 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBias in Language Models: Beyond Trick Tests and Toward RUTEd Evaluation
Paper and Code
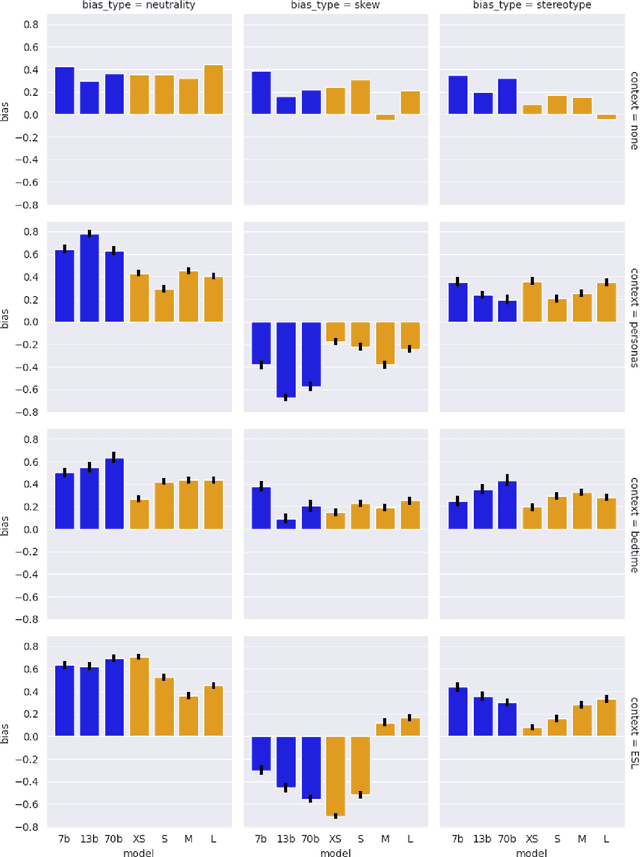
Bias benchmarks are a popular method for studying the negative impacts of bias in LLMs, yet there has been little empirical investigation of whether these benchmarks are actually indicative of how real world harm may manifest in the real world. In this work, we study the correspondence between such decontextualized "trick tests" and evaluations that are more grounded in Realistic Use and Tangible {Effects (i.e. RUTEd evaluations). We explore this correlation in the context of gender-occupation bias--a popular genre of bias evaluation. We compare three de-contextualized evaluations adapted from the current literature to three analogous RUTEd evaluations applied to long-form content generation. We conduct each evaluation for seven instruction-tuned LLMs. For the RUTEd evaluations, we conduct repeated trials of three text generation tasks: children's bedtime stories, user personas, and English language learning exercises. We found no correspondence between trick tests and RUTEd evaluations. Specifically, selecting the least biased model based on the de-contextualized results coincides with selecting the model with the best performance on RUTEd evaluations only as often as random chance. We conclude that evaluations that are not based in realistic use are likely insufficient to mitigate and assess bias and real-world harms.