 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOSCAR: Obstacle Survival Curves for Adaptive Robot Navigation
May 31, 2026A mobile robot following a graph of known routes can make costly navigation errors when a temporary obstacle blocks a critical edge: waiting too long behind a parked cart wastes time, but immediately rerouting around a person who would move in a few seconds is also inefficient. Standard reactive obstacle avoidance addresses local motion around obstacles, while fixed wait-or-reroute rules ignore how long different obstacle types tend to persist. We propose OSCAR: an adaptive survival-modeling framework for graph-based navigation with temporary blockages. Assuming obstacle class labels are available at encounter time, the robot learns class-conditioned residual clearance-time distributions from online experience, including right-censored observations when it reroutes before observing clearance. These survival models are integrated into a time-dependent graph planner that maintains obstacle memory and computes a patience threshold at each blocked edge: how long to wait before taking an alternate route. The method continuously updates its clearance estimates across episodes and uses them to balance waiting against rerouting. We evaluate the approach in simulation and on a real mobile robot in a university atrium with obstacles including people, chairs, bins, and tubes. In simulation, the learned policy's time-to-goal converges to within 1% of an oracle with access to ground-truth clearance distributions after fewer than 20 observations per obstacle class, outperforming all heuristic baselines. Real-world deployment confirms that the policy improves online, adapting its patience thresholds from experience across 50 navigation episodes.
Training on Thin Air: Improve Image Classification with Generated Data
May 24, 2023



Acquiring high-quality data for training discriminative models is a crucial yet challenging aspect of building effective predictive systems. In this paper, we present Diffusion Inversion, a simple yet effective method that leverages the pre-trained generative model, Stable Diffusion, to generate diverse, high-quality training data for image classification. Our approach captures the original data distribution and ensures data coverage by inverting images to the latent space of Stable Diffusion, and generates diverse novel training images by conditioning the generative model on noisy versions of these vectors. We identify three key components that allow our generated images to successfully supplant the original dataset, leading to a 2-3x enhancement in sample complexity and a 6.5x decrease in sampling time. Moreover, our approach consistently outperforms generic prompt-based steering methods and KNN retrieval baseline across a wide range of datasets. Additionally, we demonstrate the compatibility of our approach with widely-used data augmentation techniques, as well as the reliability of the generated data in supporting various neural architectures and enhancing few-shot learning.
Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
Feb 15, 2023
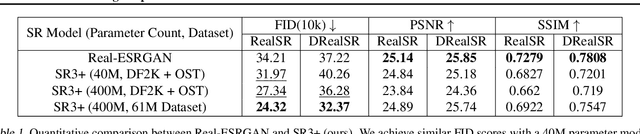
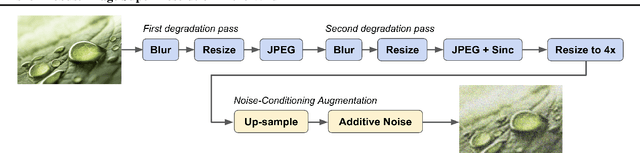
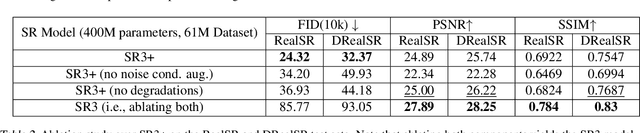
Diffusion models have shown promising results on single-image super-resolution and other image- to-image translation tasks. Despite this success, they have not outperformed state-of-the-art GAN models on the more challenging blind super-resolution task, where the input images are out of distribution, with unknown degradations. This paper introduces SR3+, a diffusion-based model for blind super-resolution, establishing a new state-of-the-art. To this end, we advocate self-supervised training with a combination of composite, parameterized degradations for self-supervised training, and noise-conditioing augmentation during training and testing. With these innovations, a large-scale convolutional architecture, and large-scale datasets, SR3+ greatly outperforms SR3. It outperforms Real-ESRGAN when trained on the same data, with a DRealSR FID score of 36.82 vs. 37.22, which further improves to FID of 32.37 with larger models, and further still with larger training sets.