 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Detection with a Context-Aware Encoder and LoRA for Improved Performance on Long-Tailed Classes
Jan 17, 2026The current state of event detection research has two notable re-occurring limitations that we investigate in this study. First, the unidirectional nature of decoder-only LLMs presents a fundamental architectural bottleneck for natural language understanding tasks that depend on rich, bidirectional context. Second, we confront the conventional reliance on Micro-F1 scores in event detection literature, which systematically inflates performance by favoring majority classes. Instead, we focus on Macro-F1 as a more representative measure of a model's ability across the long-tail of event types. Our experiments demonstrate that models enhanced with sentence context achieve superior performance over canonical decoder-only baselines. Using Low-Rank Adaptation (LoRA) during finetuning provides a substantial boost in Macro-F1 scores in particular, especially for the decoder-only models, showing that LoRA can be an effective tool to enhance LLMs' performance on long-tailed event classes.
BanStereoSet: A Dataset to Measure Stereotypical Social Biases in LLMs for Bangla
Sep 18, 2024
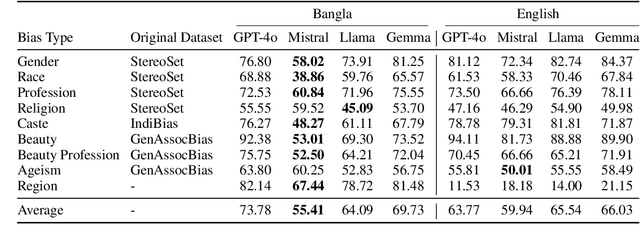


This study presents BanStereoSet, a dataset designed to evaluate stereotypical social biases in multilingual LLMs for the Bangla language. In an effort to extend the focus of bias research beyond English-centric datasets, we have localized the content from the StereoSet, IndiBias, and Kamruzzaman et. al.'s datasets, producing a resource tailored to capture biases prevalent within the Bangla-speaking community. Our BanStereoSet dataset consists of 1,194 sentences spanning 9 categories of bias: race, profession, gender, ageism, beauty, beauty in profession, region, caste, and religion. This dataset not only serves as a crucial tool for measuring bias in multilingual LLMs but also facilitates the exploration of stereotypical bias across different social categories, potentially guiding the development of more equitable language technologies in Bangladeshi contexts. Our analysis of several language models using this dataset indicates significant biases, reinforcing the necessity for culturally and linguistically adapted datasets to develop more equitable language technologies.