 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Learning Easily Updated General Purpose Text Representations with Adaptable Task-Specific Prefixes
May 22, 2023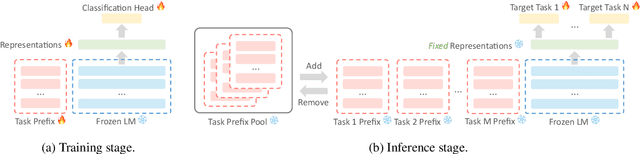


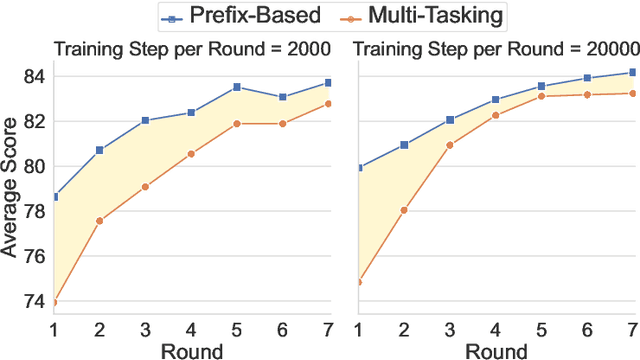
Many real-world applications require making multiple predictions from the same text. Fine-tuning a large pre-trained language model for each downstream task causes computational burdens in the inference time due to several times of forward passes. To amortize the computational cost, freezing the language model and building lightweight models for downstream tasks based on fixed text representations are common solutions. Accordingly, how to learn fixed but general text representations that can generalize well to unseen downstream tasks becomes a challenge. Previous works have shown that the generalizability of representations can be improved by fine-tuning the pre-trained language model with some source tasks in a multi-tasking way. In this work, we propose a prefix-based method to learn the fixed text representations with source tasks. We learn a task-specific prefix for each source task independently and combine them to get the final representations. Our experimental results show that prefix-based training performs better than multi-tasking training and can update the text representations at a smaller computational cost than multi-tasking training.
MLQA: Evaluating Cross-lingual Extractive Question Answering
Nov 07, 2019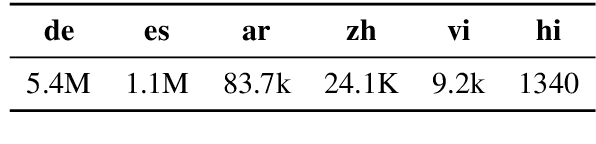
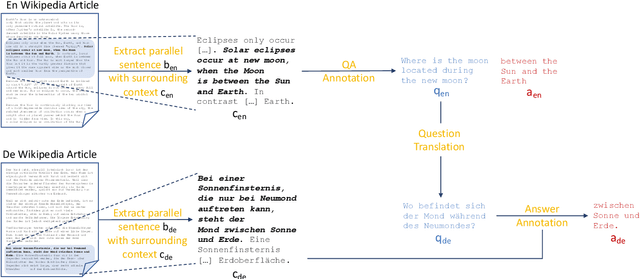
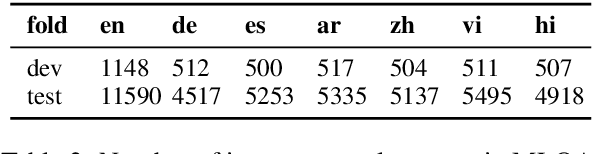
Question answering (QA) models have shown rapid progress enabled by the availability of large, high-quality benchmark datasets. Such annotated datasets are difficult and costly to collect, and rarely exist in languages other than English, making training QA systems in other languages challenging. An alternative to building large monolingual training datasets is to develop cross-lingual systems which can transfer to a target language without requiring training data in that language. In order to develop such systems, it is crucial to invest in high quality multilingual evaluation benchmarks to measure progress. We present MLQA, a multi-way aligned extractive QA evaluation benchmark intended to spur research in this area. MLQA contains QA instances in 7 languages, namely English, Arabic, German, Spanish, Hindi, Vietnamese and Simplified Chinese. It consists of over 12K QA instances in English and 5K in each other language, with each QA instance being parallel between 4 languages on average. MLQA is built using a novel alignment context strategy on Wikipedia articles, and serves as a cross-lingual extension to existing extractive QA datasets. We evaluate current state-of-the-art cross-lingual representations on MLQA, and also provide machine-translation-based baselines. In all cases, transfer results are shown to be significantly behind training-language performance.
XNLI: Evaluating Cross-lingual Sentence Representations
Sep 13, 2018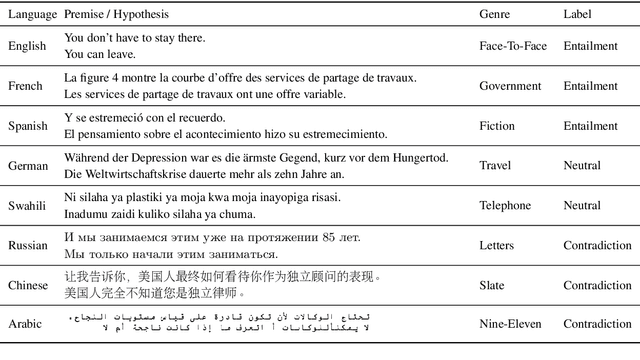
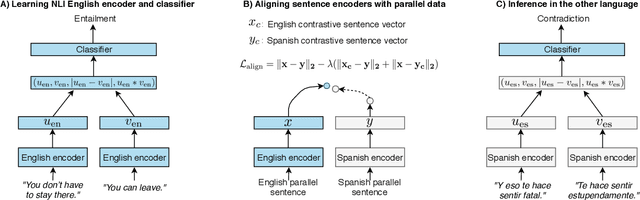

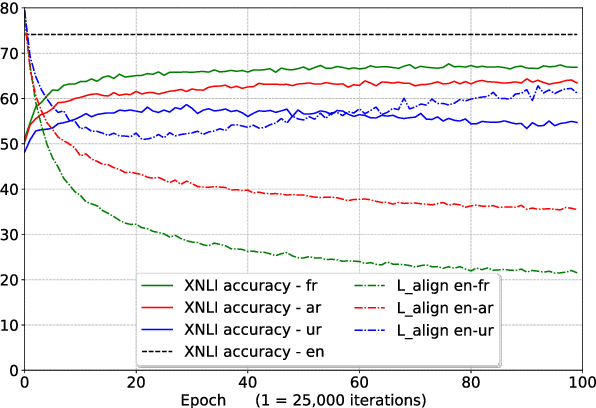
State-of-the-art natural language processing systems rely on supervision in the form of annotated data to learn competent models. These models are generally trained on data in a single language (usually English), and cannot be directly used beyond that language. Since collecting data in every language is not realistic, there has been a growing interest in cross-lingual language understanding (XLU) and low-resource cross-language transfer. In this work, we construct an evaluation set for XLU by extending the development and test sets of the Multi-Genre Natural Language Inference Corpus (MultiNLI) to 15 languages, including low-resource languages such as Swahili and Urdu. We hope that our dataset, dubbed XNLI, will catalyze research in cross-lingual sentence understanding by providing an informative standard evaluation task. In addition, we provide several baselines for multilingual sentence understanding, including two based on machine translation systems, and two that use parallel data to train aligned multilingual bag-of-words and LSTM encoders. We find that XNLI represents a practical and challenging evaluation suite, and that directly translating the test data yields the best performance among available baselines.