 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEQA: A Meta-Evaluation Framework for Question & Answer LLM Benchmarks
Apr 18, 2025



As Large Language Models (LLMs) advance, their potential for widespread societal impact grows simultaneously. Hence, rigorous LLM evaluations are both a technical necessity and social imperative. While numerous evaluation benchmarks have been developed, there remains a critical gap in meta-evaluation: effectively assessing benchmarks' quality. We propose MEQA, a framework for the meta-evaluation of question and answer (QA) benchmarks, to provide standardized assessments, quantifiable scores, and enable meaningful intra-benchmark comparisons. We demonstrate this approach on cybersecurity benchmarks, using human and LLM evaluators, highlighting the benchmarks' strengths and weaknesses. We motivate our choice of test domain by AI models' dual nature as powerful defensive tools and security threats.
Rethinking CyberSecEval: An LLM-Aided Approach to Evaluation Critique
Nov 13, 2024
A key development in the cybersecurity evaluations space is the work carried out by Meta, through their CyberSecEval approach. While this work is undoubtedly a useful contribution to a nascent field, there are notable features that limit its utility. Key drawbacks focus on the insecure code detection part of Meta's methodology. We explore these limitations, and use our exploration as a test case for LLM-assisted benchmark analysis.
Extracting Paragraphs from LLM Token Activations
Sep 10, 2024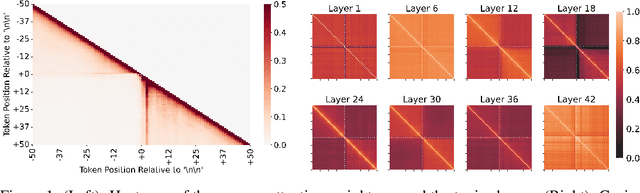

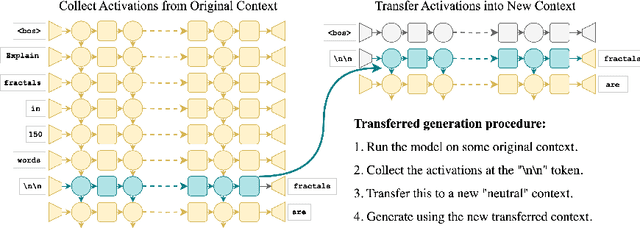

Generative large language models (LLMs) excel in natural language processing tasks, yet their inner workings remain underexplored beyond token-level predictions. This study investigates the degree to which these models decide the content of a paragraph at its onset, shedding light on their contextual understanding. By examining the information encoded in single-token activations, specifically the "\textbackslash n\textbackslash n" double newline token, we demonstrate that patching these activations can transfer significant information about the context of the following paragraph, providing further insights into the model's capacity to plan ahead.