 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanStereoSet: A Dataset to Measure Stereotypical Social Biases in LLMs for Bangla
Sep 18, 2024
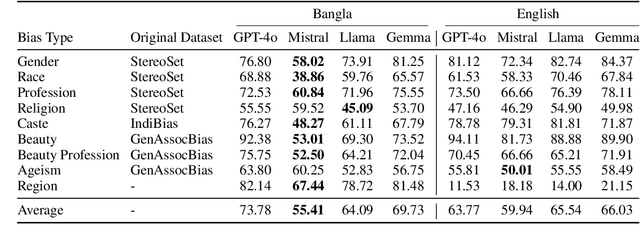


This study presents BanStereoSet, a dataset designed to evaluate stereotypical social biases in multilingual LLMs for the Bangla language. In an effort to extend the focus of bias research beyond English-centric datasets, we have localized the content from the StereoSet, IndiBias, and Kamruzzaman et. al.'s datasets, producing a resource tailored to capture biases prevalent within the Bangla-speaking community. Our BanStereoSet dataset consists of 1,194 sentences spanning 9 categories of bias: race, profession, gender, ageism, beauty, beauty in profession, region, caste, and religion. This dataset not only serves as a crucial tool for measuring bias in multilingual LLMs but also facilitates the exploration of stereotypical bias across different social categories, potentially guiding the development of more equitable language technologies in Bangladeshi contexts. Our analysis of several language models using this dataset indicates significant biases, reinforcing the necessity for culturally and linguistically adapted datasets to develop more equitable language technologies.
CovidExpert: A Triplet Siamese Neural Network framework for the detection of COVID-19
Feb 17, 2023Patients with the COVID-19 infection may have pneumonia-like symptoms as well as respiratory problems which may harm the lungs. From medical images, coronavirus illness may be accurately identified and predicted using a variety of machine learning methods. Most of the published machine learning methods may need extensive hyperparameter adjustment and are unsuitable for small datasets. By leveraging the data in a comparatively small dataset, few-shot learning algorithms aim to reduce the requirement of large datasets. This inspired us to develop a few-shot learning model for early detection of COVID-19 to reduce the post-effect of this dangerous disease. The proposed architecture combines few-shot learning with an ensemble of pre-trained convolutional neural networks to extract feature vectors from CT scan images for similarity learning. The proposed Triplet Siamese Network as the few-shot learning model classified CT scan images into Normal, COVID-19, and Community-Acquired Pneumonia. The suggested model achieved an overall accuracy of 98.719%, a specificity of 99.36%, a sensitivity of 98.72%, and a ROC score of 99.9% with only 200 CT scans per category for training data.