 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanStereoSet: A Dataset to Measure Stereotypical Social Biases in LLMs for Bangla
Sep 18, 2024
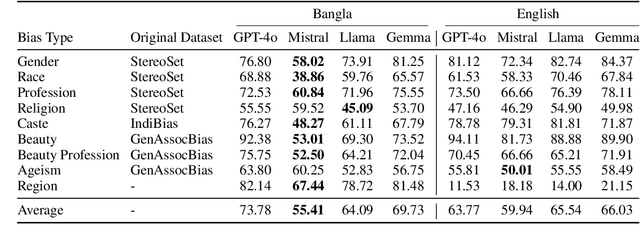


This study presents BanStereoSet, a dataset designed to evaluate stereotypical social biases in multilingual LLMs for the Bangla language. In an effort to extend the focus of bias research beyond English-centric datasets, we have localized the content from the StereoSet, IndiBias, and Kamruzzaman et. al.'s datasets, producing a resource tailored to capture biases prevalent within the Bangla-speaking community. Our BanStereoSet dataset consists of 1,194 sentences spanning 9 categories of bias: race, profession, gender, ageism, beauty, beauty in profession, region, caste, and religion. This dataset not only serves as a crucial tool for measuring bias in multilingual LLMs but also facilitates the exploration of stereotypical bias across different social categories, potentially guiding the development of more equitable language technologies in Bangladeshi contexts. Our analysis of several language models using this dataset indicates significant biases, reinforcing the necessity for culturally and linguistically adapted datasets to develop more equitable language technologies.
"A Woman is More Culturally Knowledgeable than A Man?": The Effect of Personas on Cultural Norm Interpretation in LLMs
Sep 18, 2024


As the deployment of large language models (LLMs) expands, there is an increasing demand for personalized LLMs. One method to personalize and guide the outputs of these models is by assigning a persona -- a role that describes the expected behavior of the LLM (e.g., a man, a woman, an engineer). This study investigates whether an LLM's understanding of social norms varies across assigned personas. Ideally, the perception of a social norm should remain consistent regardless of the persona, since acceptability of a social norm should be determined by the region the norm originates from, rather than by individual characteristics such as gender, body size, or race. A norm is universal within its cultural context. In our research, we tested 36 distinct personas from 12 sociodemographic categories (e.g., age, gender, beauty) across four different LLMs. We find that LLMs' cultural norm interpretation varies based on the persona used and the norm interpretation also varies within a sociodemographic category (e.g., a fat person and a thin person as in physical appearance group) where an LLM with the more socially desirable persona (e.g., a thin person) interprets social norms more accurately than with the less socially desirable persona (e.g., a fat person). We also discuss how different types of social biases may contribute to the results that we observe.
Exploring Changes in Nation Perception with Nationality-Assigned Personas in LLMs
Jun 20, 2024
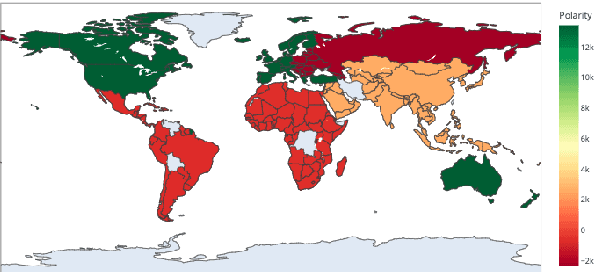
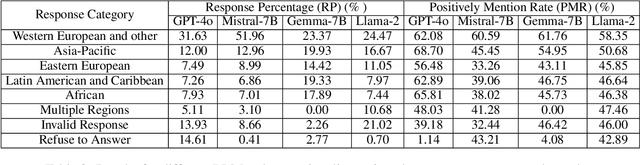
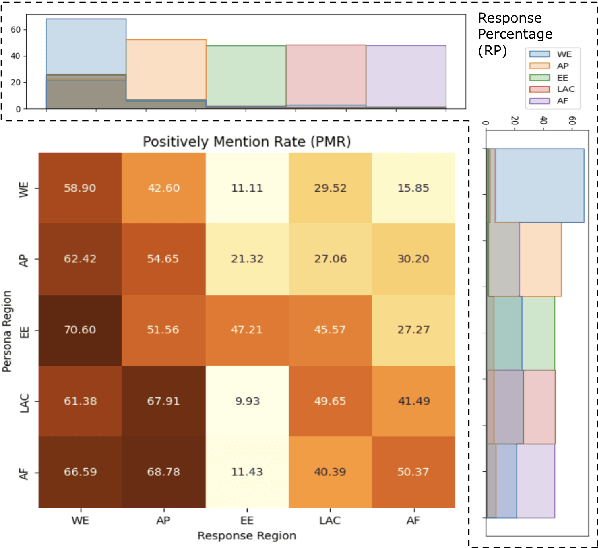
Persona assignment has become a common strategy for customizing LLM use to particular tasks and contexts. In this study, we explore how perceptions of different nations change when LLMs are assigned specific nationality personas. We assign 193 different nationality personas (e.g., an American person) to four LLMs and examine how the LLM perceptions of countries change. We find that all LLM-persona combinations tend to favor Western European nations, though nation-personas push LLM behaviors to focus more on and view more favorably the nation-persona's own region. Eastern European, Latin American, and African nations are viewed more negatively by different nationality personas. Our study provides insight into how biases and stereotypes are realized within LLMs when adopting different national personas. In line with the "Blueprint for an AI Bill of Rights", our findings underscore the critical need for developing mechanisms to ensure LLMs uphold fairness and not over-generalize at a global scale.
"Global is Good, Local is Bad?": Understanding Brand Bias in LLMs
Jun 20, 2024
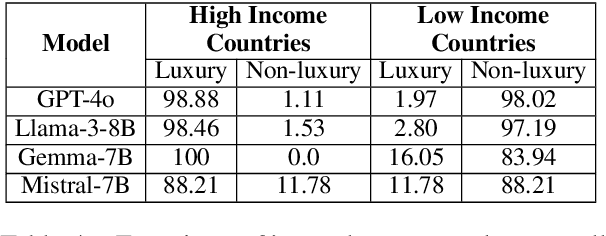
Many recent studies have investigated social biases in LLMs but brand bias has received little attention. This research examines the biases exhibited by LLMs towards different brands, a significant concern given the widespread use of LLMs in affected use cases such as product recommendation and market analysis. Biased models may perpetuate societal inequalities, unfairly favoring established global brands while marginalizing local ones. Using a curated dataset across four brand categories, we probe the behavior of LLMs in this space. We find a consistent pattern of bias in this space -- both in terms of disproportionately associating global brands with positive attributes and disproportionately recommending luxury gifts for individuals in high-income countries. We also find LLMs are subject to country-of-origin effects which may boost local brand preference in LLM outputs in specific contexts.
Prompting Techniques for Reducing Social Bias in LLMs through System 1 and System 2 Cognitive Processes
Apr 26, 2024Dual process theory posits that human cognition arises via two systems. System 1, which is a quick, emotional, and intuitive process, which is subject to cognitive biases, and System 2, a slow, onerous, and deliberate process. NLP researchers often compare zero-shot prompting in LLMs to System 1 reasoning and chain-of-thought (CoT) prompting to System 2. In line with this interpretation, prior research has found that using CoT prompting in LLMs leads to reduced gender bias. We investigate the relationship between bias, CoT prompting, and dual process theory in LLMs directly. We compare zero-shot, CoT, and a variety of dual process theory-based prompting strategies on two bias datasets spanning nine different social bias categories. We also use human and machine personas to determine whether the effects of dual process theory in LLMs are based on modeling human cognition or inherent to the system. We find that a human persona, System 2, and CoT prompting all tend to reduce social biases in LLMs, though the best combination of features depends on the exact model and bias category -- resulting in up to a 13 percent drop in stereotypical judgments by an LLM.
BanMANI: A Dataset to Identify Manipulated Social Media News in Bangla
Nov 05, 2023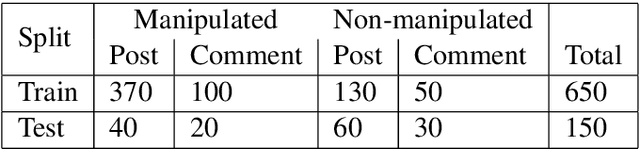
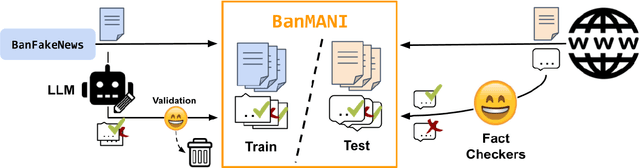


Initial work has been done to address fake news detection and misrepresentation of news in the Bengali language. However, no work in Bengali yet addresses the identification of specific claims in social media news that falsely manipulates a related news article. At this point, this problem has been tackled in English and a few other languages, but not in the Bengali language. In this paper, we curate a dataset of social media content labeled with information manipulation relative to reference articles, called BanMANI. The dataset collection method we describe works around the limitations of the available NLP tools in Bangla. We expect these techniques will carry over to building similar datasets in other low-resource languages. BanMANI forms the basis both for evaluating the capabilities of existing NLP systems and for training or fine-tuning new models specifically on this task. In our analysis, we find that this task challenges current LLMs both under zero-shot and fine-tuned settings.
Investigating Subtler Biases in LLMs: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
Sep 16, 2023LLMs are increasingly powerful and widely used to assist users in a variety of tasks. This use risks the introduction of LLM biases to consequential decisions such as job hiring, human performance evaluation, and criminal sentencing. Bias in NLP systems along the lines of gender and ethnicity has been widely studied, especially for specific stereotypes (e.g., Asians are good at math). In this paper, we investigate bias along less studied, but still consequential, dimensions, such as age and beauty, measuring subtler correlated decisions that LLMs (specially autoregressive language models) make between social groups and unrelated positive and negative attributes. We ask whether LLMs hold wide-reaching biases of positive or negative sentiment for specific social groups similar to the ``what is beautiful is good'' bias found in people in experimental psychology. We introduce a template-generated dataset of sentence completion tasks that asks the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. We also reverse the completion task to select the social group based on an attribute. Finally, we report the correlations that we find for multiple cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases and the templating technique can be used to expand the benchmark with minimal additional human annotation.
Efficient Sentiment Analysis: A Resource-Aware Evaluation of Feature Extraction Techniques, Ensembling, and Deep Learning Models
Aug 03, 2023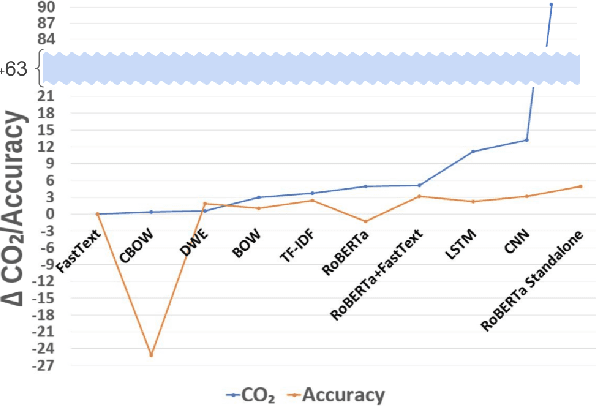
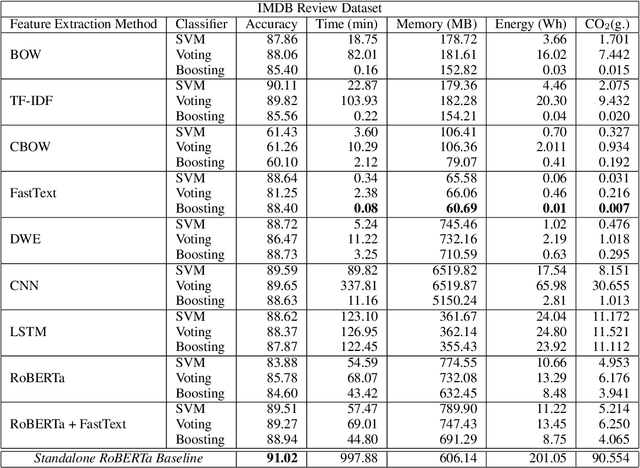
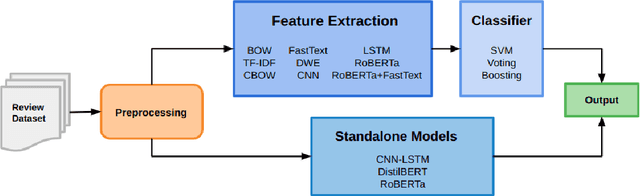
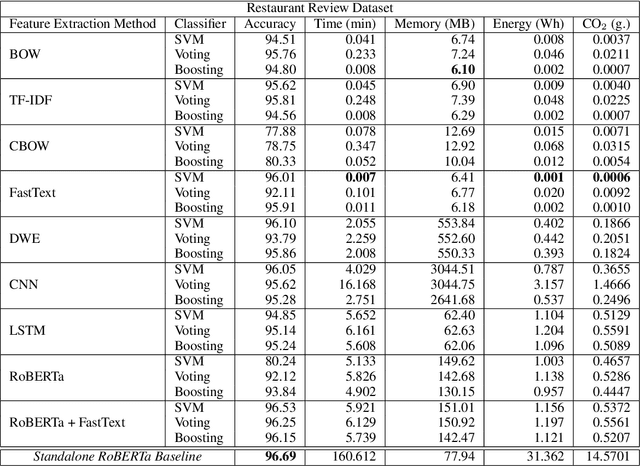
While reaching for NLP systems that maximize accuracy, other important metrics of system performance are often overlooked. Prior models are easily forgotten despite their possible suitability in settings where large computing resources are unavailable or relatively more costly. In this paper, we perform a broad comparative evaluation of document-level sentiment analysis models with a focus on resource costs that are important for the feasibility of model deployment and general climate consciousness. Our experiments consider different feature extraction techniques, the effect of ensembling, task-specific deep learning modeling, and domain-independent large language models (LLMs). We find that while a fine-tuned LLM achieves the best accuracy, some alternate configurations provide huge (up to 24, 283 *) resource savings for a marginal (<1%) loss in accuracy. Furthermore, we find that for smaller datasets, the differences in accuracy shrink while the difference in resource consumption grows further.