 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Paragraphs from LLM Token Activations
Sep 10, 2024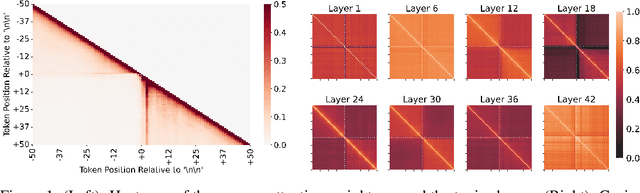

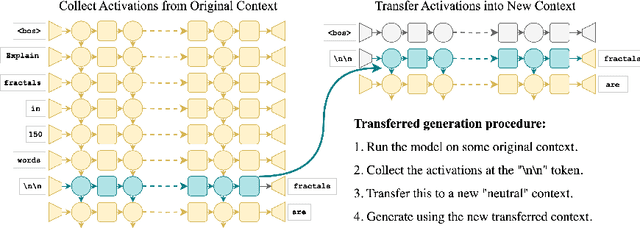

Generative large language models (LLMs) excel in natural language processing tasks, yet their inner workings remain underexplored beyond token-level predictions. This study investigates the degree to which these models decide the content of a paragraph at its onset, shedding light on their contextual understanding. By examining the information encoded in single-token activations, specifically the "\textbackslash n\textbackslash n" double newline token, we demonstrate that patching these activations can transfer significant information about the context of the following paragraph, providing further insights into the model's capacity to plan ahead.
Modularity in Transformers: Investigating Neuron Separability & Specialization
Aug 30, 2024Transformer models are increasingly prevalent in various applications, yet our understanding of their internal workings remains limited. This paper investigates the modularity and task specialization of neurons within transformer architectures, focusing on both vision (ViT) and language (Mistral 7B) models. Using a combination of selective pruning and MoEfication clustering techniques, we analyze the overlap and specialization of neurons across different tasks and data subsets. Our findings reveal evidence of task-specific neuron clusters, with varying degrees of overlap between related tasks. We observe that neuron importance patterns persist to some extent even in randomly initialized models, suggesting an inherent structure that training refines. Additionally, we find that neuron clusters identified through MoEfication correspond more strongly to task-specific neurons in earlier and later layers of the models. This work contributes to a more nuanced understanding of transformer internals and offers insights into potential avenues for improving model interpretability and efficiency.
Investigating Neuron Ablation in Attention Heads: The Case for Peak Activation Centering
Aug 30, 2024The use of transformer-based models is growing rapidly throughout society. With this growth, it is important to understand how they work, and in particular, how the attention mechanisms represent concepts. Though there are many interpretability methods, many look at models through their neuronal activations, which are poorly understood. We describe different lenses through which to view neuron activations, and investigate the effectiveness in language models and vision transformers through various methods of neural ablation: zero ablation, mean ablation, activation resampling, and a novel approach we term 'peak ablation'. Through experimental analysis, we find that in different regimes and models, each method can offer the lowest degradation of model performance compared to other methods, with resampling usually causing the most significant performance deterioration. We make our code available at https://github.com/nickypro/investigating-ablation.
Dissecting Language Models: Machine Unlearning via Selective Pruning
Mar 02, 2024
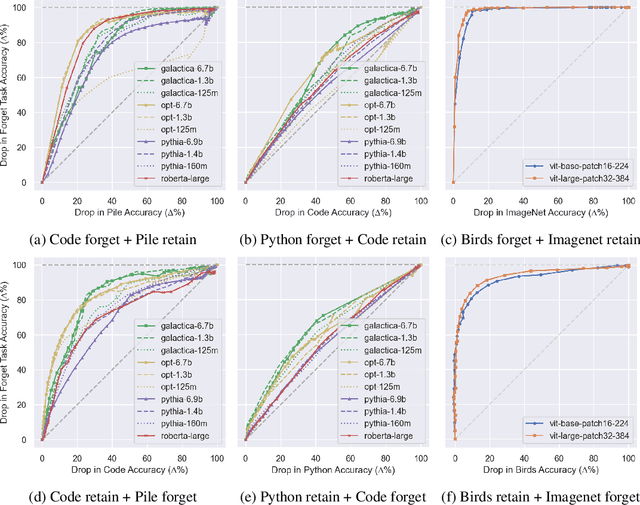

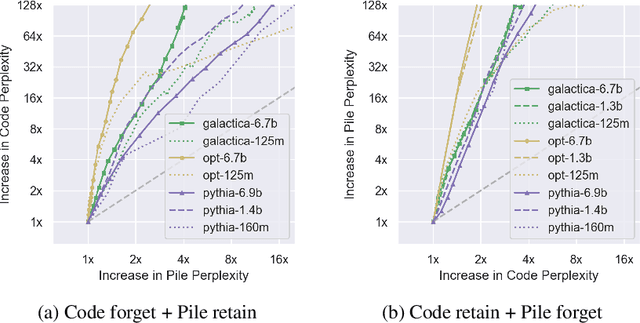
Understanding and shaping the behaviour of Large Language Models (LLMs) is increasingly important as applications become more powerful and more frequently adopted. This paper introduces a machine unlearning method specifically designed for LLMs. We introduce a selective pruning method for LLMs that removes neurons based on their relative importance on a targeted capability compared to overall network performance. This approach is a compute- and data-efficient method for identifying and removing neurons that enable specific behaviours. Our findings reveal that both feed-forward and attention neurons in LLMs are specialized; that is, for specific tasks, certain neurons are more crucial than others.