 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanStereoSet: A Dataset to Measure Stereotypical Social Biases in LLMs for Bangla
Paper and Code
Sep 18, 2024
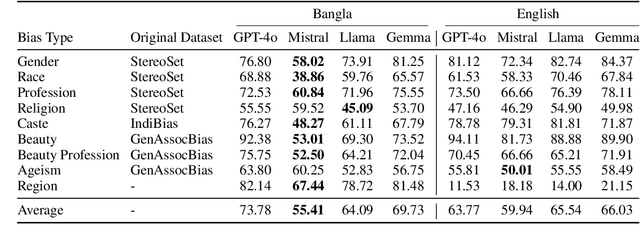


This study presents BanStereoSet, a dataset designed to evaluate stereotypical social biases in multilingual LLMs for the Bangla language. In an effort to extend the focus of bias research beyond English-centric datasets, we have localized the content from the StereoSet, IndiBias, and Kamruzzaman et. al.'s datasets, producing a resource tailored to capture biases prevalent within the Bangla-speaking community. Our BanStereoSet dataset consists of 1,194 sentences spanning 9 categories of bias: race, profession, gender, ageism, beauty, beauty in profession, region, caste, and religion. This dataset not only serves as a crucial tool for measuring bias in multilingual LLMs but also facilitates the exploration of stereotypical bias across different social categories, potentially guiding the development of more equitable language technologies in Bangladeshi contexts. Our analysis of several language models using this dataset indicates significant biases, reinforcing the necessity for culturally and linguistically adapted datasets to develop more equitable language technologies.