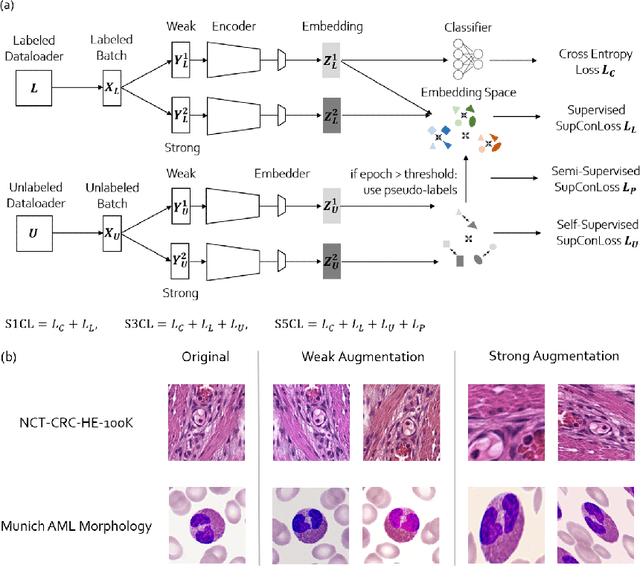
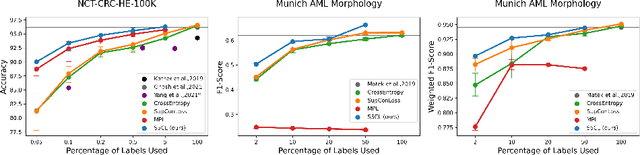
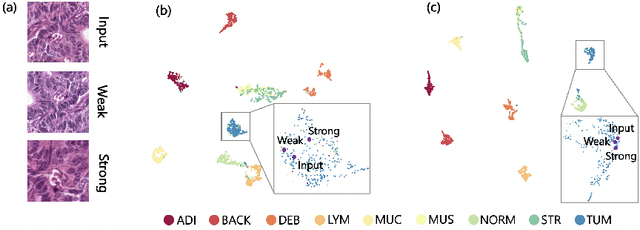
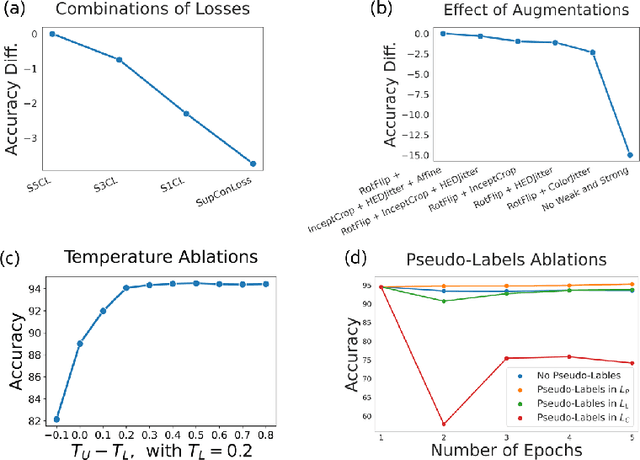
In computational pathology, we often face a scarcity of annotations and a large amount of unlabeled data. One method for dealing with this is semi-supervised learning which is commonly split into a self-supervised pretext task and a subsequent model fine-tuning. Here, we compress this two-stage training into one by introducing S5CL, a unified framework for fully-supervised, self-supervised, and semi-supervised learning. With three contrastive losses defined for labeled, unlabeled, and pseudo-labeled images, S5CL can learn feature representations that reflect the hierarchy of distance relationships: similar images and augmentations are embedded the closest, followed by different looking images of the same class, while images from separate classes have the largest distance. Moreover, S5CL allows us to flexibly combine these losses to adapt to different scenarios. Evaluations of our framework on two public histopathological datasets show strong improvements in the case of sparse labels: for a H&E-stained colorectal cancer dataset, the accuracy increases by up to 9% compared to supervised cross-entropy loss; for a highly imbalanced dataset of single white blood cells from leukemia patient blood smears, the F1-score increases by up to 6%.