 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeB-Cos Aligned Transformers Learn Human-Interpretable Features
Jan 18, 2024Vision Transformers (ViTs) and Swin Transformers (Swin) are currently state-of-the-art in computational pathology. However, domain experts are still reluctant to use these models due to their lack of interpretability. This is not surprising, as critical decisions need to be transparent and understandable. The most common approach to understanding transformers is to visualize their attention. However, attention maps of ViTs are often fragmented, leading to unsatisfactory explanations. Here, we introduce a novel architecture called the B-cos Vision Transformer (BvT) that is designed to be more interpretable. It replaces all linear transformations with the B-cos transform to promote weight-input alignment. In a blinded study, medical experts clearly ranked BvTs above ViTs, suggesting that our network is better at capturing biomedically relevant structures. This is also true for the B-cos Swin Transformer (Bwin). Compared to the Swin Transformer, it even improves the F1-score by up to 4.7% on two public datasets.
Pixel-Level Explanation of Multiple Instance Learning Models in Biomedical Single Cell Images
Mar 15, 2023

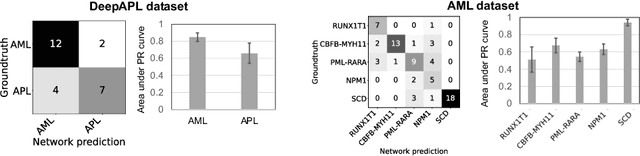
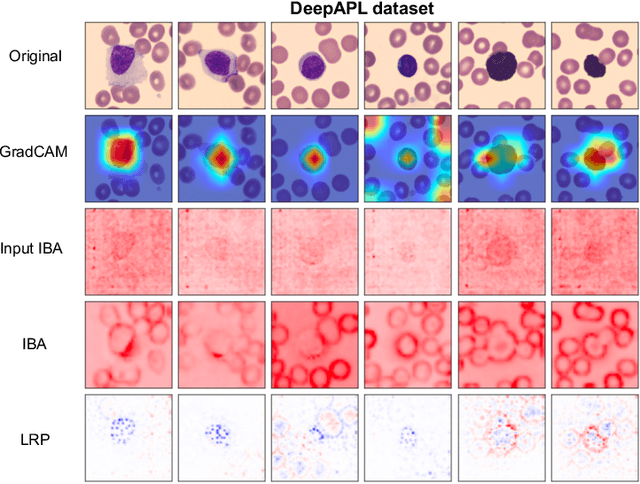
Explainability is a key requirement for computer-aided diagnosis systems in clinical decision-making. Multiple instance learning with attention pooling provides instance-level explainability, however for many clinical applications a deeper, pixel-level explanation is desirable, but missing so far. In this work, we investigate the use of four attribution methods to explain a multiple instance learning models: GradCAM, Layer-Wise Relevance Propagation (LRP), Information Bottleneck Attribution (IBA), and InputIBA. With this collection of methods, we can derive pixel-level explanations on for the task of diagnosing blood cancer from patients' blood smears. We study two datasets of acute myeloid leukemia with over 100 000 single cell images and observe how each attribution method performs on the multiple instance learning architecture focusing on different properties of the white blood single cells. Additionally, we compare attribution maps with the annotations of a medical expert to see how the model's decision-making differs from the human standard. Our study addresses the challenge of implementing pixel-level explainability in multiple instance learning models and provides insights for clinicians to better understand and trust decisions from computer-aided diagnosis systems.
Unsupervised Cross-Domain Feature Extraction for Single Blood Cell Image Classification
Jul 01, 2022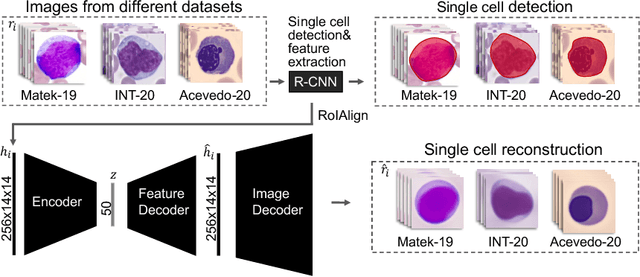
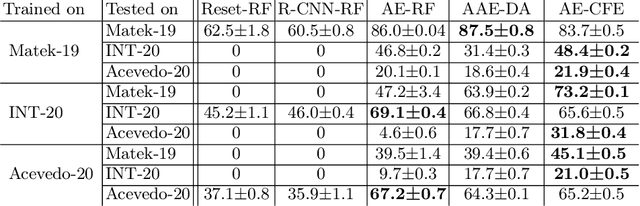
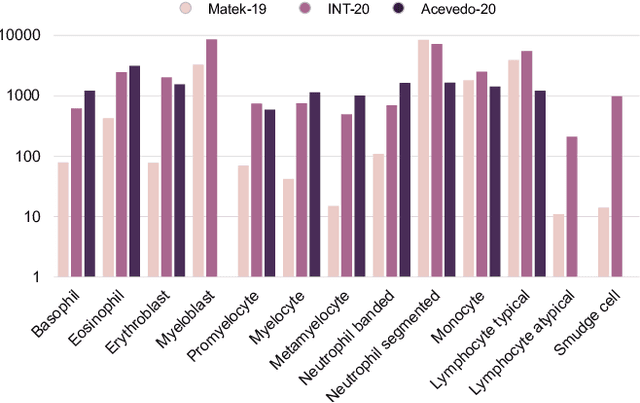
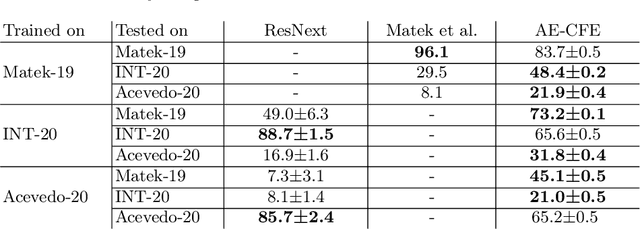
Diagnosing hematological malignancies requires identification and classification of white blood cells in peripheral blood smears. Domain shifts caused by different lab procedures, staining, illumination, and microscope settings hamper the re-usability of recently developed machine learning methods on data collected from different sites. Here, we propose a cross-domain adapted autoencoder to extract features in an unsupervised manner on three different datasets of single white blood cells scanned from peripheral blood smears. The autoencoder is based on an R-CNN architecture allowing it to focus on the relevant white blood cell and eliminate artifacts in the image. To evaluate the quality of the extracted features we use a simple random forest to classify single cells. We show that thanks to the rich features extracted by the autoencoder trained on only one of the datasets, the random forest classifier performs satisfactorily on the unseen datasets, and outperforms published oracle networks in the cross-domain task. Our results suggest the possibility of employing this unsupervised approach in more complicated diagnosis and prognosis tasks without the need to add expensive expert labels to unseen data.