 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Cellular Automata for Weakly Supervised Segmentation of White Blood Cells
Aug 17, 2025The detection and segmentation of white blood cells in blood smear images is a key step in medical diagnostics, supporting various downstream tasks such as automated blood cell counting, morphological analysis, cell classification, and disease diagnosis and monitoring. Training robust and accurate models requires large amounts of labeled data, which is both time-consuming and expensive to acquire. In this work, we propose a novel approach for weakly supervised segmentation using neural cellular automata (NCA-WSS). By leveraging the feature maps generated by NCA during classification, we can extract segmentation masks without the need for retraining with segmentation labels. We evaluate our method on three white blood cell microscopy datasets and demonstrate that NCA-WSS significantly outperforms existing weakly supervised approaches. Our work illustrates the potential of NCA for both classification and segmentation in a weakly supervised framework, providing a scalable and efficient solution for medical image analysis.
Multimodal Analysis of White Blood Cell Differentiation in Acute Myeloid Leukemia Patients using a β-Variational Autoencoder
Aug 13, 2024Biomedical imaging and RNA sequencing with single-cell resolution improves our understanding of white blood cell diseases like leukemia. By combining morphological and transcriptomic data, we can gain insights into cellular functions and trajectoriess involved in blood cell differentiation. However, existing methodologies struggle with integrating morphological and transcriptomic data, leaving a significant research gap in comprehensively understanding the dynamics of cell differentiation. Here, we introduce an unsupervised method that explores and reconstructs these two modalities and uncovers the relationship between different subtypes of white blood cells from human peripheral blood smears in terms of morphology and their corresponding transcriptome. Our method is based on a beta-variational autoencoder (\beta-VAE) with a customized loss function, incorporating a R-CNN architecture to distinguish single-cell from background and to minimize any interference from artifacts. This implementation of \beta-VAE shows good reconstruction capability along with continuous latent embeddings, while maintaining clear differentiation between single-cell classes. Our novel approach is especially helpful to uncover the correlation of two latent features in complex biological processes such as formation of granules in the cell (granulopoiesis) with gene expression patterns. It thus provides a unique tool to improve the understanding of white blood cell maturation for biomedicine and diagnostics.
A Continual Learning Approach for Cross-Domain White Blood Cell Classification
Aug 24, 2023



Accurate classification of white blood cells in peripheral blood is essential for diagnosing hematological diseases. Due to constantly evolving clinical settings, data sources, and disease classifications, it is necessary to update machine learning classification models regularly for practical real-world use. Such models significantly benefit from sequentially learning from incoming data streams without forgetting previously acquired knowledge. However, models can suffer from catastrophic forgetting, causing a drop in performance on previous tasks when fine-tuned on new data. Here, we propose a rehearsal-based continual learning approach for class incremental and domain incremental scenarios in white blood cell classification. To choose representative samples from previous tasks, we employ exemplar set selection based on the model's predictions. This involves selecting the most confident samples and the most challenging samples identified through uncertainty estimation of the model. We thoroughly evaluated our proposed approach on three white blood cell classification datasets that differ in color, resolution, and class composition, including scenarios where new domains or new classes are introduced to the model with every task. We also test a long class incremental experiment with both new domains and new classes. Our results demonstrate that our approach outperforms established baselines in continual learning, including existing iCaRL and EWC methods for classifying white blood cells in cross-domain environments.
Unsupervised Cross-Domain Feature Extraction for Single Blood Cell Image Classification
Jul 01, 2022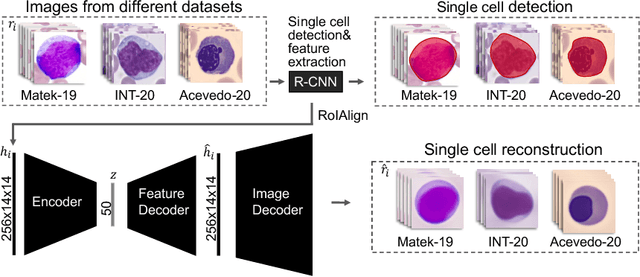
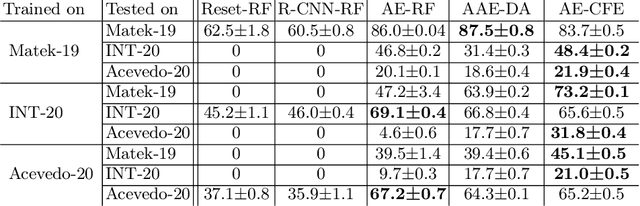
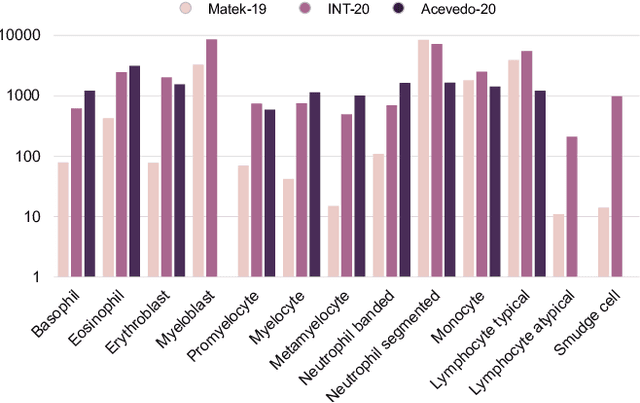
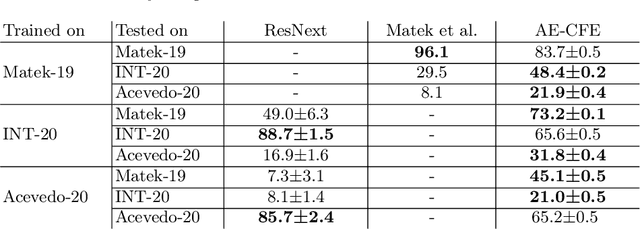
Diagnosing hematological malignancies requires identification and classification of white blood cells in peripheral blood smears. Domain shifts caused by different lab procedures, staining, illumination, and microscope settings hamper the re-usability of recently developed machine learning methods on data collected from different sites. Here, we propose a cross-domain adapted autoencoder to extract features in an unsupervised manner on three different datasets of single white blood cells scanned from peripheral blood smears. The autoencoder is based on an R-CNN architecture allowing it to focus on the relevant white blood cell and eliminate artifacts in the image. To evaluate the quality of the extracted features we use a simple random forest to classify single cells. We show that thanks to the rich features extracted by the autoencoder trained on only one of the datasets, the random forest classifier performs satisfactorily on the unseen datasets, and outperforms published oracle networks in the cross-domain task. Our results suggest the possibility of employing this unsupervised approach in more complicated diagnosis and prognosis tasks without the need to add expensive expert labels to unseen data.