 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDHAGrasp: Synthesizing Affordance-Aware Dual-Hand Grasps with Text Instructions
Sep 26, 2025Learning to generate dual-hand grasps that respect object semantics is essential for robust hand-object interaction but remains largely underexplored due to dataset scarcity. Existing grasp datasets predominantly focus on single-hand interactions and contain only limited semantic part annotations. To address these challenges, we introduce a pipeline, SymOpt, that constructs a large-scale dual-hand grasp dataset by leveraging existing single-hand datasets and exploiting object and hand symmetries. Building on this, we propose a text-guided dual-hand grasp generator, DHAGrasp, that synthesizes Dual-Hand Affordance-aware Grasps for unseen objects. Our approach incorporates a novel dual-hand affordance representation and follows a two-stage design, which enables effective learning from a small set of segmented training objects while scaling to a much larger pool of unsegmented data. Extensive experiments demonstrate that our method produces diverse and semantically consistent grasps, outperforming strong baselines in both grasp quality and generalization to unseen objects. The project page is at https://quanzhou-li.github.io/DHAGrasp/.
Task-Oriented Human-Object Interactions Generation with Implicit Neural Representations
Mar 23, 2023Digital human motion synthesis is a vibrant research field with applications in movies, AR/VR, and video games. Whereas methods were proposed to generate natural and realistic human motions, most only focus on modeling humans and largely ignore object movements. Generating task-oriented human-object interaction motions in simulation is challenging. For different intents of using the objects, humans conduct various motions, which requires the human first to approach the objects and then make them move consistently with the human instead of staying still. Also, to deploy in downstream applications, the synthesized motions are desired to be flexible in length, providing options to personalize the predicted motions for various purposes. To this end, we propose TOHO: Task-Oriented Human-Object Interactions Generation with Implicit Neural Representations, which generates full human-object interaction motions to conduct specific tasks, given only the task type, the object, and a starting human status. TOHO generates human-object motions in three steps: 1) it first estimates the keyframe poses of conducting a task given the task type and object information; 2) then, it infills the keyframes and generates continuous motions; 3) finally, it applies a compact closed-form object motion estimation to generate the object motion. Our method generates continuous motions that are parameterized only by the temporal coordinate, which allows for upsampling or downsampling of the sequence to arbitrary frames and adjusting the motion speeds by designing the temporal coordinate vector. We demonstrate the effectiveness of our method, both qualitatively and quantitatively. This work takes a step further toward general human-scene interaction simulation.
Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
Jan 18, 2021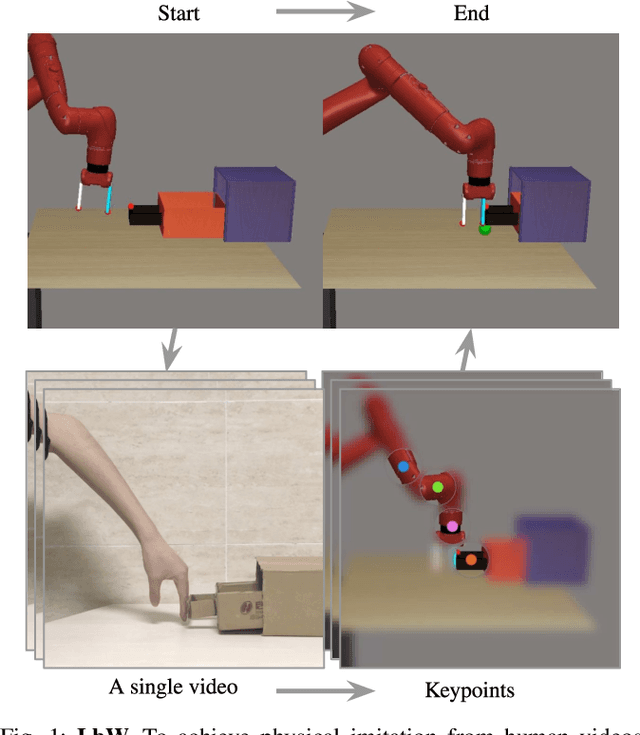
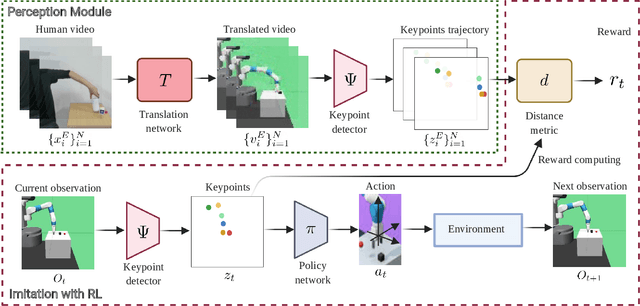
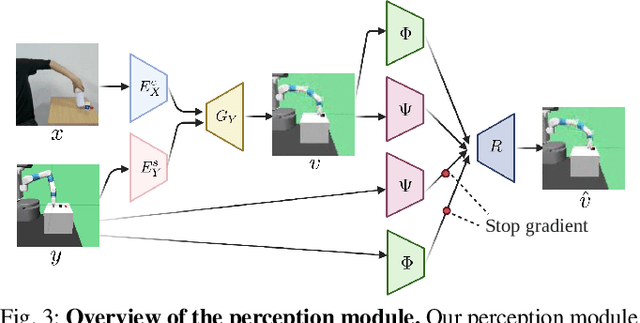

We present an approach for physical imitation from human videos for robot manipulation tasks. The key idea of our method lies in explicitly exploiting the kinematics and motion information embedded in the video to learn structured representations that endow the robot with the ability to imagine how to perform manipulation tasks in its own context. To achieve this, we design a perception module that learns to translate human videos to the robot domain followed by unsupervised keypoint detection. The resulting keypoint-based representations provide semantically meaningful information that can be directly used for reward computing and policy learning. We evaluate the effectiveness of our approach on five robot manipulation tasks, including reaching, pushing, sliding, coffee making, and drawer closing. Detailed experimental evaluations demonstrate that our method performs favorably against previous approaches.