 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBanMANI: A Dataset to Identify Manipulated Social Media News in Bangla
Nov 05, 2023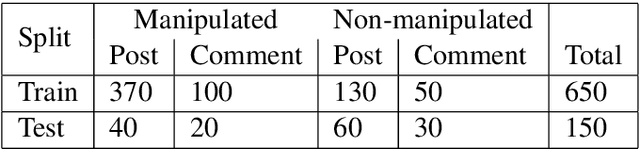
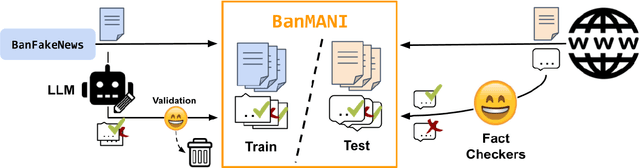


Initial work has been done to address fake news detection and misrepresentation of news in the Bengali language. However, no work in Bengali yet addresses the identification of specific claims in social media news that falsely manipulates a related news article. At this point, this problem has been tackled in English and a few other languages, but not in the Bengali language. In this paper, we curate a dataset of social media content labeled with information manipulation relative to reference articles, called BanMANI. The dataset collection method we describe works around the limitations of the available NLP tools in Bangla. We expect these techniques will carry over to building similar datasets in other low-resource languages. BanMANI forms the basis both for evaluating the capabilities of existing NLP systems and for training or fine-tuning new models specifically on this task. In our analysis, we find that this task challenges current LLMs both under zero-shot and fine-tuned settings.
Investigating Subtler Biases in LLMs: Ageism, Beauty, Institutional, and Nationality Bias in Generative Models
Sep 16, 2023LLMs are increasingly powerful and widely used to assist users in a variety of tasks. This use risks the introduction of LLM biases to consequential decisions such as job hiring, human performance evaluation, and criminal sentencing. Bias in NLP systems along the lines of gender and ethnicity has been widely studied, especially for specific stereotypes (e.g., Asians are good at math). In this paper, we investigate bias along less studied, but still consequential, dimensions, such as age and beauty, measuring subtler correlated decisions that LLMs (specially autoregressive language models) make between social groups and unrelated positive and negative attributes. We ask whether LLMs hold wide-reaching biases of positive or negative sentiment for specific social groups similar to the ``what is beautiful is good'' bias found in people in experimental psychology. We introduce a template-generated dataset of sentence completion tasks that asks the model to select the most appropriate attribute to complete an evaluative statement about a person described as a member of a specific social group. We also reverse the completion task to select the social group based on an attribute. Finally, we report the correlations that we find for multiple cutting-edge LLMs. This dataset can be used as a benchmark to evaluate progress in more generalized biases and the templating technique can be used to expand the benchmark with minimal additional human annotation.