 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Signboard-Oriented Visual Question Answering: ViSignVQA Dataset, Method and Benchmark
Dec 22, 2025Understanding signboard text in natural scenes is essential for real-world applications of Visual Question Answering (VQA), yet remains underexplored, particularly in low-resource languages. We introduce ViSignVQA, the first large-scale Vietnamese dataset designed for signboard-oriented VQA, which comprises 10,762 images and 25,573 question-answer pairs. The dataset captures the diverse linguistic, cultural, and visual characteristics of Vietnamese signboards, including bilingual text, informal phrasing, and visual elements such as color and layout. To benchmark this task, we adapted state-of-the-art VQA models (e.g., BLIP-2, LaTr, PreSTU, and SaL) by integrating a Vietnamese OCR model (SwinTextSpotter) and a Vietnamese pretrained language model (ViT5). The experimental results highlight the significant role of the OCR-enhanced context, with F1-score improvements of up to 209% when the OCR text is appended to questions. Additionally, we propose a multi-agent VQA framework combining perception and reasoning agents with GPT-4, achieving 75.98% accuracy via majority voting. Our study presents the first large-scale multimodal dataset for Vietnamese signboard understanding. This underscores the importance of domain-specific resources in enhancing text-based VQA for low-resource languages. ViSignVQA serves as a benchmark capturing real-world scene text characteristics and supporting the development and evaluation of OCR-integrated VQA models in Vietnamese.
Evaluating Precise Geolocation Inference Capabilities of Vision Language Models
Feb 20, 2025



The prevalence of Vision-Language Models (VLMs) raises important questions about privacy in an era where visual information is increasingly available. While foundation VLMs demonstrate broad knowledge and learned capabilities, we specifically investigate their ability to infer geographic location from previously unseen image data. This paper introduces a benchmark dataset collected from Google Street View that represents its global distribution of coverage. Foundation models are evaluated on single-image geolocation inference, with many achieving median distance errors of <300 km. We further evaluate VLM "agents" with access to supplemental tools, observing up to a 30.6% decrease in distance error. Our findings establish that modern foundation VLMs can act as powerful image geolocation tools, without being specifically trained for this task. When coupled with increasing accessibility of these models, our findings have greater implications for online privacy. We discuss these risks, as well as future work in this area.
"Global is Good, Local is Bad?": Understanding Brand Bias in LLMs
Jun 20, 2024
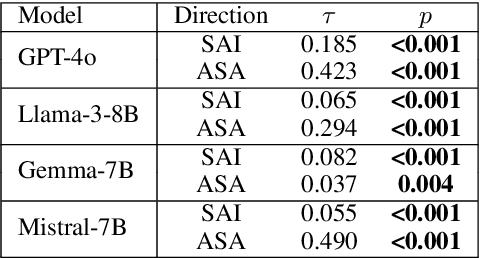
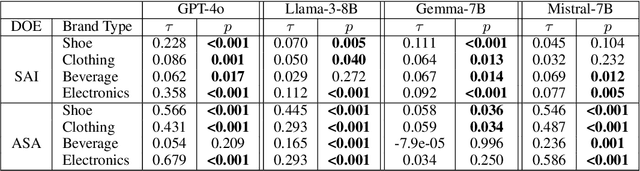
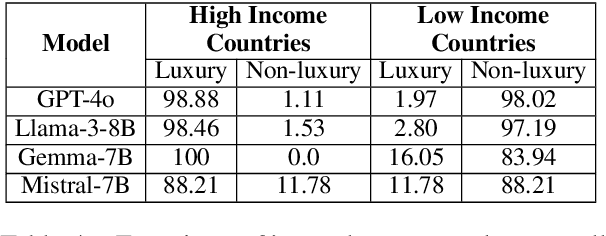
Many recent studies have investigated social biases in LLMs but brand bias has received little attention. This research examines the biases exhibited by LLMs towards different brands, a significant concern given the widespread use of LLMs in affected use cases such as product recommendation and market analysis. Biased models may perpetuate societal inequalities, unfairly favoring established global brands while marginalizing local ones. Using a curated dataset across four brand categories, we probe the behavior of LLMs in this space. We find a consistent pattern of bias in this space -- both in terms of disproportionately associating global brands with positive attributes and disproportionately recommending luxury gifts for individuals in high-income countries. We also find LLMs are subject to country-of-origin effects which may boost local brand preference in LLM outputs in specific contexts.
The SaTML '24 CNN Interpretability Competition: New Innovations for Concept-Level Interpretability
Apr 03, 2024Interpretability techniques are valuable for helping humans understand and oversee AI systems. The SaTML 2024 CNN Interpretability Competition solicited novel methods for studying convolutional neural networks (CNNs) at the ImageNet scale. The objective of the competition was to help human crowd-workers identify trojans in CNNs. This report showcases the methods and results of four featured competition entries. It remains challenging to help humans reliably diagnose trojans via interpretability tools. However, the competition's entries have contributed new techniques and set a new record on the benchmark from Casper et al., 2023.