 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
Paper and Code



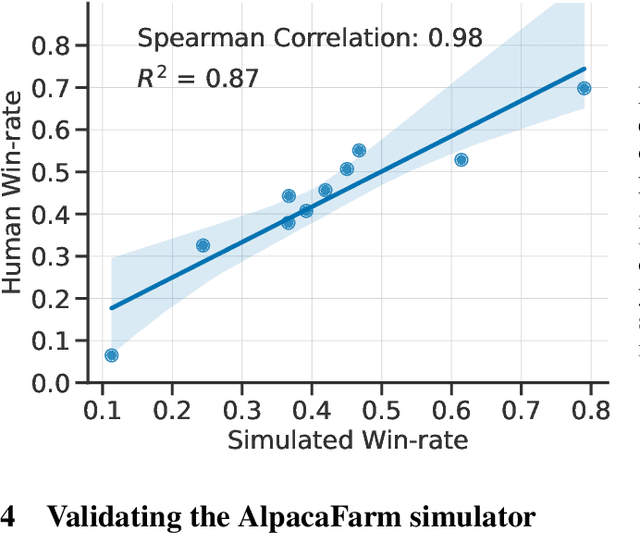
Large language models (LLMs) such as ChatGPT have seen widespread adoption due to their ability to follow user instructions well. Developing these LLMs involves a complex yet poorly understood workflow requiring training with human feedback. Replicating and understanding this instruction-following process faces three major challenges: the high cost of data collection, the lack of trustworthy evaluation, and the absence of reference method implementations. We address these challenges with AlpacaFarm, a simulator that enables research and development for learning from feedback at a low cost. First, we design LLM prompts to simulate human feedback that are 45x cheaper than crowdworkers and display high agreement with humans. Second, we propose an automatic evaluation and validate it against human instructions obtained on real-world interactions. Third, we contribute reference implementations for several methods (PPO, best-of-n, expert iteration, and more) that learn from pairwise feedback. Finally, as an end-to-end validation of AlpacaFarm, we train and evaluate eleven models on 10k pairs of real human feedback and show that rankings of models trained in AlpacaFarm match rankings of models trained on human data. As a demonstration of the research possible in AlpacaFarm, we find that methods that use a reward model can substantially improve over supervised fine-tuning and that our reference PPO implementation leads to a +10% improvement in win-rate against Davinci003. We release all components of AlpacaFarm at https://github.com/tatsu-lab/alpaca_farm.